Release 8.1.5
A67781-01
Library |
Product |
Contents |
Index |
| Oracle8i Concepts Release 8.1.5 A67781-01 |
|
![]()
![]()
Civilization advances by extending the number of important operations which we can perform without thinking about them.
Alfred North Whitehead: An Introduction to Mathematics
This chapter describes the parallel execution of SQL statements. The topics in this chapter include:
The parallel execution features described in this chapter are available only if you have purchased the Oracle8i Enterprise Edition. See Getting to Know Oracle8i for information about Oracle8i Enterprise Edition. Also, parallel execution is not the same as the Oracle Parallel Server. You do not need the Parallel Server Option to perform parallel execution of SQL statements; however, some aspects of parallel execution apply only to the Oracle Parallel Server.
Attention:
When Oracle is not parallelizing the execution of SQL statements, each SQL statement is executed sequentially by a single process. With parallel execution, however, multiple processes work together simultaneously to execute a single SQL statement. By dividing the work necessary to execute a statement among multiple processes, Oracle can execute the statement more quickly than if only a single process executed it.
Parallel execution can dramatically improve performance for data-intensive operations associated with decision support applications or very large database environments. Symmetric multiprocessing (SMP), clustered systems, and massively parallel systems (MPP) gain the largest performance benefits from parallel execution because statement processing can be split up among many CPUs on a single Oracle system.
Parallel execution helps systems scale in performance by making optimal use of hardware resources. If your system's CPUs and disk controllers are already heavily loaded, you need to alleviate the system's load or increase these hardware resources before using parallel execution to improve performance.
|
Additional Information:
See Oracle8i Tuning for specific information on tuning your parameter files and database to take full advantage of parallel execution. |
The Oracle server can use parallel execution for any of these operations:
A SELECT statement consists of a query only. A DML or DDL statement usually consists of a query portion and a DML or DDL portion, each of which can be parallelized.
Oracle primarily parallelizes SQL statements in the following ways:
Oracle parallelizes a query dynamically at execution time. Dynamic parallelism divides the table or index into ranges of database blocks (rowid range) and executes the operation in parallel on different ranges. If the distribution or location of data changes, Oracle automatically adapts to optimize the parallelization for each execution of the query portion of a SQL statement.
Parallel scans by block range break the table or index into pieces delimited by high and low rowid values. The table or index can be nonpartitioned or partitioned.
For partitioned tables and indexes, no rowid range can span a partition although one partition can contain multiple rowid ranges. Oracle sends the partition numbers with the rowid ranges to avoid partition map lookup. Compile and run-time predicates on partitioning columns restrict the rowid ranges to relevant partitions, eliminating unnecessary partition scans (partition pruning).
This means that a parallel query which accesses a partitioned table by a table scan performs the same or less overall work as the same query on a nonpartitioned table. The query on the partitioned table executes with equivalent parallelism, although the total number of disks accessed might be reduced by the partition pruning.
Oracle can parallelize the following operations on tables and indexes by block range (rowid range):
Partitions are a logical static division of tables and indexes which can be used to break some long-running operations into smaller operations executed in parallel on individual partitions. The granule of parallelism is a partition; there is no parallelism within a partition except for:
Operations on partitioned tables and indexes are performed in parallel by assigning different parallel execution servers to different partitions of the table or index. Compile and run-time predicates restrict the partitions when the operation references partitioning columns (partition pruning). The operation executes serially when compile or run-time predicates restrict the operation to a single partition.
The parallel operation may use fewer parallel execution servers than the number of accessed partitions (because of resource limits, hints, or table attributes), but each partition is accessed by a single parallel execution server. A parallel execution server, however, can access multiple partitions.
Operations on partitioned tables and indexes are performed in parallel only when more than one partition is accessed.
Oracle can parallelize the following operations on partitioned tables and indexes by partition:
For nonpartitioned tables only, Oracle parallelizes insert operations by dividing the work among parallel execution servers. Since new rows do not have rowids, the rows are distributed among the parallel execution servers to insert them into the free space.
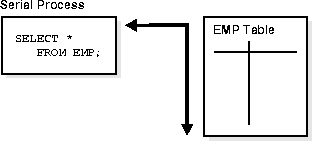
When parallel execution is not being used, a single server process performs all necessary processing for the sequential execution of a SQL statement. For example, to perform a full table scan (such as SELECT * FROM EMP), one process performs the entire operation, as illustrated in Figure 26-1.
Parallel execution performs these operations in parallel using multiple parallel processes. One process, known as the parallel execution coordinator, dispatches the execution of a statement to several parallel execution servers and coordinates the results from all of the server processes to send the results back to the user.
When an operation is divided into pieces for parallel execution in a massively parallel processing (MPP) configuration, Oracle assigns a particular piece of the operation to a parallel execution server by taking into account the affinity of the process for the piece of the table or index to be used for the operation. The physical layout of partitioned tables and indexes impacts on the affinity used to assign work for parallel execution servers. See "Affinity" for more information.
Figure 26-2 illustrates several parallel execution servers simultaneously performing a partial scan of the EMP table, which is divided by block range dynamically (dynamic partitioning). The parallel execution servers send results back to the parallel execution coordinator, which assembles the pieces into the desired full table scan.
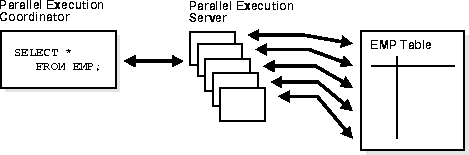
The parallel execution coordinator breaks down execution functions into parallel pieces and then integrates the partial results produced by the parallel execution servers. The number of parallel execution servers assigned to a single operation is the degree of parallelism (DOP) for an operation. Multiple operations within the same SQL statement all have the same degree of parallelism (see "How Oracle Determines the Degree of Parallelism for Operations").
When an instance starts up, Oracle creates a pool of parallel execution servers which are available for any parallel operation. The initialization parameter PARALLEL_MIN_SERVERS specifies the number of parallel execution servers that Oracle creates at instance startup.
When executing a parallel operation, the parallel execution coordinator obtains parallel execution servers from the pool and assigns them to the operation. If necessary, Oracle can create additional parallel execution servers for the operation. These parallel execution servers remain with the operation throughout job execution, then become available for other operations. After the statement has been processed completely, the parallel execution servers return to the pool.
When a user issues a SQL statement, the optimizer decides whether to execute the operations in parallel and determines the degree of parallelism for each operation. You can specify the number of parallel execution servers required for an operation in various ways (see "Setting the Degree of Parallelism").
If the optimizer targets the statement for parallel processing, the following sequence of events takes place:
The parallel execution coordinator calls upon the parallel execution servers during the execution of the SQL statement (not during the parsing of the statement). Therefore, when parallel execution is used with the multi-threaded server, the server process that processes the EXECUTE call of a user's statement becomes the parallel execution coordinator for the statement.
If the number of parallel operations processed concurrently by an instance changes significantly, Oracle automatically changes the number of parallel execution servers in the pool.
If the number of parallel operations increases, Oracle creates additional parallel execution servers to handle incoming requests. However, Oracle never creates more parallel execution servers for an instance than what is specified by the initialization parameter PARALLEL_MAX_SERVERS.
If the number of parallel operations decreases, Oracle terminates any parallel execution servers that have been idle for a threshold period of time. Oracle does not reduce the size of the pool below the value of PARALLEL_MIN_SERVERS no matter how long the parallel execution servers have been idle.
Oracle can process a parallel operation with fewer than the requested number of processes; see "Minimum Number of Parallel Execution Servers" for information about specifying a minimum with the initialization parameter PARALLEL_MIN_PERCENT.
If all parallel execution servers in the pool are occupied and the maximum number of parallel execution servers has been started, the parallel execution coordinator switches to serial processing.
|
Additional Information:
See Oracle8i Tuning for information about monitoring an instance's pool of parallel execution servers and determining the appropriate values of the initialization parameters. |
To execute a query in parallel, Oracle generally creates a producer queue server and a consumer server. The producer queue server retrieves rows from tables and the consumer server performs operations (for example, join, sort, DML, DDL, and so on) on these rows. Each server in the producer execution process set has a connection to each server in the consumer set. This means that the number of virtual connections between parallel execution servers increases as the square of the degree of parallelism.
Each communication channel has at least 1, and sometimes up to 4 memory buffers. Multiple memory buffers facilitate asynchronous communication among the parallel execution servers.
A single-instance environment uses at most 3 buffers per communication channel. An OPS environment uses at most 4 buffers per channel. Figure 26-3 illustrates message buffers and how producer parallel execution servers connect to consumer parallel execution servers.
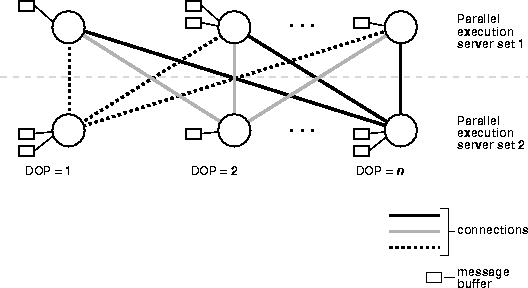
When a connection is between two processes on the same instance, the servers communicate by passing the buffers back and forth. When the connection is between processes in different instances, the messages are sent using external high-speed network protocols. In Figure 26-3, the DOP is equal to the number of parallel execution servers, which in this case is "n". Figure 26-3 does not show the parallel execution coordinator: each parallel execution server actually has an additional connection to the parallel execution coordinator.
Each SQL statement undergoes an optimization and parallelization process when it is parsed. Therefore, when the data changes, if a more optimal execution plan or parallelization plan becomes available, Oracle can automatically adapt to the new situation. (Optimization is discussed in Chapter 22, "The Optimizer".)
After the optimizer determines the execution plan of a statement, the parallel execution coordinator determines the parallelization method for each operation in the execution plan (for example, parallelize a full table scan by block range or parallelize an index range scan by partition). The coordinator must decide whether an operation can be performed in parallel and, if so, how many parallel execution servers to enlist (that is, the degree of parallelism).
See "Setting the Degree of Parallelism" and "Parallelization Rules for SQL Statements" for more information.
The parallel execution coordinator examines the redistribution requirements of each operation. An operation's redistribution requirement is the way in which the rows operated on by the operation must be divided, or redistributed, among the parallel execution servers.
After determining the redistribution requirement for each operation in the execution plan, the optimizer determines the order in which the operations in the execution plan must be performed. With this information, the optimizer determines the data flow of the statement.
Figure 26-4 illustrates the data flow of the following query:
SELECT dname, MAX(sal), AVG(sal) FROM emp, dept WHERE emp.deptno = dept.deptno GROUP BY dname;
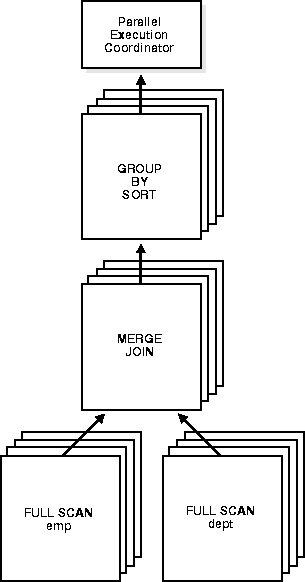
Operations that require the output of other operations are known as parent operations. In Figure 26-4 the GROUP BY SORT operation is the parent of the MERGE JOIN operation because GROUP BY SORT requires the MERGE JOIN output.
Parent operations can begin consuming rows as soon as the child operations have produced rows. In the previous example, while the parallel execution servers are producing rows in the FULL SCAN DEPT operation, another set of parallel execution servers can begin to perform the MERGE JOIN operation to consume the rows.
Each of the two operations performed concurrently is given its own set of parallel execution servers. Therefore, both query operations and the data flow tree itself have parallelism. The parallelism of an individual operation is called intra-operation parallelism and the parallelism between operations in a data flow tree is called inter-operation parallelism.
Due to the producer/consumer nature of the Oracle server's operations, only two operations in a given tree need to be performed simultaneously to minimize execution time.
To illustrate intra-operation parallelism and inter-operator parallelism, consider the following statement:
SELECT * FROM emp ORDER BY ename;
The execution plan consists of a full scan of the EMP table followed by a sorting of the retrieved rows based on the value of the ENAME column. For the sake of this example, assume the ENAME column is not indexed. Also assume that the degree of parallelism for the query is set to four, which means that four parallel execution servers can be active for any given operation.
Figure 26-5 illustrates the parallel execution of our example query.
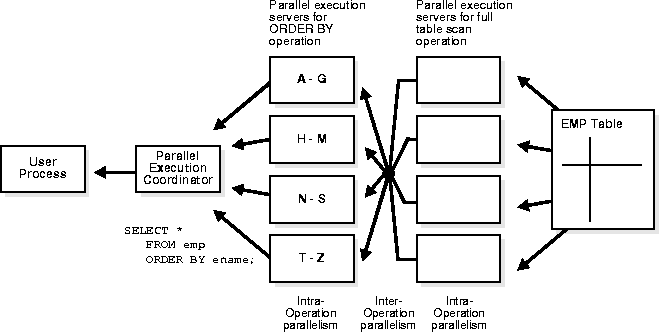
As you can see from Figure 26-5, there are actually eight parallel execution servers involved in the query even though the degree of parallelism is four. This is because a parent and child operator can be performed at the same time (inter-operation parallelism).
Also note that all of the parallel execution servers involved in the scan operation send rows to the appropriate parallel execution server performing the sort operation. If a row scanned by a parallel execution server contains a value for the ENAME column between A and G, that row gets sent to the first ORDER BY parallel execution server. When the scan operation is complete, the sorting processes can return the sorted results to the coordinator, which in turn returns the complete query results to the user.
The parallel execution coordinator may enlist two or more of the instance's parallel execution servers to process a SQL statement. The number of parallel execution servers associated with a single operation is known as the degree of parallelism (DOP).
The degree of parallelism is specified at the statement level (with hints or the PARALLEL clause), at the table or index level (in the table's or index's definition), or by default based on the number of CPUs.
The following example shows a statement that sets the degree of parallelism to 4 on a table:
ALTER TABLE emp PARALLEL 4;
This next example sets the degree of parallelism on an index:
ALTER INDEX iemp PARALLEL;
This last example sets a hint to 4 on a query:
SELECT /*+ PARALLEL(emp,4) */ COUNT(*) FROM emp ;
|
Additional Information:
See Oracle8i Reference and Oracle8i Tuning for information about the syntax of these statements. |
Note that the degree of parallelism applies directly only to intra-operation parallelism. If inter-operation parallelism is possible, the total number of parallel execution servers for a statement can be twice the specified degree of parallelism. No more than two operations can be performed simultaneously.
Parallel execution is designed to effectively use multiple CPUs and disks to answer queries quickly. When multiple users use parallel execution at the same time, it is easy to quickly exhaust available CPU, memory, and disk resources. Oracle provides several ways to deal with resource utilization in conjunction with parallel execution, including:
Refer to the Oracle8i SQL Reference for the syntax of the ALTER SYSTEM SQL statement.
Additional Information:
The parallel execution coordinator determines the degree of parallelism by considering several specifications. The coordinator:
Once a degree of parallelism is found in one of these specifications, it becomes the degree of parallelism for the operation. For specific details of the degree of parallelism, see "Parallelization Rules for SQL Statements".
Hints, PARALLEL clauses, table or index definitions, and default values only determine the number of parallel execution servers that the coordinator requests for a given operation. The actual number of parallel execution servers uses depends upon how many processes are available in the parallel execution server pool (see "The Parallel Execution Server Pool") and whether inter-operation parallelism is possible (see "Parallelism Between Operations").
You can specify hints in a SQL statement to set the degree of parallelism for a table or index and the caching behavior of the operation.
Refer to Oracle8i Tuning for a general discussion on using hints in SQL statements and the specific syntax for the PARALLEL, NOPARALLEL, PARALLEL_INDEX, CACHE, and NOCACHE hints.
Additional Information:
You can specify the degree of parallelism within a table or index definition. Use one of the following SQL statements to set the degree of parallelism for a table or index: CREATE TABLE, ALTER TABLE, CREATE INDEX, or ALTER INDEX.
|
Additional Information:
Refer to the Oracle8i SQL Reference for the complete syntax of SQL statements. |
The default degree of parallelism is used when you ask to parallelize an operation but you do not specify a degree of parallelism in a hint or within the definition of a table or index. The default degree of parallelism is appropriate for most applications.
|
Additional Information:
See Oracle8i Tuning for information about adjusting the degree of parallelism. |
The default degree of parallelism for a SQL statement is determined by the following factors.
The above factors determine the default number of parallel execution servers to use, however, the actual number of processes used is limited by their availability on the requested instances during run time. The initialization parameter PARALLEL_MAX_SERVERS sets an upper limit on the total number of parallel execution servers that an instance can have.
If a minimum fraction of the desired parallel execution servers is not available (specified by the initialization parameter PARALLEL_MIN_PERCENT), a user error is produced. The user can then retry the query with less parallelism.
When the adaptive multi-user algorithm is enabled, the parallel execution coordinator varies the degree of parallelism according to the system load. The load is determined by looking at the number of allocated threads, as calculated by the Database Resource Manager. If the number of threads currently allocated is larger than the optimal number of threads, given the number of available CPUs, the algorithm reduces the degree of parallelism. This reduction improves throughput by avoiding overallocation of resources.
Oracle can perform an operation in parallel as long as at least two parallel execution servers are available. If too few parallel execution servers are available, your SQL statement may execute slower than expected. You can specify that a minimum percentage of requested parallel execution servers must be available in order for the operation to execute. This ensures that your SQL statement executes with a minimum acceptable parallel performance. If the minimum percentage of requested parallel execution servers are not available, the SQL statement does not execute and returns an error.
The initialization parameter PARALLEL_MIN_PERCENT specifies the desired minimum percentage of requested parallel execution servers. This parameter affects DML and DDL operations as well as queries.
For example, if you specify 50 for this parameter, then at least 50% of the parallel execution servers requested for any parallel operation must be available in order for the operation to succeed. If 20 parallel execution servers are requested, then at least 10 must be available or an error is returned to the user. If PARALLEL_MIN_PERCENT is set to null, then all parallel operations will proceed as long as at least two parallel execution servers are available for processing.
In an Oracle Parallel Server, instance groups can be used to limit the number of instances that participate in a parallel operation. You can create any number of instance groups, each consisting of one or more instances. You can then specify which instance group is to be used for any or all parallel operations. Parallel execution servers will only be used on instances which are members of the specified instance group.
|
Additional Information:
See Oracle8i Parallel Server Concepts and Administration for more information about instance groups. |
To optimize performance, all parallel execution servers should have equal work loads. For SQL statements parallelized by block range or by parallel execution servers, the work load is dynamically divided among the parallel execution servers. This minimizes workload skewing, which occurs when some parallel execution servers perform significantly more work than the other processes.
For SQL statements parallelized by partitions, if the work load is evenly distributed among the partitions then you can optimize performance by matching the number of parallel execution servers to the number of partitions, or by choosing a degree of parallelism such that the number of partitions is a multiple of the number of processes.
For example, if a table has ten partitions and a parallel operation divides the work evenly among them, you can use ten parallel execution servers (degree of parallelism = 10) to do the work in approximately one-tenth the time that one process would take, or you can use five processes to do the work in one-fifth the time, or two processes to do the work in one-half the time.
If, however, you use nine processes to work on ten partitions, the first process to finish its work on one partition then begins work on the tenth partition; and as the other processes finish their work they become idle. This does not give good performance when the work is evenly divided among partitions. When the work is unevenly divided, the performance varies depending on whether the partition that is left for last has more or less work than the other partitions.
Similarly, if you use four processes to work on ten partitions and the work is evenly divided, then each process works on a second partition after finishing its first partition, but only two of the processes work on a third partition while the other two remain idle.
In general, you cannot assume that the time taken to perform a parallel operation on N partitions with P parallel execution servers will be N/P, because of the possibility that some processes might have to wait while others finish working on the last partition(s). By choosing an appropriate degree of parallelism, however, you can minimize the workload skewing and optimize performance.
For information about balancing the work load with disk affinity, see "Affinity and Parallel DML".
A SQL statement can be parallelized if it includes a parallel hint or if the table or index being operated on has been declared PARALLEL with a CREATE or ALTER statement. In addition, a data definition language (DDL) statement can be parallelized by using the PARALLEL clause. However, not all of these methods apply to all types of SQL statements.
Parallelization has two components: the decision to parallelize and the degree of parallelism. These components are determined differently for queries, DDL operations, and DML operations.
To determine the degree of parallelism, Oracle looks at the reference objects.
A SELECT statement can be parallelized only if the following conditions are satisfied:
The degree of parallelism for a query is determined by the following rules:
Update and delete operations are parallelized by partition (or subpartition--see "Composite Partitioning"). Updates and deletes can only be parallelized on partitioned tables; update/delete parallelism is not possible within a partition, nor on a nonpartitioned table.
You have two ways to specify parallel directives for UPDATE and DELETE operations (assuming that PARALLEL DML mode is enabled):
Parallel hints are placed immediately after the UPDATE or DELETE keywords in UPDATE and DELETE statements. The hint also applies to the underlying scan of the table being changed.
Parallel clauses in CREATE TABLE and ALTER TABLE commands specify table parallelism. If a parallel clause exists in a table definition, it determines the parallelism of DML statements as well as queries. If the DML statement contains explicit parallel hints for a table, however, then those hints override the effect of parallel clauses for that table.
You can use the ALTER SESSION FORCE PARALLEL DML statement to override parallel clauses for subsequent update and delete statements in a session. Parallel hints in update and delete statements override the ALTER SESSION FORCE PARALLEL DML statement.
The following rule determines whether the update/delete operation should be parallelized in an update/delete statement:
If the statement contains subqueries or updatable views, they may have their own separate parallel hints or clauses, but these parallel directives do not affect the decision to parallelize the update or delete.
Although the parallel hint or clause on the tables is used by both query and update/delete portions to determine parallelism, the decision to parallelize the update/delete portion is made independently of the query portion, and vice versa.
The degree of parallelism is determined by the same rules as for the queries. Note that in the case of update and delete operations, only one table (the only reference object) is involved which is the target table to be modified.
The precedence rule to determine the degree of parallelism for the update/delete operation is that the update or delete parallel hint specification takes precedence over the parallel declaration specification of the target table:
The maximum degree of parallelism you can achieve is equal to the number of partitions (or subpartitions in the case of composite subpartitions) in the table. A parallel execution server can update into or delete from multiple partitions, but each partition can only be updated or deleted by one parallel execution server.
If the degree of parallelism is less than the number of partitions, then the first process to finish work on one partition continues working on another partition, and so on until the work is finished on all partitions. If the degree of parallelism is greater than the number of partitions involved in the operation, then the excess parallel execution servers would have no work to do.
UPDATE tbl_1 SET c1=c1+1 WHERE c1>100;
If TBL_1 is a partitioned table and its table definition has a parallel clause, then the update operation will be parallelized even if the scan on the table is serial (such as an index scan), assuming that the table has more than one partition with C1 greater than 100.
UPDATE /*+ PARALLEL(tbl_2,4) */ tbl_2 SET c1=c1+1;
Both the scan and update operations on TBL_2 will be parallelized with degree 4.
An INSERT ... SELECT statement parallelizes its INSERT and SELECT operations independently, except for the degree of parallelism.
You can specify a "parallel" hint after the INSERT keyword in an INSERT ... SELECT statement. Since the tables being queried are usually not the same as the table being inserted into, the hint allows you to specify parallel directives specifically for the insert operation.
You have four ways to specify parallel directives for an INSERT... SELECT statement (assuming that PARALLEL DML mode is enabled):
You can use the ALTER SESSION FORCE PARALLEL DML statement to override parallel clauses for subsequent insert operations in a session. Parallel hints in insert operations override the ALTER SESSION FORCE PARALLEL DML statement.
The following rule determines whether the insert operation should be parallelized in an INSERT... SELECT statement:
Hence the decision to parallelize the insert operation is made independently of the select operation, and vice versa.
Once the decision to parallelize the select and/or insert operation is made, one parallel directive is picked for deciding degree of parallelism of the whole statement using the following precedence rule:
Insert Hint directive > Parallel declaration specification of the inserting table > Maximum Query directive
where Maximum Query directive means that among multiple tables and indexes, the table or index that has the maximum degree of parallelism determines the parallelism for the query operation.
The chosen parallel directive is applied to both the select and insert operations.
In the following example, the degree of parallelism used will be 2, which is the degree specified in the Insert hint:
INSERT /*+ PARALLEL(tbl_ins,2) */ INTO tbl_ins SELECT /*+ PARALLEL(tbl_sel,4) */ * FROM tbl_sel;
DDL operations can be parallelized if a PARALLEL clause (declaration) is specified in the syntax. In the case of CREATE INDEX and ALTER INDEX ... REBUILD or ALTER INDEX ... REBUILD PARTITION, the parallel declaration is stored in the data dictionary.
You can use the ALTER SESSION FORCE PARALLEL DDL statement to override the parallel clauses of subsequent DDL statements in a session.
The degree of parallelism is determined by the specification in the PARALLEL clause, unless it is overridden by an ALTER SESSION FORCE PARALLEL DDL statement. A rebuild of a partitioned index is never parallelized.
The CREATE INDEX and ALTER INDEX ... REBUILD statements can be parallelized only by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement.
ALTER INDEX ... REBUILD can be parallelized only for a nonpartitioned index, but ALTER INDEX ... REBUILD PARTITION can be parallelized by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement.
The scan operation for ALTER INDEX ... REBUILD (nonpartitioned), ALTER INDEX ... REBUILD PARTITION, and CREATE INDEX has the same parallelism as the REBUILD or CREATE operation and uses the same degree of parallelism. If the degree of parallelism is not specified for REBUILD or CREATE, the default is the number of CPUs.
The ALTER INDEX ... MOVE PARTITION and ALTER INDEX ... SPLIT PARTITION statements can be parallelized only by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement. Their scan operations have the same parallelism as the corresponding MOVE or SPLIT operations. If the degree of parallelism is not specified, the default is the number of CPUs.
The CREATE TABLE ... AS SELECT statement contains two parts: a CREATE part (DDL) and a SELECT part (query). Oracle can parallelize both parts of the statement. The CREATE part follows the same rules as other DDL operations.
The query part of a CREATE TABLE ... AS SELECT statement can be parallelized only if the following conditions are satisfied:
The degree of parallelism for the query part of a CREATE TABLE ... AS SELECT statement is determined by one of these rules:
Note that any values specified in a hint for parallelism will be ignored.
The CREATE operation of CREATE TABLE ... AS SELECT can be parallelized only by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement.
When the CREATE operation of CREATE TABLE ... AS SELECT is parallelized, Oracle also parallelizes the scan operation if possible. The scan operation cannot be parallelized if, for example:
When the CREATE operation is not parallelized, the SELECT can be parallelized if it has a PARALLEL hint or if the selected table (or partitioned index) has a parallel declaration.
The degree of parallelism for the CREATE operation, and for the SELECT operation if it is parallelized, is specified by the PARALLEL clause of the CREATE statement, unless it is overridden by an ALTER SESSION FORCE PARALLEL DDL statement. If the PARALLEL clause does not specify the degree of parallelism, the default is the number of CPUs.
Table 26-1 shows how various types of SQL statements can be parallelized, and indicates which methods of specifying parallelism take precedence.
For details about parallel clauses and hints in SQL statements, see Oracle8i SQL Reference.
Additional Information:
Table 26-1 Parallelization Rules
You can parallelize queries and subqueries in SELECT statements, as well as the query portions of DDL statements and DML statements (INSERT, UPDATE, and DELETE). Previous sections in this chapter describe how queries are parallelized:
However, you cannot parallelize the query portion of a DDL or DML statement if it references a remote object. When you issue a parallel DML or DDL statement in which the query portion references a remote object, the operation is executed serially without notification. See "Distributed Transaction Restrictions" for examples.
The following parallel scan methods are supported on index-organized tables:
These scan methods can be used for index-organized tables with overflow areas and index-organized tables that contain LOBs.
Parallel query on a nonpartitioned index-organized table uses parallel fast full scan. The degree of parallelism is determined, in decreasing order of priority, by: the PARALLEL hint (if present), the parallel degree associated with the table (if specified in the CREATE TABLE or ALTER TABLE command).
The allocation of work is done by dividing the index segment into a sufficiently large number of block ranges and then assigning block ranges to parallel execution servers in a demand-driven manner. The overflow blocks corresponding to any row are accessed in a demand-driven manner only by the process which owns that row.
Both index range scan and fast full scan can be performed in parallel. For parallel fast full scan, parallelization is exactly the same as for nonpartitioned index-organized tables. For parallel index range scan on partitioned index-organized tables, the degree of parallelism is the minimum of the degree picked up from the above priority list (like in parallel fast full scan) and the number of partitions in the index-organized table. Depending on the degree of parallelism, each parallel execution server gets one or more partitions (assigned in a demand-driven manner), each of which contains the primary key index segment and the associated overflow segment, if any.
Parallel queries can be performed on object type tables and tables containing object type columns. Parallel query for object types supports all of the features that are available for sequential queries on object types, including:
There are no limitations on the size of the object types for parallel queries.
The following restrictions apply to using parallel query for object types.
In all cases where the query cannot execute in parallel because of any of the above restrictions, the whole query executes serially without giving an error message.
This section includes the following topics on parallelism for data definition language (DDL) statements:
You can parallelize DDL statements for tables and indexes that are nonpartitioned or partitioned. Table 26-1 summarizes the operations that can be parallelized in DDL statements.
The parallel DDL statements for nonpartitioned tables and indexes are:
The parallel DDL statements for partitioned tables and indexes are:
All of these DDL operations can be performed in no-logging mode (see "Logging Mode") for either parallel or serial execution.
CREATE TABLE for an index-organized table can be parallelized either with or without an AS SELECT clause.
Different parallelism is used for different operations (see Table 26-1). Parallel create (partitioned) table as select and parallel create (partitioned) index execute with a degree of parallelism equal to the number of partitions.
Partition parallel analyze table is made less necessary by the ANALYZE {TABLE, INDEX} PARTITION commands, since parallel analyze of an entire partitioned table can be constructed with multiple user sessions.
Parallel DDL cannot occur on tables with object columns or LOB columns.
Decision support applications, for performance reasons, often require large amounts of data to be summarized or "rolled up" into smaller tables for use with ad hoc, decision support queries. Rollup occurs regularly (such as nightly or weekly) during a short period of system inactivity.
Parallel execution allows you to parallelize the query and create operations of creating a table as a subquery from another table or set of tables.
Figure 26-6 illustrates creating a table from a subquery in parallel.
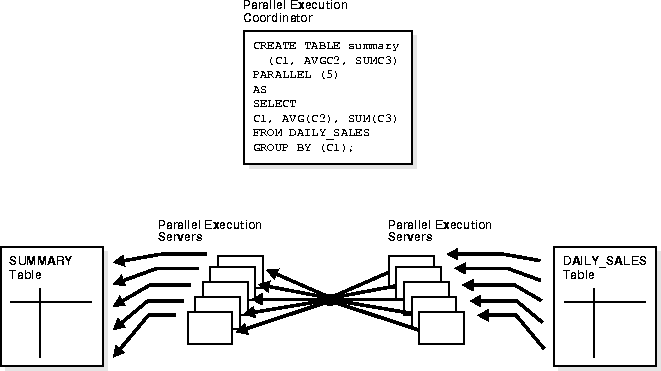
When summary table data is derived from other tables' data, the recoverability from media failure for the smaller summary table may not be important and can be turned off during creation of the summary table.
If you disable logging during parallel table creation (or any other parallel DDL operation), you should take a backup of the tablespace containing the table once the table is created to avoid loss of the table due to media failure.
Use the NOLOGGING clause of CREATE/ALTER TABLE/INDEX statements to disable undo and redo log generation. See "Logging Mode" for more information.
|
Additional Information:
See the Oracle8i Administrator's Guide for information about recoverability of tables created in parallel. |
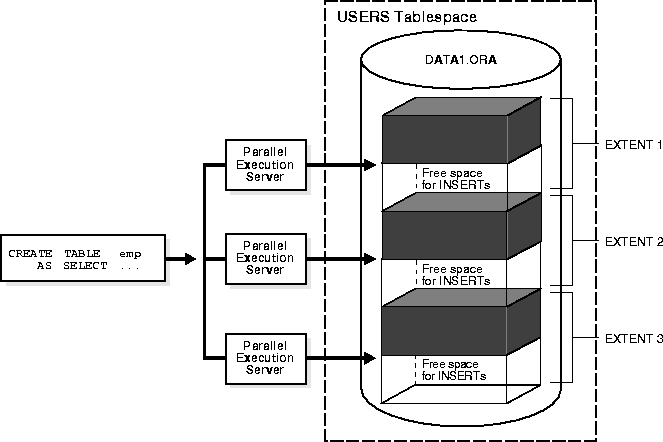
Creating a table or index in parallel has space management implications that affect both the storage space required during the parallel operation and the free space available after the table or index has been created.
When creating a table or index in parallel, each parallel execution server uses the values in the STORAGE clause of the CREATE statement to create temporary segments to store the rows. Therefore, a table created with an INITIAL of 5M and a PARALLEL DEGREE of 12 consumes at least 60 megabytes (MB) of storage during table creation, because each process starts with an extent of 5 MB. When the parallel execution coordinator combines the segments, some of the segments may be trimmed, and the resulting table may be smaller than the requested 60 MB.
|
Additional Information:
See the Oracle8i SQL Reference for a discussion of the syntax of the CREATE TABLE command. |
When you create indexes and tables in parallel, each parallel execution server allocates a new extent and fills the extent with the table or index's data. Thus, if you create an index with a degree of parallelism of 3, there will be at least three extents for that index initially. (This discussion also applies to rebuilding indexes in parallel and moving, splitting, or rebuilding partitions in parallel.)
Serial operations require the schema object to have at least one extent. Parallel creations require that tables or indexes have at least as many extents as there are parallel execution servers creating the schema object.
When you create a table or index in parallel, it is possible to create "pockets" of free space--either external or internal fragmentation. This occurs when the temporary segments used by the parallel execution servers are larger than what is needed to store the rows.
For example, if you specify a degree of parallelism of three for a CREATE TABLE ... AS SELECT statement but there is only one datafile in the tablespace, the internal fragmentation illustrated in Figure 26-7 can arise. The "pockets" of free space within internal table extents of a datafile cannot be coalesced with other free space and allocated as extents. For more information about coalescing free space, see Chapter 3, "Tablespaces and Datafiles".
|
Additional Information:
See Oracle8i Tuning for more information about creating tables and indexes in parallel. |
Parallel DML (parallel insert, update, and delete) uses parallel execution mechanisms to speed up or scale up large DML operations against large database tables and indexes.
This section discusses the following parallel DML topics:
See Chapter 25, "Direct-Load INSERT" for a detailed description of parallel insert statements.
You can parallelize DML operations manually by issuing multiple DML commands simultaneously against different sets of data. For example, you can parallelize manually by:
However, manual parallelism has the following disadvantages:
Parallel DML removes these disadvantages by performing inserts, updates, and deletes in parallel automatically.
Parallel DML operations are mainly used to speed up large DML operations against large database objects. Parallel DML is useful in a decision support system (DSS) environment where the performance and scalability of accessing large objects are important. Parallel DML complements parallel query in providing you with both querying and updating capabilities for your DSS databases.
The overhead of setting up parallelism makes parallel DML operations infeasible for short OLTP transactions. However, parallel DML operations can speed up batch jobs running in an OLTP database.
In a data warehouse system, large tables need to be refreshed (updated) periodically with new or modified data from the production system. You can do this efficiently by using parallel DML combined with updatable join views.
The data that needs to be refreshed is generally loaded into a temporary table before starting the refresh process. This table contains either new rows or rows that have been updated since the last refresh of the data warehouse. You can use an updatable join view with parallel UPDATE to refresh the updated rows, and you can use an anti-hash join with parallel INSERT to refresh the new rows.
In a DSS environment, many applications require complex computations that involve constructing and manipulating many large intermediate summary tables. These summary tables are often temporary and frequently do not need to be logged. Parallel DML can speed up the operations against these large intermediate tables. One benefit is that you can put incremental results in the intermediate tables and perform parallel UPDATEs.
In addition, the summary tables may contain cumulative or comparison information which has to persist beyond application sessions; thus, temporary tables are not feasible. Parallel DML operations can speed up the changes to these large summary tables.
Many DSS applications score customers periodically based on a set of criteria. The scores are usually stored in large DSS tables. The score information is then used in making a decision, for example, inclusion in a mailing list.
This scoring activity queries and updates a large number of rows in the large table. Parallel DML can speed up the operations against these large tables.
Historical tables describe the business transactions of an enterprise over a recent time interval. Periodically, the DBA deletes the set of oldest rows and inserts a set of new rows into the table. Parallel INSERT... SELECT and parallel DELETE operations can speed up this rollover task.
Although you can also use parallel direct loader (SQL*Loader) to insert bulk data from an external source, parallel INSERT... SELECT will be faster in inserting data that already exists in another table in the database.
Dropping a partition can also be used to delete old rows, but to do this, the table has to be partitioned by date and with the appropriate time interval.
Batch jobs executed in an OLTP database during off hours have a fixed time window in which the jobs must complete. A good way to ensure timely job completion is to parallelize their operations. As the work load increases, more machine resources can be added; the scaleup property of parallel operations ensures that the time constraint can be met.
A DML statement can be parallelized only if you have explicitly enabled parallel DML in the session via the ENABLE PARALLEL DML option of the ALTER SESSION statement. This mode is required because parallel DML and serial DML have different locking, transaction, and disk space requirements. (See "Space Considerations for Parallel DML" and "Lock and Enqueue Resources for Parallel DML".)
The default mode of a session is DISABLE PARALLEL DML. When PARALLEL DML is disabled, no DML will be executed in parallel even if the PARALLEL hint or PARALLEL clause is used.
When PARALLEL DML is enabled in a session, all DML statements in this session will be considered for parallel execution. However, even if the PARALLEL DML is enabled, the DML operation may still execute serially if there are no parallel hints or parallel clauses or if restrictions on parallel operations are violated (see "Restrictions on Parallel DML").
The session's PARALLEL DML mode does not influence the parallelism of SELECT statements, DDL statements, and the query portions of DML statements. Thus, if this mode is not set, the DML operation is not parallelized but scans or join operations within the DML statement may still be parallelized.
A session that is enabled for PARALLEL DML may put transactions in the session in a special mode: If any DML statement in a transaction modifies a table in parallel, no subsequent serial or parallel query or DML statement can access the same table again in that transaction. This means that the results of parallel modifications cannot be seen during the transaction.
Serial or parallel statements that attempt to access a table which has already been modified in parallel within the same transaction are rejected with an error message.
If a PL/SQL procedure or block is executed in a PARALLEL DML enabled session, then this rule applies to statements in the procedure or block.
To execute a DML operation in parallel, the parallel execution coordinator acquires or spawns parallel execution servers and each parallel execution server executes a portion of the work under its own parallel process transaction.
The coordinator also has its own coordinator transaction, which can have its own rollback segment.
Oracle assigns transactions to rollback segments that have the fewest active transactions. To speed up both forward and undo operations, you should create and bring online enough rollback segments so that at most two parallel process transactions are assigned to one rollback segment.
Create the rollback segments in tablespaces that have enough space for them to extend when necessary and set the MAXEXTENTS storage parameters for the rollback segments to UNLIMITED. Also, set the OPTIMAL value for the rollback segments so that after the parallel DML transactions commit, the rollback segments will be shrunk to the OPTIMAL size.
A parallel DML operation is executed by more than one independent parallel process transaction. In order to ensure user-level transactional atomicity, the coordinator uses a two-phase commit protocol to commit the changes performed by the parallel process transactions.
This two-phase commit protocol is a simplified version which makes use of shared disk architecture to speed up transaction status lookups, especially during transactional recovery. It does not require the Oracle XA library. In-doubt transactions never become visible to users.
The time required to roll back a parallel DML operation is roughly equal to the time it took to perform the forward operation.
Oracle supports parallel rollback after transaction and process failures, and after instance and system failures. Oracle can parallelize both the rolling forward stage and the rolling back stage of transaction recovery.
|
Additional Information:
See the Oracle8i Backup and Recovery Guide for details about parallel rollback. |
A user-issued rollback in a transaction failure due to statement error is performed in parallel by the parallel execution coordinator and the parallel execution servers. The rollback takes approximately the same amount of time as the forward transaction.
Recovery from the failure of a parallel DML coordinator or parallel execution server is performed by the PMON process.
Recovery from a system failure needs a new startup. Recovery is performed by the SMON process and any recovery server processes spawned by SMON. Parallel DML statements may be recovered in parallel using parallel rollback. If the initialization parameter COMPATIBLE is set to 8.1.3 or greater, Fast-Start On-Demand Rollback enables dead transactions to be recovered, on demand, one block at a time (see "Fast-Start On-Demand Rollback").
Recovery from an instance failure in an Oracle Parallel Server is performed by the recovery processes (that is, the SMON processes and any recovery server processes they spawn) of other live instances. Each recovery process of the live instances can recover the parallel execution coordinator and/or parallel execution server transactions of the failed instance independently.
Parallel UPDATE uses the space in the existing object, as opposed to direct-load INSERT which gets new segments for the data.
Space usage characteristics may be different in parallel than they would be if the statement executed sequentially, because multiple concurrent child transactions modify the object.
See "Space Considerations" for information about space for direct-load INSERT.
A parallel DML operation's lock and enqueue resource requirements are very different from the serial DML requirements. Parallel DML holds many more locks, so you should increase the value of the ENQUEUE_RESOURCES and DML_LOCKS parameters.
The processes for a parallel UPDATE, DELETE, or INSERT statement acquire the following locks:
For parallel INSERT into a partitioned table, the coordinator acquires partition locks for all partitions. For parallel UPDATE or DELETE, the coordinator acquires partition locks for all partitions, unless the WHERE clause limits the partitions involved.
A parallel execution server can work on one or more partitions, but a partition can only be worked on by one parallel execution server.
For example, for a table with 600 partitions running with parallel degree 100, a parallel DML statement needs the following locks (assuming all partitions are involved in the statement):
A special type of parallel UPDATE exists called row-migrating parallel UPDATE. This parallel update method is only used when a table is defined with the row movement clause enabled and it allows rows to be moved to different partitions or subpartitions.
Table 26-2 summarizes the types of locks acquired by coordinator and parallel execution servers for different types of parallel DML statements.
The following restrictions apply to parallel DML (including direct-load INSERT):
Violations will cause the statement to execute serially without warnings or error messages (except for the restriction on statements accessing the same table in a transaction, which can cause error messages). For example, an update will be serialized if it is on a nonpartitioned table.
The following sections give further details about restrictions.
You can only update the partitioning key of a partitioned table to a new value if the update would not cause the row to move to a new partition unless the table is defined with the row movement clause enabled.
The function restrictions for parallel DML are the same as those for parallel DDL and parallel query. See "Parallel Execution of Functions".
This section describes the interactions of integrity constraints and parallel DML statements.
These types of integrity constraints are allowed. They are not a problem for parallel DML because they are enforced on the column and row level, respectively.
These types of integrity constraints are allowed.
There are restrictions for referential integrity whenever a DML operation on one table could cause a recursive DML operation on another table or, in order to perform the integrity check, it would be necessary to see simultaneously all changes made to the object being modified.
Table 26-3 lists all of the operations that are possible on tables that are involved in referential integrity constraints.
Delete on tables having a foreign key with delete cascade is not parallelized because parallel execution servers will try to delete rows from multiple partitions (parent and child tables).
DML on tables with self-referential integrity constraints is not parallelized if the referenced keys (primary keys) are involved. For DML on all other columns, parallelism is possible.
If there are any deferrable constraints on the table being operated on, the DML operation will not be parallelized.
A DML operation will not be parallelized if any triggers are enabled on the affected tables that may get fired as a result of the statement. This implies that DML statements on tables that are being replicated will not be parallelized.
Relevant triggers must be disabled in order to parallelize DML on the table. Note that enabling/disabling triggers invalidates dependent shared cursors.
A DML operation cannot be parallelized if it is in a distributed transaction or if the DML or the query operation is against a remote object.
DML statement which queries a remote object:
INSERT /* APPEND PARALLEL (t3,2) */ INTO t3 SELECT * FROM t4@dblink;
The query operation is executed serially without notification because it references a remote object.
DML operation on a remote object:
DELETE /*+ PARALLEL (t1, 2) */ FROM t1@dblink;
The DELETE operation is not parallelized because it references a remote object.
In a distributed transaction:
SELECT * FROM t1@dblink; DELETE /*+ PARALLEL (t2,2) */ FROM t2; COMMIT;
The DELETE operation is not parallelized because it occurs in a distributed transaction (which is started by the SELECT statement).
The execution of user-written functions written in PL/SQL, in Java, or as external procedures in C, can be parallelized. Any PL/SQL package variables or Java static attributes used by the function are entirely private to each individual parallel execution process, however, and are newly initialized at the start of each parallel execution process rather than being copied from the original session. Because of this, not all functions will generate correct results if executed in parallel.
To allow a user-written function to be executed in parallel, use the PARALLEL_ENABLE keyword when you declare the function in either the CREATE FUNCTION or CREATE PACKAGE statement.
In a SELECT statement or a subquery in a DML or DDL statement, a user-written function may be executed in parallel if it has been declared with the PARALLEL_ENABLE keyword, if it is declared in a package or type and has a PRAGMA RESTRICT_REFERENCES that indicates all of WNDS, RNPS, and WNPS, or if it is declared with CREATE FUNCTION and the system can analyze the body of the PL/SQL code and determine that the code neither writes to the database nor reads nor modifies package variables.
Other parts of a query or subquery can sometimes execute in parallel even if a given function execution must remain serial.
|
Additional Information:
See the description of the pragma RESTRICT_REFERENCES in the Oracle8i Application Developer's Guide - Fundamentals and the description of CREATE FUNCTION in the Oracle8i SQL Reference. |
In a parallel DML or DDL statement, as in a parallel query, a user-written function may be executed in parallel if it has been declared with the PARALLEL_ENABLE keyword, if it is declared in a package or type and has a PRAGMA RESTRICT_REFERENCES that indicates all of RNDS, WNDS, RNPS, and WNPS, or if it is declared with CREATE FUNCTION and the system can analyze the body of the PL/SQL code and determine that the code neither reads nor writes to the database nor reads nor modifies package variables.
For a parallel DML statement, any function call that cannot be executed in parallel causes the entire DML statement to be executed serially.
For an INSERT ... SELECT or CREATE TABLE ... AS SELECT statement, function calls in the query portion are parallelized according to the parallel query rules in the prior paragraph; the query may be parallelized even if the remainder of the statement must execute serially, or vice versa.
|
Attention: The features described in this section are available only if you have purchased Oracle8i Enterprise Edition with the Parallel Server Option. See Getting to Know Oracle8i for information about the features and options available with Oracle8i Enterprise Edition. |
In a shared-disk cluster or massively parallel processing (MPP) configuration, an instance of the Oracle Parallel Server is said to have affinity for a device if the device is directly accessed from the processor(s) on which the instance is running. Similarly, an instance has affinity for a file if it has affinity for the device(s) that the file is stored on.
Determination of affinity may involve arbitrary determinations for files that are striped across multiple devices. Somewhat arbitrarily, an instance is said to have affinity for a tablespace (or a partition of a table or index within a tablespace) if the instance has affinity for the first file in the tablespace.
Oracle considers affinity when allocating work to parallel execution servers. The use of affinity for parallel execution of SQL statements is transparent to users.
Affinity in parallel queries increases the speed of scanning data from disk by doing the scans on a processor that is "near" the data. This can provide a substantial performance increase for machines that do not naturally support shared disks.
The most common use of affinity is for a table or index partition to be stored in one file on one device. This configuration provides the highest availability by limiting the damage done by a device failure and makes best use of partition-parallel index scans.
DSS customers might prefer to stripe table partitions over multiple devices (probably a subset of the total number of devices). This allows some queries to prune the total amount of data being accessed using partitioning criteria and still obtain parallelism through rowid-range parallel table (partition) scans. If the devices are configured as a RAID, availability can still be very good. Even when used for DSS, indexes should probably be partitioned on individual devices.
Other configurations (for example, multiple partitions in one file striped over multiple devices) will yield correct query results, but you may need to use hints or explicitly set object attributes to select the correct degree of parallelism.
For parallel DML (inserts, updates, and deletes), affinity enhancements improve cache performance by routing the DML operation to the node that has affinity for the partition.
Affinity determines how to distribute the work among the set of instances and/or parallel execution servers to perform the DML operation in parallel. Affinity can improve performance of queries in several ways:
For partitioned tables and indexes, partition-to-node affinity information determines process allocation and work assignment. For shared-nothing MPP systems, the Oracle Parallel Server tries to assign partitions to instances taking the disk affinity of the partitions into account. For shared-disk MPP and cluster systems, partitions are assigned to instances in a round-robin manner.
Affinity is only available for parallel DML when running in an Oracle Parallel Server configuration. Affinity information which persists across statements will improve buffer cache hit ratios and reduce block pings between instances.
|
Additional Information:
See Oracle8i Parallel Server Concepts and Administration for more information about the Oracle Parallel Server. |
In addition to parallel SQL execution, Oracle can use parallelism for the following types of operations:
Like parallel SQL, parallel recovery and parallel propagation are executed by a parallel execution coordinator and multiple parallel execution servers. Parallel load, however, uses a different mechanism.
|
Additional Information:
See Oracle8i Utilities for information about parallel load and general information about SQL*Loader. Also see Oracle8i Tuning for advice about using parallel load. |
The behavior of the parallel execution coordinator and parallel execution servers may differ, depending on what kind of operation they perform (SQL, recovery, or propagation). For example, if all parallel execution servers in the pool are occupied and the maximum number of parallel execution servers has been started:
For a given session, the parallel execution coordinator coordinates only one kind of operation. A parallel execution coordinator cannot coordinate, for example, parallel SQL and parallel propagation or parallel recovery at the same time.
See "Performing Recovery in Parallel" for general information about parallel recovery.
|
Additional Information:
See Oracle8i Backup and Recovery Guide for detailed information about parallel recovery, and see Oracle8i Replication for information about parallel propagation. |