Release 8.1.5
A67781-01
Library |
Product |
Contents |
Index |
| Oracle8i Concepts Release 8.1.5 A67781-01 |
|
![]()
![]()
I do the very best I know how--the very best I can; and I mean to keep doing so until the end.
Abraham Lincoln
This chapter introduces the Oracle optimizer. It includes:
The chapters that follow provide further information about how the Oracle optimizer works:
See Oracle8i Tuning for more information about the optimizer, including how to use materialized views for query rewrites.
Additional Information:
Optimization is the process of choosing the most efficient way to execute a SQL statement. This is an important step in the processing of any data manipulation language (DML) statement: SELECT, INSERT, UPDATE, or DELETE. Many different ways to execute a SQL statement often exist, for example, by varying the order in which tables or indexes are accessed. The procedure Oracle uses to execute a statement can greatly affect how quickly the statement executes.
A part of Oracle called the optimizer calculates the most efficient way to execute a SQL statement. The optimizer evaluates many factors to select among alternative access paths. It can use a cost-based or rule-based approach (see "Cost-Based Optimization" and "Rule-Base Optimization").
You can influence the optimizer's choices by setting the optimizer approach and goal and by gathering statistics for cost-based optimization. Sometimes the application designer, who has more information about a particular application's data than is available to the optimizer, can choose a more effective way to execute a SQL statement. The application designer can use hints in SQL statements to specify how the statement should be executed.
To execute a DML statement, Oracle may have to perform many steps. Each of these steps either retrieves rows of data physically from the database or prepares them in some way for the user issuing the statement. The combination of the steps Oracle uses to execute a statement is called an execution plan. An execution plan includes an access method for each table that the statement accesses and an ordering of the tables (the join order). "Access Methods" describes the various access methods, which include indexes, hash clusters, and table scans.
Figure 22-1 shows a graphical representation of the execution plan for the following SQL statement, which selects the name, job, salary, and department name for all employees whose salaries do not fall into a recommended salary range:
SELECT ename, job, sal, dname FROM emp, dept WHERE emp.deptno = dept.deptno AND NOT EXISTS (SELECT * FROM salgrade WHERE emp.sal BETWEEN losal AND hisal);
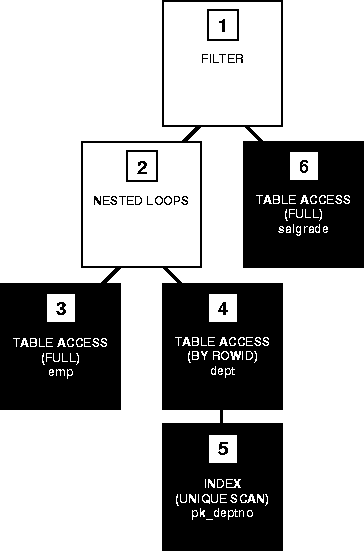
Each step of the execution plan returns a set of rows that either are used by the next step or, in the last step, are returned to the user or application issuing the SQL statement. A set of rows returned by a step is called a row source.
Figure 22-1 is a hierarchical diagram showing the flow of row sources from one step to another. The numbering of the steps reflects the order in which they are displayed in response to the EXPLAIN PLAN command (described in the next section). This generally is not the order in which the steps are executed (see "Execution Order"). Each step of the execution plan either retrieves rows from the database or accepts rows from one or more row sources as input:
Access paths are discussed further in the section "Choosing Access Paths". Methods by which Oracle joins row sources are discussed in "Join Operations".
You can examine the execution plan chosen by the optimizer for a SQL statement by using the EXPLAIN PLAN command, which causes the optimizer to choose the execution plan and then inserts data describing the plan into a database table.
For example, the following output table is such a description for the statement examined in the previous section:
ID OPERATION OPTIONS OBJECT_NAME ------------------------------------------------------------ 0 SELECT STATEMENT 1 FILTER 2 NESTED LOOPS 3 TABLE ACCESS FULL EMP 4 TABLE ACCESS BY ROWID DEPT 5 INDEX UNIQUE SCAN PK_DEPTNO 6 TABLE ACCESS FULL SALGRADE
Each box in Figure 22-1 and each row in the output table corresponds to a single step in the execution plan. For each row in the listing, the value in the ID column is the value shown in the corresponding box in Figure 22-1.
You can obtain such a listing by using the EXPLAIN PLAN command and then querying the output table.
|
Additional Information:
See Oracle8i Tuning for information on how to use EXPLAIN PLAN and produce and interpret its output. |
The steps of the execution plan are not performed in the order in which they are numbered. Rather, Oracle first performs the steps that appear as leaf nodes in the tree-structured graphical representation of the execution plan (Steps 3, 5, and 6 in Figure 22-1). The rows returned by each step become the row sources of its parent step. Then Oracle performs the parent steps.
To execute the statement for Figure 22-1, for example, Oracle performs the steps in this order:
Note that Oracle performs Steps 5, 4, 2, 6, and 1 once for each row returned by Step 3. If a parent step requires only a single row from its child step before it can be executed, Oracle performs the parent step (and possibly the rest of the execution plan) as soon as a single row has been returned from the child step. If the parent of that parent step also can be activated by the return of a single row, then it is executed as well.
Thus the execution can cascade up the tree, possibly to encompass the rest of the execution plan. Oracle performs the parent step and all cascaded steps once for each row in turn retrieved by the child step. The parent steps that are triggered for each row returned by a child step include table accesses, index accesses, nested loops joins, and filters.
If a parent step requires all rows from its child step before it can be executed, Oracle cannot perform the parent step until all rows have been returned from the child step. Such parent steps include sorts, sort-merge joins, and aggregate functions.
After carefully tuning an application, you might want to ensure that the optimizer generates the same execution plan whenever the same SQL statements are executed. Plan stability allows you to maintain the same execution plans for the same SQL statements, regardless of changes to the database such as re-analyzing tables, adding or deleting data, modifying a table's columns, constraints, or indexes, changing the system configuration, or even upgrading to a new version of the optimizer.
The CREATE OUTLINE statement creates a stored outline, which contains a set of attributes that the optimizer uses to create an execution plan. Stored outlines can also be created automatically by setting the system parameter CREATE_STORED_OUTLINES to TRUE.
The system parameter USE_STORED_OUTLINES can be set to TRUE, FALSE, or a category name to indicate whether to make use of existing stored outlines for queries that are being executed. The OUTLN_PKG package provides procedures used for managing stored outlines.
Implementing plan stability creates a new schema called OUTLN, which is created with DBA privileges. The database administrator should change the password for the OUTLN schema just as for the SYS and SYSTEM schemas.
|
Additional Information:
See Oracle8i Tuning for information about using plan stability, Oracle8i SQL Reference for information about the CREATE OUTLINE statement, and Oracle8i Supplied Packages Reference for information about the OUTLN_PKG package. |
Using the cost-based approach, the optimizer determines which execution plan is most efficient by considering available access paths and factoring in information based on statistics for the schema objects (tables or indexes) accessed by the SQL statement. The cost-based approach also considers hints, which are optimization suggestions placed in a Comment in the statement.
Conceptually, the cost-based approach consists of these steps:
The cost is an estimated value proportional to the expected resource use needed to execute the statement with a particular execution plan. The optimizer calculates the cost of each possible access method and join order based on the estimated computer resources, including (but not limited to) I/O, CPU time, and memory, that are required to execute the statement using the plan.
Serial execution plans with greater costs take more time to execute than those with smaller costs. When using a parallel execution plan, however, resource use is not directly related to elapsed time.
By default, the goal of the cost-based approach is the best throughput, or minimal resource use necessary to process all rows accessed by the statement.
Oracle can also optimize a statement with the goal of best response time, or minimal resource use necessary to process the first row accessed by a SQL statement. For information on how the optimizer chooses an optimization approach and goal, see "Choosing an Optimization Approach and Goal".
For parallel execution of a SQL statement, the optimizer can choose to minimize elapsed time at the expense of resource consumption. The initialization parameter OPTIMIZER_PERCENT_PARALLEL specifies how much the optimizer attempts to parallelize execution.
|
Additional Information:
See Oracle8i Tuning for information about using the OPTIMIZER_PERCENT_PARALLEL parameter. |
The cost-based approach uses statistics to calculate the selectivity of predicates and estimate the cost of each execution plan. Selectivity is the fraction of rows in a table that the SQL statement's predicate chooses. The optimizer uses the selectivity of a predicate to estimate the cost of a particular access method and to determine the optimal join order.
Statistics quantify the data distribution and storage characteristics of tables, columns, indexes, and partitions. The optimizer uses these statistics to estimate how much I/O, CPU time, and memory are required to execute a SQL statement using a particular execution plan. The statistics are stored in the data dictionary, and they can be exported from one database and imported into another (for example, to transfer production statistics to a test system to simulate the real environment, even though the test system may only have small samples of data).
You must gather statistics on a regular basis to provide the optimizer with information about schema objects. New statistics should be gathered after a schema object's data or structure are modified in ways that make the previous statistics inaccurate. For example, after loading a significant number of rows into a table, you should collect new statistics on the number of rows. After updating data in a table, you do not need to collect new statistics on the number of rows but you might need new statistics on the average row length. See "Gathering Statistics".
Cost-based optimization uses data value histograms to get accurate estimates of the distribution of column data. A histogram partitions the values in the column into bands, so that all column values in a band fall within the same range. Histograms provide improved selectivity estimates in the presence of data skew, resulting in optimal execution plans with nonuniform data distributions.
One of the fundamental capabilities of cost-based optimization is determining the selectivity of predicates that appear in queries. Selectivity estimates are used to decide when to use an index and the order in which to join tables. Most attribute domains (a table's columns) are not uniformly distributed.
Cost-based optimization uses height-balanced histograms on specified attributes to describe the distributions of nonuniform domains. In a height-balanced histogram, the column values are divided into bands so that each band contains approximately the same number of values. The useful information that the histogram provides, then, is where in the range of values the endpoints fall.
Consider a column C with values between 1 and 100 and a histogram with 10 buckets. If the data in C is uniformly distributed, this histogram would look like this, where the numbers are the endpoint values:
The number of rows in each bucket is one tenth the total number of rows in the table. Four-tenths of the rows have values between 60 and 100 in this example of uniform distribution.
If the data is not uniformly distributed, the histogram might look like this:

In this case, most of the rows have the value 5 for the column. In this example, only 1/10 of the rows have values between 60 and 100.
Oracle uses height-balanced histograms (as opposed to width-balanced).
For example, suppose that the values in a single column of a 1000-row table range between 1 and 100, and suppose that you want a 10-bucket histogram (ranges in a histogram are called buckets). In a width-balanced histogram, the buckets would be of equal width (1-10, 11-20, 21-30, and so on) and each bucket would count the number of rows that fall into that bucket's range. In a height-balanced histogram, each bucket has the same height (in this case 100 rows) and the endpoints for each bucket are determined by the density of the distinct values in the column.
The advantage of the height-balanced approach is clear when the data is highly skewed. Suppose that 800 rows of a 1000-row table have the value 5, and the remaining 200 rows are evenly distributed between 1 and 100. A width-balanced histogram would have 820 rows in the bucket labeled 1-10 and approximately 20 rows in each of the other buckets. The height-based histogram would have one bucket labeled 1-5, seven buckets labeled 5-5, one bucket labeled 5-50, and one bucket labeled 50-100.
If you want to know how many rows in the table contain the value 5, the height-balanced histogram shows that approximately 80% of the rows contain this value. However, the width-balanced histogram does not provide a mechanism for differentiating between the value 5 and the value 6. You would compute only 8% of the rows contain the value 5 in a width-balanced histogram. Therefore height-based histograms are more appropriate for determining the selectivity of column values.
Histograms can affect performance and should be used only when they substantially improve query plans. In general, you should create histograms on columns that are frequently used in WHERE clauses of queries and have a highly skewed data distribution. For many applications, it is appropriate to create histograms for all indexed columns because indexed columns typically are the columns most often used in WHERE clauses.
Histograms are persistent objects, so there is a maintenance and space cost for using them. You should compute histograms only for columns that you know have highly skewed data distribution. For uniformly distributed data, cost-based optimization can make fairly accurate guesses about the cost of executing a particular statement without the use of histograms.
Histograms, like all other optimizer statistics, are static. They are useful only when they reflect the current data distribution of a given column. (The data in the column can change as long as the distribution remains constant.) If the data distribution of a column changes frequently, you must recompute its histogram frequently.
Histograms are not useful for columns with the following characteristics:
You generate histograms by using the DBMS_STATS package or the ANALYZE command (see "Gathering Statistics"). You can generate histograms for columns of a table or partition. Histogram statistics are not collected in parallel.
You can view histogram information with the following data dictionary views:
Partitioned schema objects may contain multiple sets of statistics. They can have statistics which refer to the entire schema object as a whole (global statistics), they can have statistics which refer to an individual partition, and they can have statistics which refer to an individual subpartition of a composite partitioned object.
Unless the query predicate narrows the query to a single partition, the optimizer will use the global statistics. Since most queries are not likely to be this restrictive, it is most important to have accurate global statistics. Intuitively, it may seem that generating global statistics from partition-level statistics should be straightforward; however, this is only true for some of the statistics. For example, it is very difficult to figure out the number of distinct values for a column from the number of distinct values found in each partition because of the possible overlap in values. Therefore, actually gathering global statistics with the DBMS_STATS package is highly recommended, rather than calculating them with the ANALYZE command (see "The ANALYZE Command").
This section describes the different methods you can use to gather statistics.
The PL/SQL package DBMS_STATS enables you to generate and manage statistics for cost-based optimization. You can use this package to gather, modify, view, and delete statistics. You can also use this package to store sets of statistics (see "Statistics Tables").
The DBMS_STATS package can gather statistics on indexes, tables, columns, and partitions, as well as statistics on all schema objects in a schema or database. It does not gather cluster statistics--you can use DBMS_STATS to gather statistics on the individual tables instead of the whole cluster.
The statistics-gathering operations can run either serially or in parallel. Whenever possible, DBMS_STATS calls a parallel query to gather statistics with the specified degree of parallelism; otherwise, it calls a serial query or the ANALYZE statement. Index statistics are not gathered in parallel.
The statistics can be computed exactly or estimated from a random sampling of rows or blocks (see "Exact and Estimated Statistics").
For partitioned tables and indexes, DBMS_STATS can gather separate statistics for each partition as well as global statistics for the entire table or index. Similarly, for composite partitioning DBMS_STATS can gather separate statistics for subpartitions, partitions, and the entire table or index. Depending on the SQL statement being optimized, the optimizer may choose to use either the partition (or subpartition) statistics or the global statistics.
DBMS_STATS gathers statistics only for cost-based optimization; it does not gather other statistics. For example, the table statistics gathered by DBMS_STATS include the number of rows, number of blocks currently containing data, and average row length but not the number of chained rows, average free space, or number of unused data blocks.
|
Additional Information:
See Oracle8i Tuning for examples of how to gather statistics with the DBMS_STATS package. |
Oracle can gather some statistics automatically while creating or rebuilding a B*-tree or bitmap index. The COMPUTE STATISTICS option of CREATE INDEX or ALTER INDEX ... REBUILD enables this gathering of statistics.
The statistics that Oracle gathers for the COMPUTE STATISTICS option depend on whether the index is partitioned or nonpartitioned.
To ensure correctness of the statistics Oracle always uses base tables when creating an index with the COMPUTE STATISTICS option, even if another index is available that could be used to create the index.
|
Additional Information:
See Oracle8i SQL Reference for details about the COMPUTE STATISTICS option of the CREATE INDEX and ALTER INDEX commands. |
The ANALYZE command can also generate statistics for cost-based optimization. Using ANALYZE for this purpose is not recommended because of various restrictions, for example:
ANALYZE can gather additional information that is not used by the optimizer, such as information about chained rows and the structural integrity of indexes, tables, and clusters. DBMS_STATS does not gather this information.
|
Additional Information:
See Oracle8i SQL Reference for detailed information about the ANALYZE statement. |
The statistics gathered by the DBMS_STATS package or ANALYZE statement can be exact or estimated. (The COMPUTE STATISTICS option for creating or rebuilding indexes always gathers exact statistics.)
To compute exact statistics, Oracle must read all of the data in the index, table, partition, or schema. Some statistics are always computed exactly, such as the number of data blocks currently containing data in a table or the depth of an index from its root block to its leaf blocks.
To estimate statistics, Oracle selects a random sample of data. You can specify the sampling percentage and whether sampling should be based on rows or blocks.
Row sampling reads rows without regard to their physical placement on disk. This provides the most random data for estimates, but it can result in reading more data than necessary. For example, in the worst case a row sample might select one row from each block, requiring a full scan of the table or index.
Block sampling reads a random sample of blocks and uses all of the rows in those blocks for estimates. This reduces the amount of I/O activity for a given sample size, but it can reduce the randomness of the sample if rows are not randomly distributed on disk. Block sampling is not available for index statistics.
This section describes statistics tables and lists the views that display information about statistics stored in the data dictionary.
The DBMS_STATS package enables you to store statistics in a statistics table. You can transfer the statistics for a column, table, index, or schema into a statistics table and subsequently restore those statistics to the data dictionary. The optimizer does not use statistics that are stored in a statistics table.
Statistics tables enable you to experiment with different sets of statistics. For example, you can back up a set of statistics before you delete them, modify them, or generate new statistics. You can then compare the performance of SQL statements optimized with different sets of statistics, and if the statistics stored in a table give the best performance, you can restore them to the data dictionary.
A statistics table can keep multiple distinct sets of statistics, or you can create multiple statistics tables to store distinct sets of statistics separately.
You can use the DBMS_STATS package to view the statistics stored in the data dictionary or in a statistics table.
You can also query these data dictionary views for statistics in the data dictionary:
In general, you should use the cost-based approach for all new applications; the rule-based approach is provided for applications that were written before cost-based optimization was available. Cost-based optimization can be used for both relational data and object types.
The following features can only use cost-based optimization:
See Oracle8i Tuning for more information on when to use the cost-based approach.
Additional Information:
Extensible optimization allows the authors of user-defined functions and domain indexes to control the three main components that cost-based optimization uses to select an execution plan: statistics, selectivity, and cost evaluation.
Extensible optimization allows you to:
See the Oracle8i Data Cartridge Developer's Guide for details about extensible optimization.
Additional Information:
You can define statistics collection functions for domain indexes, individual columns of a table, and user-defined datatypes.
Whenever a domain index is analyzed to gather statistics, Oracle calls the associated statistics collection function. Whenever a column of a table is analyzed, Oracle collects the standard statistics for that column and calls any associated statistics collection function. If a statistics collection function exists for a datatype, Oracle calls it for each column that has that datatype in the table being analyzed.
The selectivity of a predicate in a SQL statement is used to estimate the cost of a particular access method; it is also used to determine the optimal join order. The optimizer cannot compute an accurate selectivity for predicates that contain user-defined operators, because it does not have any information about these operators.
You can define selectivity functions for predicates containing user-defined operators, stand-alone functions, package functions, or type methods. The optimizer calls the user-defined selectivity function whenever it encounters a predicate that contains the operator, function, or method in one of the following relations with a constant: <, <=, =, >=, >, or LIKE.
The optimizer cannot compute an accurate estimate of the cost of a domain index because it does not know the internal storage structure of the index. Also, the optimizer may underestimate the cost of a user-defined function that invokes PL/SQL, uses recursive SQL, accesses a BFILE, or is CPU-intensive.
You can define costs for domain indexes and user-defined stand-alone functions, package functions, and type methods. These user-defined costs can be in the form of default costs that the optimizer simply looks up or they can be full-fledged cost functions that the optimizer calls to compute the cost.
Using the rule-based approach, the optimizer chooses an execution plan based on the access paths available and the ranks of these access paths (shown in Table 23-1). You can use rule-based optimization to access both relational data and object types.
Oracle's ranking of the access paths is heuristic. If there is more than one way to execute a SQL statement, the rule-based approach always uses the operation with the lower rank. Usually, operations of lower rank execute faster than those associated with constructs of higher rank.
For more information, see "Choosing an Access Path with the Rule-Based Approach".
|
Note: Rule-based optimization is not available for some advanced features of Oracle8i. For a list of these features, see "When to Use the Cost-Based Approach". |