Release 8.0
A54638-01
Library |
Product |
Contents |
Index |
| Oracle8(TM) Server Tuning Release 8.0 A54638-01 |
|
![]()
![]()
This chapter describes how to identify and solve problems with CPU resources. Topics in this chapter include
Establish appropriate expectations for the amount of CPU your system should be using. You can then distinguish whether there is insufficient CPU available, or your system is consuming too much CPU. Begin by determining three figures: the amount of CPU the Oracle instance utilizes
Workload is a very important factor when evaluating your system's level of CPU utilization. During peak workload hours, 90% CPU utilization with 10% idle and waiting time may be understandable and acceptable. Thirty percent utilization at a time of low workload may also be understandable. However, if your system shows high utilization at normal workload, there is no room for peak workload.
For example, Figure 13-1 illustrates workload over time for an application which has peak periods at 10:00 AM and 2:00 PM.
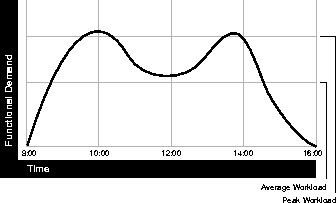
This example application has 100 users working 8 hours a day, for a total of 800 hours per day. If each user enters one transaction every 5 minutes, this would mean 9,600 transactions per day. Over the course of 8 hours, the system must support 1,200 transactions per hour, which is an average of 20 transactions per minute. If the demand rate were constant, you could build a system to meet this average workload.
However, usage patterns form peaks and valleys--and in this context 20 transactions per minute can be understood as merely a minimum requirement. If the peak rate you need to achieve is 120 transactions per minute, then you must configure a system which can support this peak workload.
For this example, assume that at peak workload Oracle can use 90% of the CPU resource. For a period of average workload, then, Oracle should be using no more than about 15% of the available CPU resource.
15% = 20 tpm/120 tpm * 90%
If the system requires 50% of the CPU resource to achieve 20 transactions per minute, then it is clear that a problem exists: the system cannot possibly achieve 120 transactions per minute using 90% of the CPU. If you were to tune this system such that it does achieve 20 transactions per minute using only 15% of the CPU, then (assuming linear scalability) the system might indeed attain 120 transactions per minute using 90% of the CPU.
Note that as users are added to an application over time, the average workload can rise up to what had been peak levels. Then there is no CPU capacity available for the new peak rate, which is actually higher than before.
If you suspect a problem with CPU usage, you must evaluate two areas:
Oracle statistics only report the CPU utilization of Oracle sessions, whereas every process running on your system affects the available CPU resources. Tuning non-Oracle factors can thus result in better Oracle performance.
Use operating system monitoring tools to see what processes are running on the system as a whole. If the system is too heavily loaded, check the memory, I/O, and process management areas described later in this section.
Tools such as sar -u on many UNIX-based systems enable you to examine the level of CPU utilization on your entire system. CPU utilization in UNIX is described in statistics that show user time, system time, idle time, time waiting for I/O. You have a CPU problem if idle time and time waiting for I/O are both close to zero (less than 5%) at a normal or low workload.
Performance Monitor is used on NT systems to examine CPU utilization. It provides statistics on processor time, user time, privileged time, interrupt time, and DPC time. (Note that Performance Monitor is not to be confused with Performance Manager, which is an Oracle Enterprise Manager tool.)
Attention: This section describes how to check system CPU utilization on most UNIX-based systems. For non-UNIX platforms, please check your operating system documentation.
Check the following memory management issues:
Paging and Swapping. Use the appropriate tools (such as sar or vmstat on UNIX or Performance Monitor on NT) to investigate the cause of paging and swapping, should they occur.
Oversize Page Tables. If the processing space becomes too large, it may result in the page tables becoming too large. (This is not an issue on NT systems.)
Check the following I/O management issues:
Thrashing. Make sure that your workloads will fit in memory, so that the machine is not thrashing (swapping and paging processes in and out of memory). The operating system allocates fixed slices of time during which CPU resources are available to your process. If the process squanders a large portion of each time slice checking to be sure that it can run, that all needed components are in the machine, it may be using only 50% of the time allotted to actually perform work.
Client/Server Round Trips. The latency of sending a message may result in CPU overload. Often an application may generate a message which needs to be sent via the network over and over again. This results in a lot of overhead that must be done before the message is actually sent. To alleviate this problem you can batch them into bigger messages and do the work only once, or reduce the amount of work. For example, you can use array inserts, array fetches, and so on.
Check the following process management issues:
Scheduling and Switching. The operating system may spend a lot of time in scheduling and switching processes. Examine the way in which you are using the operating system: you could be using too many processes. (On NT systems, do not overload your server with a great deal of non-Oracle processes.)
Context Switching. Due to operating system specific characteristics, your system could be spending a lot of time in context switches. This could be expensive, especially with a very large SGA. (Note that context switching is not an issue on NT, which has only one process per instance. All threads share the same page table.)
Often people create processes on the fly, to do one thing. Then they exit the process, and create a new one such that the process is recreated and destroyed all the time. This is very CPU-intensive, especially with large SGAs. With large SGAs, creating processes on the fly becomes expensive because you have to build up the page tables. This is particularly expensive when you nail or lock shared memory: then you have to touch every page.
For example, if you have a 1 gigabyte SGA, you may have page table entries for every 4K, and a page table entry may be 8 bytes. You could end up with
(1G /4K) * 8B entries. This becomes expensive, because you have to continually make sure that the page table is loaded.
Parallel query and multi-threaded server are areas of concern here, where MINSERVICE has been set too low (set to 10, for example, when you need 20).
For the user, doing small lookups may not be wise. In a situation like this, it becomes inefficient for the user and for the system as well.
This section explains how to examine the processes running in Oracle.
V$SYSSTAT shows Oracle CPU usage for all sessions. The statistic "CPU used by this session" actually shows the aggregate CPU used by all sessions.
V$SESSTAT shows Oracle CPU usage per session. You can use this view to see which particular session is using the most CPU.
For example, if you have 8 CPUs, then for any given minute in real time, you have 8 minutes of CPU time available. On NT and UNIX-based systems this can be either user time or time in system mode ("privileged" mode, in NT). If your process is not running, it is waiting. CPU utilized by all systems may thus be greater than one minute per interval.
At any given moment you know how much time Oracle has utilized the system. So if 8 minutes are available and Oracle uses 4 minutes of that time, then you know that 50% of all CPU time is used by Oracle. If your process is not consuming that time, then some other process is. Go back to the system and find out what process is using up the CPU. Identify it, determine why it is using so much CPU, and see if you can tune it.
The major areas to check for Oracle CPU utilization are:
This section describes each area, and indicates the corresponding Oracle statistics to check.
Ineffective SQL sharing can result in reparsing.
SELECT * FROM V$SYSSTAT
WHERE NAME IN
('parse time cpu', 'parse time elapsed', 'parse count (hard)');
In interpreting these statistics, remember
In this way you can detect the general response time on parsing. The more your application is parsing, the more contention there is and the more time you will spend waiting. Note that
SELECT SQL_TEXT, PARSE_CALLS, EXECUTIONS FROM V$SQLAREA
ORDER BY PARSE_CALLS;
Inefficient SQL statements can consume large amounts of CPU. To detect them, enter the following query. You may be able to reduce CPU usage by tuning SQL statements which have a high number of buffer gets.
SELECT BUFFER_GETS, EXECUTIONS, SQL_TEXT FROM V$SQLAREA;
See Also: "Approaches to SQL Statement Tuning" on page 7-7
Your system could spend a lot of time rolling back or undoing changes to blocks in order to get a consistent view.
It would be better to make more rollback segments, or to increase the commit rate. For example, if you were to batch together ten transactions and commit them once, you would reduce the number of transactions by a factor of ten.
You can increase the size of the buffer cache to enable the DBWR to keep up. To find the average number of buffers you have to scan at the end of the least recently used list (LRU), to find a free buffer, use the following formula:
Normally you would expect to see 1 or 2 buffers scanned, on average. If more than this number are being scanned, you can increase the size of the buffer cache or tune the DBWR.
You can apply the following formula to find the number of buffers that were dirty at the end of the LRU.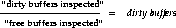
If there are many dirty buffers, it could mean that the DBWR process cannot keep up. Again, increase buffer cache size or tune DBWR.
In most of this CPU tuning discussion we assume linear scalability--but this is never actually the case. How flat or nonlinear the scalability is indicates how far away from the ideal you are. Problems in your application might be hurting scalability: examples include too many indexes, right hand index problems, too much data in blocks, or not partitioning the data. Contention problems like these waste CPU cycles and prevent the application from attaining linear scalability.
Latch contention is a symptom, it is not normally the cause of CPU problems. Your task is to translate the latch contention to an application area: track down the contention to determine which part of your application is poorly written.
The spin count may be set too high. Some other process may be holding a latch which your process is attempting to get--and your process may be spinning and spinning in an effort to get the latch. After a while your process may go to sleep before waking up to repeat its ineffectual spinning.
If there is a lot of contention, it may be better for a process to go to sleep at once when it cannot obtain a latch, rather than use up a great deal of CPU time by actively spinning and waiting.
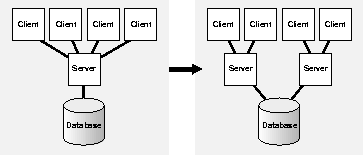
If you have reached the limit of CPU power available on your system, and have exhausted all means of tuning its CPU usage, then you must consider rearchitecting your system. Consider whether moving to a different architecture might result in adequate CPU power. This section describes various possibilities.
Attention: If you are running a multi-tier system, check all levels for CPU utilization. For example, on a three-tier system you might learn that your server is mostly idle and your second tier is completely busy. The solution would then be clear: tune the second tier, rather than the server or the third tier. In a multi-tier situation, it is usually not the server that has a performance problem: it is usually the clients and the middle tier.
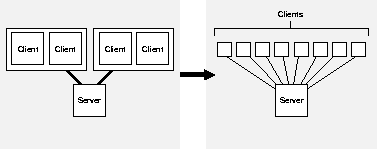
Consider whether changing from clients and server all running on a single machine (single tier) to a two-tier client/server configuration could help to relieve CPU problems.
Consider whether CPU usage might be improved if you used smaller clients, rather than multiple clients on bigger machines. This strategy may be helpful with either two-tier or three-tier configurations.
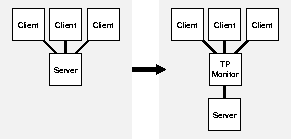
If your system currently runs with multiple layers, consider whether moving from a two-tier to three-tier configuration, introducing the use of a transaction processing monitor, might be a good solution.
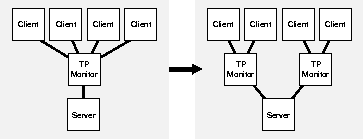
Consider whether using multiple transaction processing monitors might be a good solution.
Consider whether your CPU problems could be solved by incorporating Oracle Parallel Server.