Release 8.0
A54638-01
Library |
Product |
Contents |
Index |
| Oracle8(TM) Server Tuning Release 8.0 A54638-01 |
|
![]()
![]()
This chapter explains how to allocate memory to database structures. Proper sizing of these structures can greatly improve database performance. The following topics are covered:
Oracle stores information in memory and on disk. Since memory access is much faster than disk access, it is better for data requests to be satisfied by access to memory rather than access to disk. For best performance, store as much data as possible in memory rather than on disk. However, memory resources on your operating system are likely to be limited. Tuning memory allocation involves distributing available memory to Oracle memory structures.
Because Oracle's memory requirements vary depending on your application, you should tune memory allocation after tuning your application and your SQL statements. Allocating memory before tuning your application and your SQL statements may make it necessary to resize some Oracle memory structures to meet the needs of your modified statements and application.
Tune memory allocation before you tune I/O. Allocating memory establishes the amount of I/O necessary for Oracle to operate. The present chapter shows you how to allocate memory to perform as little I/O as possible.
The following terms are used in this discussion:
See Also: Chapter 15, "Tuning I/O", shows you how to perform I/O as efficiently as possible.
When you use operating system tools such as ps -efl or ps - aux on UNIX based systems to look at the size of Oracle processes, you may notice that the processes seem relatively large. To interpret the statistics shown, you must determine how much of the process size is attributable to shared memory, heap, and executable stack, and how much is the actual amount of memory the given process consumes.
The SZ statistic is given in page size (normally 4K), and normally includes the shared overhead. To calculate the private, or per-process memory usage, subtract shared memory and executable stack figures from the value of SZ. For example:
|
|
|
|
|
|
|
|
|
|
|
|
In this example, the individual process consumes only 4,000 pages; the other 16,000 pages are shared by all processes.
See Also: Oracle for UNIX Performance Tuning Tips, or your operating system documentation.
The rest of this chapter explains in detail how to tune memory allocation. For best results, you should follow these steps in the order they are presented:
Begin tuning memory allocation by tuning your operating system with these goals:
These goals apply in general to most operating systems, but the details of operating system tuning vary.
See Also: Refer to your operating system hardware and software documentation as well as your Oracle operating system-specific documentation for more information on tuning operating system memory usage.
Your operating system may store information in any of these places:
The operating system may also move information from one storage location to another, a process known as "paging" or "swapping." Many operating systems page and swap to accommodate large amounts of information that do not fit into real memory. However, excessive paging or swapping can reduce the performance of many operating systems.
Monitor your operating system behavior with operating system utilities. Excessive paging or swapping indicates that new information is often being moved into memory. In this case, your system's total memory may not be large enough to hold everything for which you have allocated memory. Either increase the total memory on your system or decrease the amount of memory you have allocated.
See Also: "Oversubscribe, with Attention to Paging" on page 19-47
Since the purpose of the System Global Area (SGA) is to store data in memory for fast access, the SGA should always be contained in main memory. If pages of the SGA are swapped to disk, its data is no longer so quickly accessible. On most operating systems, the disadvantage of excessive paging significantly outweighs the advantage of a large SGA.
Although it is best to keep the SGA in memory, the contents of the SGA will be logically split between hot and cold parts. The hot parts will always be in memory because they are always being referenced. Some of the cold parts may be paged out and there may be a performance penalty for bringing them back in. A performance problem is very likely, however, if the hot part of the SGA cannot stay in memory.
Remember that data is swapped to disk because it is not being referenced. You can cause Oracle to read the entire SGA into memory when you start your instance by setting the value of the initialization parameter PRE_PAGE_SGA to YES. Operating system page table entries are then pre-built for each page of the SGA. This setting may increase the amount of time necessary for instance startup, but it is likely to decrease the amount of time necessary for Oracle to reach its full performance capacity after startup.
PRE_PAGE_SGA may also increase the amount of time needed for process startup, because every process that starts must attach to the SGA. The cost of this strategy is fixed, however: you may simply determine that 20,000 pages must be touched every time a process is started. Whereas this approach may be useful with some applications, it may not be best for all applications. If your system creates and destroys processes all the time (by doing continual logon/logoff, for example) there may be significant overhead. Note that this setting does not prevent your operating system from paging or swapping the SGA after it is initially read into memory.
For example, if the SGA is 80 MB in size, and the page size is 4K, then 20,000 pages must be touched in order to refresh the SGA (80,000/4 = 20,000). If the system permits you to set a 4MB page size, then only 200 pages must be touched to refresh the SGA (80,000/4,000 = 200). Note that the page size is operating-system specific and generally cannot be changed. Some operating systems, however, have a special implementation for shared memory whereby you can change the page size.
You can see how much memory is allocated to the SGA and each of its internal structures by issuing this Server Manager statement:
SVRMGR> SHOW SGA
The output of this statement might look like this:
Total System Global Area 3554188 bytes
Fixed Size 22208 bytes
Variable Size 3376332 bytes
Database Buffers 122880 bytes
Redo Buffers 32768 bytes
Some operating systems for IBM mainframe computers are equipped with expanded storage or special memory, in addition to main memory, to which paging can be performed very quickly. These operating systems may be able to page data between main memory and expanded storage faster than Oracle can read and write data between the SGA and disk. For this reason, allowing a larger SGA to be swapped may lead to better performance than ensuring that a smaller SGA stays in main memory. If your operating system has expanded storage, you can take advantage of it by allocating a larger SGA despite the resulting paging.
On some operating systems, you may have control over the amount of physical memory allocated to each user. Be sure all users are allocated enough memory to accommodate the resources they need in order to use their application with Oracle.
Depending on your operating system, these resources may include:
On some operating systems, Oracle software can be installed so that a single executable image can be shared by many users. By sharing executable images among users, you can reduce the amount of memory required by each user.
The LOG_BUFFER parameter reserves space for the redo log buffer, which is fixed in size. On machines with fast processors and relatively slow disks the processor(s) may be filling the rest of the buffer in the time it takes the redo log writer to move a portion of the buffer out to disk. The log writer is always started when the buffer begins to fill. For this reason a longer buffer makes it less likely that new entries will collide with the part of the buffer still being written.
The log buffer is normally small in comparison with the total SGA size, and a modest increase can significantly enhance throughput.
Key log buffer ratio is the space request ratio: redo log space requests / redo entries. If this ratio is greater than 1:5000, then increase the size of the redo log buffer until the space request ratio stops falling.
This section explains how to tune private SQL and PL/SQL areas.
There is a trade-off between memory and reparsing. If there is a lot of reparsing, less memory is needed. If you reduce reparsing (by creating more SQL statements), then the memory requirement on the client side increases. This is due to an increase in the number of open cursors.
Tuning private SQL areas involves identifying unnecessary parse calls made by your application and then reducing them. To reduce parse calls, you may have to increase the number of private SQL areas that your application can have allocated at once. Throughout this section, information about private SQL areas and SQL statements also applies to private PL/SQL areas and
PL/SQL blocks.
This section describes three techniques for identifying unnecessary parse calls.
One way to identify unnecessary parse calls is to run your application with the SQL trace facility enabled. For each SQL statement in the trace output, examine the count statistic for the Parse step. This tells you how many times your application makes a parse call for the statement. This statistic includes parse calls that are satisfied by access to the library cache as well as parse calls that result in actually parsing the statement.
Note: This statistic does not include implicit parsing that occurs when an application executes a statement whose shared SQL area is no longer in the library cache. For information on detecting implicit parsing, see "Examining Library Cache Activity" on page 14-15.
If the count value for the Parse step is near the count value for the Execute step for a statement, your application may be deliberately making a parse call each time it executes the statement. Try to reduce these parse calls through your application tool.
Another way to identify unnecessary parse calls is to check V$SQLAREA. Enter the following query:
SELECT sql_text, parse_count, executions
FROM V$SQLAREA
When the parse_count value is close to that of executions for a given statement, you may be continually reparsing that particular SQL statement.
You can also identify unnecessary parse calls by identifying the session which gives rise to them. It may be that certain batch programs or certain types of application do most of the reparsing. Execute the following query:
SELECT * FROM V$STATNAME
WHERE name in ('parse_count (hard)','execute_count')
The results of the query will look something like this:
statistic#, name
------------ ---------
100 parse_count
90 execute_count
Then run a query like the following:
SELECT * FROM V$SESSTAT
WHERE statistics# in (90,100)
ORDER BY value, sid;
The result will be a list of all sessions and the amount of reparsing they do. For each system identifier (sid), go to V$SESSION to find the name of the program that causes the reparsing.
Depending on the Oracle application tool you are using, you may be able to control how frequently your application performs parse calls and allocates and deallocates private SQL areas. Whether your application reuses private SQL areas for multiple SQL statements determines how many parse calls your application performs and how many private SQL areas the application requires.
In general, an application that reuses private SQL areas for multiple SQL statements does not need as many private SQL areas as an application that does not reuse private SQL areas. However, an application that reuses private SQL areas must perform more parse calls because the application must make a new parse call whenever an existing private SQL is reused for a new SQL statement.
Be sure that your application can open enough private SQL areas to accommodate all of your SQL statements. If you allocate more private SQL areas, you may need to increase the limit on the number of cursors permitted for a session. You can increase this limit by increasing the value of the initialization parameter OPEN_CURSORS. The maximum value for this parameter depends on your operating system. The minimum value is 5.
The means by which you control parse calls and allocation and deallocation of private SQL areas varies depending on your Oracle application tool. The following sections introduce the means used for some tools. Note that these means apply only to private SQL areas and not to shared SQL areas.
When using the Oracle precompilers you can control private SQL areas and parse calls by setting certain options. In Oracle mode, the options and their defaults are as follows:
If you use ANSI mode, the values of HOLD_CURSOR and RELEASE_CURSOR are switched, which is not recommended.
The precompiler options can be specified in two ways:
With these options, you can employ different strategies for managing private SQL areas during the course of the program.
See Also: Programmer's Guide to the Oracle Pro*C/C++ Precompiler Release 3.0 for more information on these calls.
With the Oracle Call Interface (OCI), you have complete control over parse calls and private SQL areas with these OCI calls:
|
OSQL3 or OPARSE |
An OSQL3 or OPARSE call allocates a private SQL area for a SQL statement. |
|
OCLOSE |
An OCLOSE call closes a cursor and deallocates the private SQL area of its associated statement. |
See Also: Programmer's Guide to the Oracle Call Interface, Volume II: OCI Reference for more information on these calls.
With Oracle Forms, you also have some control over whether your application reuses private SQL areas. You can exercise this control in three places:
See Also: For more information on the reuse of private SQL areas by Oracle Forms, see the Oracle Forms Reference manual.
This section explains how to allocate memory for key memory structures of the shared pool. Structures are listed in order of importance for tuning.
Note: If you are using a reserved size for the shared pool, refer to "SHARED_POOL_SIZE Too Small" on page 14-27.
Because the algorithm that Oracle uses to manage data in the shared pool tends to hold dictionary data in memory longer than library cache data, tuning the library cache to an acceptable cache hit ratio often ensures that the data dictionary cache hit ratio is also acceptable. Allocating space in the shared pool for session information is only necessary if you are using the multi-threaded server architecture.
In the shared pool, some of the caches are dynamic--they grow or shrink as needed. These dynamic caches include the library cache and the data dictionary cache. Objects will be paged out of these caches if there is no more room in the shared pool. For this reason you may have to increase shared pool size if the "hot" set of data needed does not fit within it. A cache miss on the data dictionary cache or library cache is more expensive than a miss on the buffer cache. For this reason, you should allocate sufficient memory for the shared pool first.
For most applications, shared pool size is critical to Oracle performance. The shared pool holds both the data dictionary cache and the fully parsed or compiled representations of PL/SQL blocks and SQL statements. PL/SQL blocks include procedures, functions, packages, triggers and any anonymous PL/SQL blocks submitted by client-side programs. Shared pool size is less important only for applications which issue a very limited number of discrete SQL statements.
If the shared pool is too small, then the server must dedicate resources to managing the limited space available. This consumes CPU and causes contention, since restrictions must be imposed on the parallel management of the various caches. The more you use triggers and stored procedures, the larger the shared pool must be. It may even reach a size measured in hundreds of megabytes.
Since it is better to measure statistics over a specific period rather than from startup, you can determine the library cache and row cache (data dictionary cache) hit ratios from the following queries. 0The results show the miss rates for the library cache and row cache (data dictionary cache). (In general, the number of reparses reflects the library cache.)
select (sum(pins - reloads)) / sum(pins) "Lib Cache"
from v$librarycache;
select (sum(gets - getmisses - usage - fixed)) / sum(gets) "Row Cache"
from v$rowcache;
The amount of free memory in the shared pool is reported in V$SGASTAT. The instantaneous value can be reported using the query
select * from v$sgastat where name = `free memory';
If there is always free memory available within the shared pool, then increasing the size of the pool will have little or no beneficial effect. On the other hand, just because it is full does not necessarily mean that there is a problem. If the ratios discussed above are close to 1 then there is no need to increase the pool size.
Once an entry has been loaded into the shared pool it cannot be moved. This can cause the pool to become fragmented. On UNIX-based systems, you can use the DBMS_SHARED_POOL PL/SQL package, located in dbmspool.sql, to manage the shared pool. The comments in the code describe how to use the procedures within the package.
Oracle8 uses segmented codes to reduce the need for large areas of contiguous memory. For performance reasons, however, it may still be valuable for you to pin a large object in memory. Using the DBMS_SHARED_POOL package, you can keep the large objects permanently pinned in the shared pool.
Key ratios are library cache hit ratio and row cache hit ratio. If free memory is close to zero and either the library cache hit ratio or the row cache hit ratio is less than 0.95, then increase the shared pool until the ratios stop improving.
The library cache contains shared SQL and PL/SQL areas. This section tells you how to tune the library cache. Throughout this section, information about shared SQL areas and SQL statements also applies to shared PL/SQL areas and PL/SQL blocks.
Library cache misses can occur on either of two steps in the processing of a SQL statement:
If an application makes a parse call for a SQL statement and the parsed representation of the statement does not already exist in a shared SQL area in the library cache, Oracle parses the statement and allocates a shared SQL area. You may be able to reduce library cache misses on parse calls by ensuring that SQL statements can share a shared SQL area whenever possible.
If an application makes an execute call for a SQL statement and the shared SQL area containing the parsed representation of the statement has been deallocated from the library cache to make room for another statement, Oracle implicitly reparses the statement, allocates a new shared SQL area for it, and executes it. You may be able to reduce library cache misses on execution calls by allocating more memory to the library cache.
Determine whether misses on the library cache are affecting the performance of Oracle by querying the dynamic performance table V$LIBRARYCACHE.
You can monitor statistics reflecting library cache activity by examining the dynamic performance table V$LIBRARYCACHE. These statistics reflect all library cache activity since the most recent instance startup. By default, this table is only available to the user SYS and to users granted SELECT ANY TABLE system privilege, such as SYSTEM.
Each row in this table contains statistics for one type of item kept in the library cache. The item described by each row is identified by the value of the NAMESPACE column. Rows of the table with these NAMESPACE values reflect library cache activity for SQL statements and PL/SQL blocks:
Rows with other NAMESPACE values reflect library cache activity for object definitions that Oracle uses for dependency maintenance.
These columns of the V$LIBRARYCACHE table reflect library cache misses on execution calls:
|
PINS |
This column shows the number of times an item in the library cache was executed. |
|
RELOADS |
This column shows the number of library cache misses on execution steps. |
Monitor the statistics in the V$LIBRARYCACHE table over a period of time with this query:
SELECT SUM(pins) "Executions",
SUM(reloads) "Cache Misses while Executing"
FROM v$librarycache;
The output of this query might look like this:
Executions Cache Misses while Executing
---------- ----------------------------
320871 549
Examining the data returned by the sample query leads to these observations:
Total RELOADS should be near 0. If the ratio of RELOADS to PINS is more than 1%, then you should reduce these library cache misses through the means discussed in the next section.
You can reduce library cache misses by
You may be able to reduce library cache misses on execution calls by allocating additional memory for the library cache. To ensure that shared SQL areas remain in the cache once their SQL statements are parsed, increase the amount of memory available to the library cache until the V$LIBRARYCACHE.RELOADS value is near 0. To increase the amount of memory available to the library cache, increase the value of the initialization parameter SHARED_POOL_SIZE. The maximum value for this parameter depends on your operating system. This measure will reduce implicit reparsing of SQL statements and PL/SQL blocks on execution.
To take advantage of additional memory available for shared SQL areas, you may also need to increase the number of cursors permitted for a session. You can increase this limit by increasing the value of the initialization parameter OPEN_CURSORS.
Be careful not to induce paging and swapping by allocating too much memory for the library cache. The benefits of a library cache large enough to avoid cache misses can be partially offset by reading shared SQL areas into memory from disk whenever you need to access them.
See Also: "SHARED_POOL_SIZE Too Small" on page 14-27
You may be able to reduce library cache misses on parse calls by ensuring that SQL statements and PL/SQL blocks use a shared SQL area whenever possible. For two different occurrences of a SQL statement or PL/SQL block to use a shared SQL area, they must be identical according to these criteria:
For example, these statements cannot use the same shared SQL area:
SELECT * FROM emp; SELECT * FROM emp;
These statements cannot use the same shared SQL area:
SELECT * FROM emp; SELECT * FROM Emp;
For example, if the schemas of the users BOB and ED both contain an EMP table and both users issue the following statement, their statements cannot use the same shared SQL area:
SELECT * FROM emp; SELECT * FROM emp;
If both statements query the same table and qualify the table with the schema, as in the following statement, then they can use the same shared SQL area:
SELECT * FROM bob.emp;
SELECT * FROM emp WHERE deptno = :department_no; SELECT * FROM emp WHERE deptno = :d_no;
Shared SQL areas are most useful for reducing library cache misses for multiple users running the same application. Discuss these criteria with the developers of such applications and agree on strategies to ensure that the SQL statements and PL/SQL blocks of an application can use the same shared SQL areas:
For example, the following two statements cannot use the same shared area because they do not match character for character:
SELECT ename, empno FROM emp WHERE deptno = 10; SELECT ename, empno FROM emp WHERE deptno = 20;
You can accomplish the goals of these statements by using the following statement that contains a bind variable, binding 10 for one occurrence of the statement and 20 for the other:
SELECT ename, empno FROM emp WHERE deptno = :department_no;
The two occurrences of the statement can then use the same shared SQL area.
You can also increase the likelihood that SQL statements issued by different applications can share SQL areas by establishing these policies among the developers of the applications:
If you have no library cache misses, you may still be able to speed execution calls by setting the value of the initialization parameter CURSOR_SPACE_FOR_TIME. This parameter specifies when a shared SQL area can be deallocated from the library cache to make room for a new SQL statement. The default value of this parameter is FALSE, meaning that a shared SQL area can be deallocated from the library cache regardless of whether application cursors associated with its SQL statement are open. The value of TRUE means that a shared SQL area can only be deallocated when all application cursors associated with its statement are closed.
Depending on the value of CURSOR_SPACE_FOR_TIME, Oracle behaves differently when an application makes an execution call. If the value is FALSE, Oracle must take time to check that a shared SQL area containing the SQL statement is in the library cache. If the value is TRUE, Oracle need not make this check because the shared SQL area can never be deallocated while an application cursor associated with it is open. Setting the value of the parameter to TRUE saves Oracle a small amount of time and may slightly improve the performance of execution calls. This value also prevents the deallocation of private SQL areas until associated application cursors are closed.
Do not set the value of CURSOR_SPACE_FOR_TIME to TRUE if there are library cache misses on execution calls. Such library cache misses indicate that the shared pool is not large enough to hold the shared SQL areas of all concurrently open cursors. If the value is TRUE and there is no space in the shared pool for a new SQL statement, the statement cannot be parsed and Oracle returns an error saying that there is no more shared memory. If the value is FALSE and there is no space for a new statement, Oracle deallocates an existing shared SQL area. Although deallocating a shared SQL area results in a library cache miss later, it is preferable to an error halting your application because a SQL statement cannot be parsed.
Do not set the value of CURSOR_SPACE_FOR_TIME to TRUE if the amount of memory available to each user for private SQL areas is scarce. This value also prevents the deallocation of private SQL areas associated with open cursors. If the private SQL areas for all concurrently open cursors fills the user's available memory so that there is no space to allocate a private SQL area for a new SQL statement, the statement cannot be parsed and Oracle returns an error indicating that there is not enough memory.
If an application repeatedly issues parse calls on the same set of SQL statements, the reopening of the session cursors can affect system performance. Session cursors can be stored in a session cursor cache. This feature can be particularly useful for applications designed using Oracle Forms because switching between forms closes all session cursors associated with a form.
Oracle uses the shared SQL area to determine if more than three parse requests have been issued on a given statement. If so, Oracle assumes the session cursor associated with the statement should be cached and moves the cursor into the session cursor cache. Subsequent requests to parse that SQL statement by the same session will then find the cursor in the session cursor cache.
To enable caching of session cursors, you must set the initialization parameter SESSION_CACHED_CURSORS. This parameter is a positive integer that specifies the maximum number of session cursors kept in the cache. A least recently used (LRU) algorithm ages out entries in the session cursor cache to make room for new entries when needed.
You can also enable the session cursor cache dynamically with the ALTER SESSION SET SESSION_CACHED_CURSORS command.
To determine whether the session cursor cache is sufficiently large for your instance, you can examine the session statistic "session cursor cache hits" in the V$SESSTAT view. This statistic counts the number of times a parse call found a cursor in the session cursor cache. If this statistic is a relatively low percentage of the total parse call count for the session, you should consider setting SESSION_CACHED_CURSORS to a larger value.
This section describes how to monitor data dictionary cache activity and reduce misses.
Determine whether misses on the data dictionary cache are affecting the performance of Oracle. You can examine cache activity by querying the V$ROWCACHE table as described in the following sections.
Misses on the data dictionary cache are to be expected in some cases. Upon instance startup, the data dictionary cache contains no data, so any SQL statement issued is likely to result in cache misses. As more data is read into the cache, the likelihood of cache misses should decrease. Eventually the database should reach a "steady state" in which the most frequently used dictionary data is in the cache. At this point, very few cache misses should occur. To tune the cache, examine its activity only after your application has been running.
Statistics reflecting data dictionary activity are kept in the dynamic performance table V$ROWCACHE. By default, this table is only available to the user SYS and to users granted SELECT ANY TABLE system privilege, such as SYSTEM.
Each row in this table contains statistics for a single type of the data dictionary item. These statistics reflect all data dictionary activity since the most recent instance startup. These columns in the V$ROWCACHE table reflect the use and effectiveness of the data dictionary cache:
Use the following query to monitor the statistics in the V$ROWCACHE table over a period of time while your application is running:
SELECT SUM(gets) "Data Dictionary Gets",
SUM(getmisses) "Data Dictionary Cache Get Misses"
FROM v$rowcache;
The output of this query might look like this:
Data Dictionary Gets Data Dictionary Cache Get Misses
-------------------- --------------------------------
1439044 3120
Examining the data returned by the sample query leads to these observations:
Examine cache activity by monitoring the sums of the GETS and GETMISSES columns. For frequently accessed dictionary caches, the ratio of total GETMISSES to total GETS should be less than 10% or 15%. If the ratio continues to increase above this threshold while your application is running, you should consider increasing the amount of memory available to the data dictionary cache. To increase the memory available to the cache, increase the value of the initialization parameter SHARED_POOL_SIZE. The maximum value for this parameter varies depending on your operating system.
In the multi-threaded server architecture, Oracle stores session information in the shared pool rather than in the memory of user processes. Session information includes private SQL areas. If you are using the multi-threaded server architecture, you may need to make your shared pool larger to accommodate session information. You can increase the size of the shared pool by increasing the value of the SHARED_POOL_SIZE initialization parameter. This section discusses measuring the size of session information by querying the dynamic performance table V$SESSTAT.
With very high numbers of connected users, the only way to reduce memory usage to an acceptable level may be to go to three-tier connections. This is a by-product of using a TP monitor. This is only feasible with a pure transactional model, since no locks or uncommitted DML can be held between calls. Oracle's multi-threaded server (MTS) is much less restrictive of the application design than a TP monitor. It dramatically reduces operating system process count, because it normally requires only 5 threads per CPU. It still requires a minimum of around 300K bytes of context per connected user.
Oracle collects statistics on total memory used by a session and stores them in the dynamic performance table V$SESSTAT. By default, this table is only available to the user SYS and to users granted SELECT ANY TABLE system privilege, such as SYSTEM. These statistics are useful for measuring session memory use:
To find the value, query V$STATNAME as described in "Technique 3" on page 14-10.
You can use this query to decide how much larger to make the shared pool if you are using the multi-threaded server. Issue these queries while your application is running:
SELECT SUM(value) || ' bytes' "Total memory for all sessions"
FROM v$sesstat, v$statname
WHERE name = 'session uga memory'
AND v$sesstat.statistic# = v$statname.statistic#; SELECT SUM(value) || ' bytes' "Total max mem for all sessions"
FROM v$sesstat, v$statname
WHERE name = 'session uga memory max'
AND v$sesstat.statistic# = v$statname.statistic#;
These queries also select from the dynamic performance table V$STATNAME to obtain internal identifiers for session memory and max session memory. The results of these queries might look like this:
Total memory for all sessions
-----------------------------
157125 bytes Total max mem for all sessions
------------------------------
417381 bytes
The result of the first query indicates that the memory currently allocated to all sessions is 157,125 bytes. This value is the total memory whose location depends on how the sessions are connected to Oracle. If the sessions are connected to dedicated server processes, this memory is part of the memories of the user processes. If the sessions are connected to shared server processes, this memory is part of the shared pool. The result of the second query indicates the sum of the maximum sizes of the memories for all sessions is 417,381 bytes. The second result is greater than the first because some sessions have deallocated memory since allocating their maximum amounts.
You can use the result of either of these queries to determine how much larger to make the shared pool if you use the multi-threaded server. The first value is likely to be a better estimate than the second unless nearly all sessions are likely to reach their maximum allocations at the same time.
On busy systems the database may have difficulty finding a contiguous piece of memory to satisfy a large request for memory. This search may disrupt the behavior of the shared pool, leading to fragmentation and thus affecting performance.
The DBA can reserve memory within the shared pool to satisfy large allocations during operations such as PL/SQL compilation and trigger compilation. Smaller objects will not fragment the reserved list, helping to ensure that the reserved list will have large contiguous chunks of memory. Once the memory allocated from the reserved list is freed, it returns to the reserved list.
The size of the reserved list, as well as the minimum size of the objects that can be allocated from the reserved list are controlled by two initialization parameters: SHARED_POOL_RESERVED_SIZE and SHARED_POOL_RESERVED_MIN_ALLOC.
SHARED_POOL_RESERVED_SIZE controls the amount of SHARED_POOL_SIZE reserved for large allocations. The fixed view V$SHARED_POOL_RESERVED helps you tune these parameters. Begin this tuning only after performing all other shared pool tuning on the system.
SHARED_POOL_RESERVED_MIN_ALLOC controls allocation for the reserved memory. To create a reserved list, SHARED_POOL_RESERVED_SIZE must be greater than SHARED_POOL_RESERVED_MIN_ALLOC. Only allocations larger than SHARED_POOL_RESERVED_POOL_MIN_ALLOC can allocate space from the reserved list if a chunk of memory of sufficient size is not found on the shared pool's free lists. The default value of SHARED_POOL_RESERVED_MIN_ALLOC should be adequate for most systems.
The ABORTED_REQUEST_THRESHOLD procedure, in the package DBMS_SHARED_POOL, allows users to limit the size of allocations allowed to flush the shared pool if the free lists cannot satisfy the request size. The database incrementally flushes unused objects from the shared pool until there is sufficient memory to satisfy the allocation request. In most cases, this frees enough memory for the allocation to complete successfully. If the database has flushed all objects currently not in use on the system without finding a large enough piece of contiguous memory, an error will occur. Flushing all objects, however, will affect other users on the system, and impact performance. The ABORTED_REQUEST_THRESHOLD procedure allows the DBA to localize the error to the process that could not allocate memory.
As an initial value, make SHARED_POOL_RESERVED_SIZE 10% of the SHARED_POOL_SIZE. For most systems, this value should be sufficient, if you have already done some tuning of the shared pool. The default value for SHARED_POOL_RESERVED_MIN_ALLOC is usually adequate. If you increase this value, then the database will allow fewer allocations from the reserved list and will request more memory from the shared pool list.
Ideally, you should make SHARED_POOL_RESERVED_SIZE large enough to satisfy any request for memory on the reserved list without flushing objects from the shared pool. The amount of operating system memory, however, may constrain the size of the SGA. Making the SHARED_POOL_RESERVED_SIZE large enough to satisfy any request for memory is, therefore, not a feasible goal.
On a system with ample free memory to increase the SGA, the goal is to have REQUEST_MISSES = 0. If the system is constrained for OS memory, the goal is as follows:
If neither of these goals is met, increase SHARED_POOL_RESERVED_SIZE. Also increase SHARED_POOL_SIZE by the same amount, since the reserved list is taken from the shared pool.
See Also: Oracle8 Server Reference Manual for details on setting the LARGE_POOL_SIZE and LARGE_POOL_MIN_ALLOC parameters.
The reserved pool is too small when:
and at least one of the following is true:
You have two options, depending on SGA size constraints:
The first option will increase the amount of memory available on the reserved list without having an impact on users not allocating memory from the reserved list. The second options reduces the number of allocations allowed to use memory from the reserved list; doing so, however, will increase the normal shared pool, which may have an impact on other users on the system.
Too much memory may have been allocated to the reserved list. This may be the case if:
You have two options:
The V$SHARED_POOL_RESERVED fixed table can also indicate when SHARED_POOL_SIZE is too small. This may be the case if:
Then you have two options, if you have enabled the reserved list:
Otherwise, you could
You can use or bypass the Oracle buffer cache for particular operations. Note that Oracle bypasses the buffer cache for sorting and parallel reads. For those operations which do use the buffer cache, this section explains:
After tuning private SQL and PL/SQL areas and the shared pool, you can devote the remaining available memory to the buffer cache. It may be necessary to repeat the steps of memory allocation after the initial pass through the process. Subsequent passes allow you to make adjustments in earlier steps based on changes in later steps. For example, if you increase the size of the buffer cache, you may need to allocate more memory to Oracle to avoid paging and swapping.
Physical I/O both takes significant time, typically in excess of 15 msec, and also increases the CPU resource required owing to the path length in device drivers and operating system event schedulers. The goal is therefore to reduce this overhead as far as possible by making it more likely that the required block will be in memory. The extent to which this has been achieved is measured using the cache hit ratio. Within Oracle this term applies specifically to the database buffer cache.
Oracle collects statistics that reflect data access and stores them in the dynamic performance table V$SYSSTAT. By default, this table is only available to the user SYS and to users such as SYSTEM which have been granted SELECT ANY TABLE system privilege. (Information in the V$SYSSTAT table can also be obtained through SNMP.)
These statistics are useful for tuning the buffer cache:
Monitor these statistics as follows over a period of time while your application is running:
SELECT name, value
FROM v$sysstat
WHERE name IN ('db block gets', 'consistent gets',
'physical reads');
The output of this query might look like this:
NAME VALUE
------------------------------------------------------ ----------
db block gets 85792
consistent gets 278888
physical reads 23182
Calculate the hit ratio for the buffer cache with this formula:
Hit Ratio = 1 - ( physical reads / (db block gets + consistent gets) )
Based on the statistics obtained by the example query, the buffer cache hit ratio is 94%.
When looking at the cache hit ratio, bear in mind that blocks encountered during a "long" full table scan are not put to the head of the LRU list; therefore repeated scanning will not cause the blocks to be cached.
Note: The CACHE_SIZE_THRESHOLD parameter sets the maximum size of a table to be cached, in blocks; it is equal to one tenth of DB_BLOCK_BUFFERS. On a per-table basis, this parameter enables you to determine which tables should and should not be cached.
The solution lies at the design or implementation level, in that repeated scanning of the same large table is rarely the most efficient solution to the problem. It may be better to perform all of the processing in a single pass, even if this means that the overnight batch suite can no longer be implemented as a SQL*Plus script which contains no PL/SQL.
Production sites running with thousands or tens of thousands of buffers are rarely using memory effectively. In any large database running an OLTP application, in any given unit of time, most rows will be accessed either one or zero times. On this basis there is little point in keeping the row (or the block which contains it) in memory for very long following its use.
Finally, the relationship between cache hit ratio and number of buffers is far from a smooth distribution. When tuning the buffer pool, avoid the use of additional buffers which contribute little or nothing to the cache hit ratio. As illustrated in the following figure, there are only narrow bands of values of DB_BLOCK_BUFFERS which are worth considering. The effect is not completely intuitive.
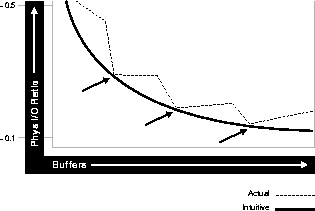
Attention: A common mistake is to continue increasing the value of DB_BLOCK_BUFFERS even when the last increase made no difference at all. This is because you are doing full table scans and other operations that do not even use the buffer pool.
As a rule of thumb, increase DB_BLOCK_BUFFERS while:
The CATPARR.SQL script creates the view V$BH, which shows the file number and block number of blocks that currently reside within the SGA. Although CATPARR.SQL is primarily intended for use in parallel server environments, you can run it as SYS even if the instance is always started in exclusive mode.
Perform a query like the following:
SELECT file#, COUNT(block#), COUNT (DISTINCT file# || block#)
FROM V$BH
GROUP BY file#
With a reasonable number of buffers (2000, for example) and with DB_BLOCK_LRU_EXTENDED_STATISTICS set no larger than the buffer pool, then the data obtained from the use of these parameters over perhaps one shift of OLTP usage more than compensates for the CPU cost incurred. Non-selective lists of values may distort the picture. You can rectify this by using the parameters DB_BLOCK_LRU_STATISTICS and DB_BLOCK_LRU_EXTENDED_STATISTICS.
This is difficult to do manually, but scripts exist which take the effort out and report a histogram like the following example:
| Buffers | Cache Hit Ratio | |
|
1 to |
200 |
0.62 |
|
201 to |
400 |
0.77 |
|
401 to |
600 |
0.82 |
|
601 to |
800 |
0.86 |
|
801 to |
1000 |
0.87 |
|
1001 to |
1200 |
0.88 |
|
1201 to |
1400 |
0.89 |
|
1401 to |
1600 |
0.89 |
|
1601 to |
1800 |
0.89 |
|
1801 to |
2000 |
0.89 |
Running such scripts involves some performance overhead, but does remove the guesswork.
If your hit ratio is low, perhaps less than 60% or 70%, then you may want to increase the number of buffers in the cache to improve performance. To make the buffer cache larger, increase the value of the initialization parameter DB_BLOCK_BUFFERS.
Oracle can collect statistics that estimate the performance gain that would result from increasing the size of your buffer cache. With these statistics, you can estimate how many buffers to add to your cache.
The virtual table SYS.X$KCBRBH contains statistics that estimate the performance of a larger cache. Each row in the table reflects the relative performance value of adding a buffer to the cache. This table can only be accessed by the user SYS. The following are the columns of the X$KCBRBH table:
For example, in the first row of the table, the INDX value is 0 and the COUNT value is the number of cache hits to be gained by adding the first additional buffer to the cache. In the second row, the INDX value is 1 and the COUNT value is the number of cache hits for the second additional buffer.
The collection of statistics in the X$KCBRBH table is controlled by the initialization parameter DB_BLOCK_LRU_EXTENDED_STATISTICS. The value of this parameter determines the number of rows in the X$KCBRBH table. The default value of this parameter is 0, which means the default behavior is not to collect statistics.
To enable the collection of statistics in the X$KCBRBH table, set the value of DB_BLOCK_LRU_EXTENDED_STATISTICS. For example, if you set the value of the parameter to 100, Oracle will collect 100 rows of statistics, each row reflecting the addition of one buffer, up to 100 extra buffers.
Collecting these statistics incurs some performance overhead, which is proportional to the number of rows in the table. To avoid this overhead, collect statistics only when you are tuning the buffer cache and disable the collection of statistics when you are finished tuning.
From the information in the X$KCBRBH table, you can predict the potential gains of increasing the cache size. For example, to determine how many more cache hits would occur if you added 20 buffers to the cache, query the X$KCBRBH table with the following SQL statement:
SELECT SUM(count) ach
FROM sys.x$kcbrbh
WHERE indx < 20;
You can also determine how these additional cache hits would affect the hit ratio. Use the following formula to calculate the hit ratio based on the values of the statistics db block gets, consistent gets, and physical reads and the number of additional cache hits (ACH) returned by the query:
Hit Ratio = 1 - (physical reads - ACH / (db block gets + consistent gets) )
Another way to examine the X$KCBRBH table is to group the additional buffers in large intervals. You can query the table with a SQL statement similar to this:
SELECT 250*TRUNC(indx/250)+1||' to '||250*(TRUNC(indx/250)+1)
"Interval", SUM(count) "Buffer Cache Hits"
FROM sys.x$kcbrbh
GROUP BY TRUNC(indx/250);
The result of this query might look like
Interval Buffer Cache Hits
--------------- --------------------
1 to 250 16080
251 to 500 10950
501 to 750 710
751 to 1000 23140
where:
|
INTERVAL |
Is the interval of additional buffers to be added to the cache. |
|
BUFFER CACHE HITS |
Is the number of additional cache hits to be gained by adding the buffers in the INTERVAL column. |
Examining the query output leads to these observations:
Based on these observations, decide how many buffers to add to the cache. In this case, you may make these decisions:
If your hit ratio is high, your cache is probably large enough to hold your most frequently accessed data. In this case, you may be able to reduce the cache size and still maintain good performance. To make the buffer cache smaller, reduce the value of the initialization parameter DB_BLOCK_BUFFERS. The minimum value for this parameter is 4. You can apply any leftover memory to other Oracle memory structures.
Oracle can collect statistics to predict buffer cache performance based on a smaller cache size. Examining these statistics can help you determine how small you can afford to make your buffer cache without adversely affecting performance.
The virtual table SYS.X$KCBCBH contains the statistics that estimate the performance of a smaller cache. The X$KCBCBH table is similar in structure to the X$KCBRBH table. This table can only be accessed by the user SYS. The following are the columns of the X$KCBCBH table:
|
INDX |
The potential number of buffers in the cache. |
|
COUNT |
The number of cache hits attributable to buffer number INDX. |
The number of rows in this table is equal to the number of buffers in your buffer cache. Each row in the table reflects the number of cache hits attributed to a single buffer. For example, in the second row, the INDX value is 1 and the COUNT value is the number of cache hits for the second buffer. In the third row, the INDX value is 2 and the COUNT value is the number of cache hits for the third buffer.
The first row of the table contains special information. The INDX value is 0 and the COUNT value is the total number of blocks moved into the first buffer in the cache.
The collection of statistics in the X$KCBCBH table is controlled by the initialization parameter DB_BLOCK_LRU_STATISTICS. The value of this parameter determines whether Oracle collects the statistics. The default value for this parameter is FALSE, which means that the default behavior is not to collect statistics.
To enable the collection of statistics in the X$KCBCBH table, set the value of DB_BLOCK_LRU_STATISTICS to TRUE.
Collecting these statistics incurs some performance overhead. To avoid this overhead, collect statistics only when you are tuning the buffer cache and disable the collection of statistics when you are finished tuning.
From the information in the X$KCBCBH table, you can predict the number of additional cache misses that would occur if the number of buffers in the cache were reduced. If your buffer cache currently contains 100 buffers, you may want to know how many more cache misses would occur if it had only 90. To determine the number of additional cache misses, query the X$KCBCBH table with the SQL statement:
SELECT SUM(count) acm
FROM sys.x$kcbcbh
WHERE indx >= 90;
You can also determine the hit ratio based on this cache size. Use the following formula to calculate the hit ratio based on the values of the statistics db block gets, consistent gets, and physical reads and the number of additional cache misses (ACM) returned by the query:
Hit Ratio = 1 - ( physical reads + ACM / (db block gets + consistent gets) )
Another way to examine the X$KCBCBH table is to group the buffers in intervals. For example, if your cache contains 100 buffers, you may want to divide the cache into four 25-buffer intervals. You can query the table with a SQL statement similar to this one:
SELECT 25*TRUNC(indx/25)+1||' to '||25*(TRUNC(indx/25)+1)
"Interval", SUM(count) "Buffer Cache Hits"
FROM sys.x$kcbcbh
WHERE indx > 0 GROUP BY TRUNC(indx/25);
Note that the WHERE clause prevents the query from collecting statistics from the first row of the table. The result of this query might look like
Interval Buffer Cache Hits
--------------- --------------------
1 to 25 1900
26 to 50 1100
51 to 75 1360
76 to 100 230
where:
|
INTERVAL |
Is the interval of buffers in the cache. |
|
BUFFER CACHE HITS |
Is the number of cache hits attributable to the buffers in the INTERVAL column. |
Examining the query output leads to these observations:
Based on these observations, decide whether to reduce the size of the cache. In this case, you may make these decisions:
This section covers:
Because schema objects are referenced with varying usage patterns their cache behavior may be quite different. Multiple buffer pools enable you to address these differences. A "keep" buffer pool can be used to maintain an object in the buffer cache, and a "recycle" buffer pool can be used to prevent an object from taking up unnecessary space in the cache. If an object is allocated to a cache then all blocks from that object are placed in that cache. A default cache is always maintained for objects which have not been assigned to one of the buffer pools.
Each buffer pool in Oracle8 is comprised of a number of working sets. A different number of sets can be allocated for each buffer pool. All sets use the same LRU replacement policy. A strict LRU aging policy provides very good hit rates in most cases, but it can sometimes be improved by providing some hints.
The main problem with LRU occurs when a very large segment is accessed frequently in a random fashion. Here, "very large" means large compared to the size of the cache. Any single segment that accounts for a substantial portion (more than 10%) of the non-sequential physical reads is probably one of these segments. The random reads to the large segment can cause buffers that contain data for other segments to be aged out of the cache. The large segment ends up consuming a large percentage of the cache, but does not benefit from the cache.
Very frequently accessed segments are not affected by the large segment reads since their buffers are warmed frequently enough that they do not age out of the cache. The main trouble occurs with "warm" segments that are not accessed frequently enough to survive the buffer flushing caused by the large segment reads.
There are two approaches to solving this problem. One is to move the large segment into a separate "recycle" cache so that it does not disturb the other segments. The recycle cache should be smaller than the default cache and should reuse buffers more quickly than the default cache.
The other approach is to move the small warm segments into a separate "keep" cache that is not used at all for large segments. The keep cache can be sized so that there are very few misses in the cache. You can make the response times for certain queries more predictable by putting the segments accessed by the queries in the keep cache to make sure that they are never aged out.
When you examine system I/O performance you should determine whether or not multiple buffer pools would be advantageous. A database administrator and application writer should analyze the schema and determine whether or not multiple buffer pools would be advantageous. If there are small tables that are frequently accessed which have quick response time requirement then a keep cache should be considered. Very large tables with random I/O are good candidates for a recycle cache.
Use the following steps to determine the percentage of the cache used by an individual object at a given point in time:
SELECT data_object_id, object_type FROM user_objects
WHERE object_name = '<segment_name>';
Since two objects can have the same name (if they are different types of object), the OBJECT_TYPE column can be used to identify the object of interest. If the object is owned by another user, then use the view DBA_OBJECTS or ALL_OBJECTS.
select count(*) buffers from x$bh where obj = <data_object_id>;
where data_object_id is from above.
select value "total buffers" from v$parameter
where name = 'db_block_buffers';
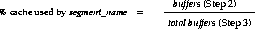
Note: This technique only works for a single segment; for a partitioned object, the query must be run for each partition.
If the number of local block gets equals the number of physical reads for statements involving such objects, consider employing a recycle cache because of the limited usefulness of the buffer cache for the objects.
When you partition your buffer cache into multiple buffer pools, each buffer pool can be used for blocks from objects that are accessed in different ways. If the blocks of a particular object are likely to be reused, then you should keep that object in the buffer cache so that the next use of the block will not require another disk I/O operation. Conversely, if a block will probably not be reused within a reasonable period of time then there is no reason to keep it in the cache; the block should be discarded to make room for a more popular block.
By properly allocating objects to appropriate buffer pools, you can:
You can create multiple buffer pools for each database instance. The same set of buffer pools need not be defined for each instance of the database. Between instances a buffer pool may be different sizes or not defined at all. Each instance should be tuned separately.
You can define each buffer pool using the BUFFER_POOL_name initialization parameter. You can specify two attributes for each buffer pool: the number of buffers in the buffer pool and the number of LRU latches allocated to the buffer pool.
The initialization parameters used to define buffer pools are:
The size of each buffer pool is subtracted from the total number of buffers defined for the entire buffer cache (that is, the value of the DB_BLOCK_BUFFERS parameter). The aggregate number of buffers in all of the buffer pools cannot, therefore, exceed this value. Likewise, the number of LRU latches allocated to each buffer pool is taken from the total number allocated to the instance via the DB_BLOCK_LRU_LATCHES parameter. If either constraint is violated then an error occurs and the database is not mounted.
The minimum number of buffers that must be allocated to each buffer pool is 50 times the number of LRU latches. For example, if a buffer pool has 3 LRU latches then it must have at least 150 buffers.
Three buffer pools are defined in Oracle8: KEEP, RECYCLE, and DEFAULT. The default buffer pool always exists. It is equivalent to the single buffer cache in Oracle7. The size of the default buffer pool and number of working sets assigned to the default buffer pool are not defined explicitly. Rather, each value is inferred from the total number allocated minus the number allocated to every other buffer pool. There is no requirement that any buffer pool be defined for another buffer pool to be used.
This section describes how to establish a default buffer pool for an object. All blocks for the object will go in the specified buffer pool.
The BUFFER_POOL clause is used to define the default buffer pool for an object. This clause is valid for CREATE and ALTER table, cluster, and index DDL statements. The buffer pool name is case insensitive. The blocks from an object without an explicitly set buffer pool go into the DEFAULT buffer pool.
If a buffer pool is defined for a partitioned table or index then each partition of the object inherits the buffer pool from the table or index definition unless overridden with a specific buffer pool.
When the default buffer pool of an object is changed using the ALTER statement, all buffers that currently contain blocks of the altered segment remain in the buffer pool they were in before the ALTER statement. Newly loaded blocks and any blocks that have aged out and are reloaded will go into the new buffer pool.
The syntax is:
BUFFER_POOL { KEEP | RECYCLE | DEFAULT }
For example,
BUFFER_POOLKEEP
or
BUFFER_POOLRECYCLE
The following DDL statements accept the buffer pool clause:
A buffer pool is not permitted for a clustered table. The buffer pool for a clustered table is specified at the cluster level.
For an index-organized table, a buffer pool can be defined on both the index and the overflow segment.
For a partitioned table, a buffer pool can be defined on each partition. The buffer pool is specified as a part of the storage clause for each partition.
For example:
CREATE TABLEtable_name(col_1number,col_2number)
PARTITION BY RANGE(col_1)
(PARTITION ONE VALUES LESS THAN(10)
STORAGE(INITIAL10kBUFFER_POOL RECYCLE),
PARTITION TWO VALUES LESS THAN(20)STORAGE(BUFFER_POOL KEEP));
For a global or local partitioned index, a buffer pool can be defined on each partition.
CREATE CLUSTER cluster name ... STORAGE (buffer pool clause)
ALTER TABLE table name ... STORAGE (buffer pool clause)
A buffer pool can be defined during a simple alter table as well as modify partition, move partition, add partition, and split partition (for both new partitions).
A buffer pool can be defined during a simple alter index as well as rebuild, modify partition, split partition (for both new partitions), and rebuild partition.
The following dictionary views have a BUFFER POOL column which indicates the default buffer pool for the given object.
USER_CLUSTERS, ALL_CLUSTERS, DBA_CLUSTERS,
USER_INDEXESALL_INDEXES, DBA_INDEXES,
USER_SEGMENTSDBA_SEGMENTS,
USER_TABLESUSER_OBJECT_TABLES, USER_ALL_TABLES,
ALL_TABLESALL_OBJECT_TABLES, ALL_ALL_TABLES,
DBA_TABLESDBA_OBJECT_TABLES, DBA_ALL_TABLES
USER_PART_TABLES, ALL_PART_TABLES, DBA_PART_TABLES,
USER_PART_INDEXESALL_PART_INDEXES, DBA_PART_INDEXES,
USER_TAB_PARTITIONSALL_TAB_PARTITIONS, DBA_TAB_PARTITIONS,
USER_IND_PARTITIONSALL_IND_PARTITIONS, DBA_IND_PARTITIONS
The views V$BUFFER_POOL and GV$BUFFER_POOL describe the buffer pools allocated on the local instance and entire database, respectively.
This section explains how to size the keep and recycle buffer pools.
The goal of the keep buffer pool is to retain objects in memory, thus avoiding I/O operations. The size of the keep buffer pool therefore depends on the objects that you wish to keep in the buffer cache. You can compute an approximate size for the keep buffer pool by adding together the sizes of all objects dedicated to this pool. Use the ANALYZE command to obtain the size of each object. While the ESTIMATE option provides a rough measurement of sizes, the COMPUTE STATISTICS option should be used, if feasible, to get the most accurate value possible.
The buffer pool hit ratio can be determined using the formula: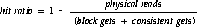
where the values of physical reads, block gets, and consistent gets can be obtained for the keep buffer pool from the following query:
SELECT PHYSICAL_READS, BLOCK_GETS, CONSISTENT_GETS
FROM V$BUFFER_POOL WHERE NAME = `KEEP';
The keep buffer pool will only have a 100% hit ratio after the buffers have been loaded into the buffer pool. The hit ratio should only be computed, therefore, after the system has been running for a while and has achieved steady state performance. Calculate the hit ratio by taking two snapshots of system performance using the above query and using the delta values of physical reads, block gets, and consistent gets.
Furthermore, a 100% buffer pool hit ratio may not be necessary. Often you can decrease the size of your keep buffer pool by quite a bit and still maintain a high hit ratio. Those blocks can be allocated to other buffer pools.
Note: If an object grows in size, then it may no longer fit in the keep buffer pool. You will begin to lose blocks out of the cache.
Remember, each object kept in memory results in a trade-off: while it is beneficial to keep frequently accessed blocks in the cache, retaining infrequently used blocks results in less space being available for other, more active, blocks.
The goal of the recycle buffer pool is to eliminate blocks from memory as soon as they are no longer needed. If an application accesses the blocks of a very large object in a random fashion then there is little chance of reusing a block stored in the buffer pool before it is aged out. This is true regardless of the size of the buffer pool (given the constraint of the amount of available physical memory). Because of this, the object's blocks should not be cached; those cache buffers can be allocated to other objects.
Be careful, however, not to discard blocks from memory too quickly. If the buffer pool is too small then it is possible for a block to age out of the cache before the transaction or SQL statement has completed execution. For example, an application may select a value from a table, use the value to process some data, and then update the tuple. If the block is removed from the cache after the select statement then it must be read from disk again to perform the update. The block needs to be retained for the duration of the user transaction.
By executing statements with a SQL statement tuning tool such as Oracle Trace or with the SQL trace facility enabled and running TKPROF on the trace files, you can get a listing of the total number of data blocks physically read from disk. This is given in the "disk" column in the TKPROF output. The number of disk reads for a particular SQL statement should not exceed the number of disk reads of the same SQL statement with all objects allocated from the default buffer pool.
Two other statistics can be used to determine if the recycle buffer pool is too small. If the "free buffer waits" statistic ever becomes high then the pool is probably too small. Likewise, the number of "log file sync" wait events will increase. One way to size the recycle buffer pool is to run the system with the recycle buffer pool disabled. At steady state the number of buffers in the default buffer pool that are being consumed by segments that would normally go in the recycle buffer pool can be divided by four. That number can be used to size the recycle cache.
A good candidate for a segment to put into the recycle buffer pool is a segment that is at least twice the size of the default buffer pool and has incurred at least a few percent of the total IOs in the system.
A good candidate for a segment to put into the keep pool is a segment that is smaller than 10 percent of the size of the default buffer pool and has incurred at least one percent of the total IOs in the system.
The trouble with these rules is that it can be difficult to determine the number of IOs per segment if there is more than one segment in a tablespace. One way to solve this problem is to sample the IOs that occur over a period of time by selecting from V$SESSION_WAIT to determine a statistical distribution of IOs per segment.
Another option is to look at the positions of the blocks of a segment in the buffer cache. In particular the ratio of the count of blocks for a segment in the hot half of the cache to the count in the cold half for the same segment can give a pretty good indication of which segments are hot and which are not. If the ratio for a segment is close to 1, then buffers for that segment are not frequently heated and the segment may be a good candidate for the recycle cache. If the ratio is a high number (perhaps 3) then buffers are frequently heated and the segment might be a good candidate for the keep cache.
LRU latches are used to regulate the least recently used (LRU) buffer lists used by the buffer cache. If there is latch contention then processes are waiting and spinning before obtaining the latch.
The overall number of latches in the database instance can be set using the DB_BLOCK_LRU_LATCHES parameter. When each buffer pool is defined, a number of these LRU latches can be reserved for the buffer pool. The buffers of a buffer pool are divided evenly between the LRU latches of the buffer pool.
To determine if your system is experiencing latch contention, begin by determining whether there is LRU latch contention for any individual latch.
SELECTchild#,sleeps/getsratio
FROMV$LATCH_CHILDREN
WHEREname=`cachebufferslruchain';
The miss ratio for each LRU latch should be less than 1%. A ratio above 1% for any particular latch is indicative of LRU latch contention and should be addressed. You can determine the buffer pool to which the latch is associated with the following query:
SELECTnameFROMV$BUFFER_POOL
WHERElo_setid<=child_latch_number
ANDhi_setid>=child_latch_number;
where child_latch_number is the child# from the previous query.
You can alleviate LRU latch contention by increasing the overall number of latches in the system and also the number of latches allocated to the buffer pool indicated in the second query.
If large sorts occur frequently, consider increasing the value of the parameter SORT_AREA_SIZE with either or both of two goals in mind:
Large sort areas can be used effectively if you combine a large SORT_AREA_SIZE with a minimal SORT_AREA_RETAINED_SIZE. If memory is not released until the user disconnects from the database, large sort work areas could cause problems. The parameter SORT_AREA_RETAINED_SIZE lets the DBA specify the level down to which memory should be released as soon as possible following the sort. Set this parameter to zero if large sort areas are being used in a system with many simultaneous users.
Note that SORT_AREA_RETAINED_SIZE is maintained for each sort operation in a query. Thus if 4 tables are being sorted for a sort merge, Oracle maintains 4 areas of SORT_AREA_RETAINED_SIZE.
See Also: "Chapter 19, "Tuning Parallel Execution"
After resizing your Oracle memory structures, re-evaluate the performance of the library cache, the data dictionary cache, and the buffer cache. If you have reduced the memory consumption of any one of these structures, you may want to allocate more memory to another structure. For example, if you have reduced the size of your buffer cache, you may now want to take advantage of the additional available memory by using it for the library cache.
Tune your operating system again. Resizing Oracle memory structures may have changed Oracle memory requirements. In particular, be sure paging and swapping is not excessive. For example, if the size of the data dictionary cache or the buffer cache has increased, the SGA may be too large to fit into main memory. In this case, the SGA could be paged or swapped.
While reallocating memory, you may determine that the optimum size of Oracle memory structures requires more memory than your operating system can provide. In this case, you may improve performance even further by adding more memory to your computer.
If the overriding performance problem is that the server simply does not have enough memory to run the application as currently configured, and the application is logically a single application (that is, it cannot readily be segmented or distributed across multiple servers), then there are only two possible solutions:
The most dramatic reductions in server memory usage will always come from reducing the number of database connections, which can in turn resolve issues concerned with the number of open network sockets and the number of operating system processes. However in order to reduce the number of connections without reducing the number of users, then the connections which remain have to be shared. This forces the user processes to adhere to a paradigm in which every (request) message sent to the database describes a complete or atomic transaction.
Writing applications to conform to this model is not necessarily either restrictive or difficult, but it is most certainly different. Conversion of an existing application, such as an Oracle Forms suite, to conform is not normally possible without a complete rewrite.
The Oracle multi-threaded server (MTS) represents a compromise solution which is highly effective at reducing the number of operating system processes on the server, but less effective in reducing the overall memory requirement. Use of MTS has no effect on the number of network connections.
Shared connections are possible in an Oracle Forms environment by using an intermediate server which is also a client, and using the dbms_pipe mechanism to transmit atomic requests from the user's individual connection on the intermediate server to a shared daemon in the intermediate server. This in turn owns a connection to the central server.