Release 8.1.5
A67778-01
Library |
Product |
Contents |
Index |
| Oracle8i Parallel Server Concepts and Administration Release 8.1.5 A67778-01 |
|
![]()
![]()
There is an old network saying: Bandwidth problems can be cured with money. Latency problems are harder because the speed of light is fixed--you can't bribe God.
To attain speedup and scaleup, you must effectively implement parallel processing and parallel database technology. This means designing and building your system for parallel processing from the start. This chapter covers the following issues:
Successful implementation of parallel processing and parallel database requires optimal scalability on four levels:
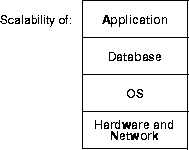
Interconnects are key to hardware scalability. That is, every system must have some means of connecting the CPUs, whether this is a high speed bus or a low speed Ethernet connection. Bandwidth and latency of the interconnect then determine the scalability of the hardware.
Most interconnects have sufficient bandwidth. A high bandwidth may, in fact, disguise high latency.
Hardware scalability depends heavily on very low latency. Lock coordination traffic communication is characterized by a large number of very small messages among the LMD processes.
Consider the example of a highway and the difference between conveying a hundred passengers on a single bus, compared to one hundred individual cars. In the latter case, efficiency depends largely upon the capacity for cars to quickly enter and exit the highway. Even if the highway has 5 lanes so multiple cars can pass, if there is only a one-lane entrance ramp, there can be a bottleneck getting onto the "fast" highway.
Other operations between nodes, such as parallel query, rely on high bandwidth.
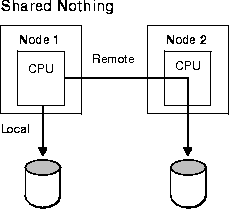
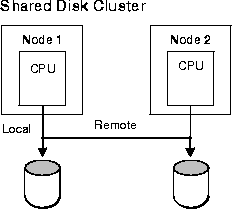
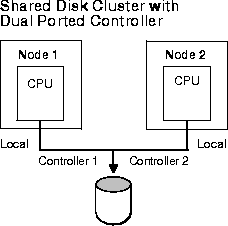
Local I/Os are faster than remote I/Os (those which occur between nodes). If a great deal of remote I/O is needed, the system loses scalability. In this case you can partition data so that the data is local. Figure 2-2 illustrates the difference.
The shared disk architectures shown in Figure 2-2 are explained in the next chapter, Chapter 3, "Parallel Hardware Architecture".
The ultimate scalability of your system also depends upon the scalability of the operating system. This section explains how to analyze this factor.
Software scalability can be an important issue if one node is a shared memory system (that is, a system where multiple CPUs connect to a symmetric multiprocessor single memory). Methods of synchronization in the operating system can determine the scalability of the system. In asymmetrical multiprocessing, for example, only a single CPU can handle I/O interrupts. Consider a system where multiple user processes request resources from the operating system:
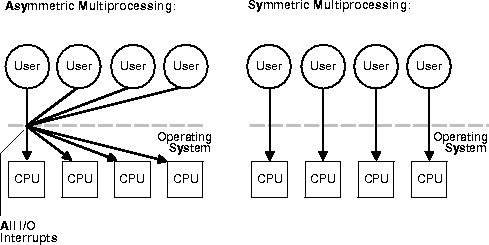
Here, potential scalability of the hardware is lost because the operating system can only process one resource request at a time. Each time a request enters the operating system, a lock is held to exclude the others. In symmetrical multiprocessing, by contrast, there is no such restriction.
An important distinction in parallel server architectures is internal versus external parallelism; this has a strong effect on scalability. The key difference is whether the object-relational database management system (ORDBMS) parallelizes the query, or an external process parallelizes the query.
Disk affinity can improve performance by ensuring that nodes mainly access local, rather than remote, devices. An efficient synchronization mechanism enables better speedup and scaleup.
Application design is key to taking advantage of the scalability of the other elements of the system.
No matter how scalable the hardware, software, and database may be, a table with only one row which every node is updating will synchronize on one datablock. Consider the process of generating a unique sequence number:
UPDATE ORDER_NUM SET NEXT_ORDER_NUM = NEXT_ORDER_NUM + 1; COMMIT;
Every node needing to update this sequence number must wait to access the same row of this table: the situation is inherently unscalable. A better approach is to use sequences to improve scalability:
INSERT INTO ORDERS VALUES (order_sequence.nextval, ... )
In the above example, you can preallocate and cache sequence numbers to improve scalability. However you may not be able to scale some applications due to business rules. In such cases, you must determine the cost of the rule.
This section describes applications that commonly benefit from a parallel server.
Data warehousing applications that infrequently update, insert, or delete data are often appropriate for Oracle Parallel Server (OPS). Query-intensive applications and other applications with low update activity can access the database through different instances with little additional overhead.
If the data blocks are not to be modified, multiple nodes can read the same block into their buffer caches and perform queries on the block without additional I/O or lock operations.
Decision support applications are good candidates for OPS because they only occasionally modify data, as in a database of financial transactions that is mostly accessed by queries during the day and is updated during off-peak hours.
Applications that either update different data blocks or update the same data blocks at different times are also well suited to the parallel server. An example is a time-sharing environment where users each own and use one set of tables.
An instance that needs to update blocks held in its buffer cache must hold one or more instance locks in exclusive mode while modifying those buffers. Tune parallel server and the applications that run on it to reduce this type of contention for instance locks. Do this by planning how each instance and application uses data and partition your tables accordingly.
Online transaction processing applications that modify different sets of data benefit the most from parallel server. One example is a branch banking system where each branch (node) accesses its own accounts and only occasionally accesses accounts from other branches.
Applications that access a database in a mostly random pattern also benefit from parallel server. This is true only if the database is significantly larger than any node's buffer cache. One example is a motor vehicle department's system where individual records are unlikely to be accessed by different nodes at the same time. Another example is an archived tax record or research data system. In cases like these, most access results in I/O even if the instance had exclusive access to the database. Oracle features such as fine grained locking further improve performance of such applications.
Applications that primarily modify different tables in the same database are also suitable for OPS. An example is a system where one node is dedicated to inventory processing, another is dedicated to personnel processing, and a third is dedicated to sales processing. In this case there is only one database to administer, not three.
Applications requiring high availability benefit from the Oracle Parallel Server's failover capability. If the connection through one instance to the database is broken, you can write applications to automatically reconnect through a different instance.
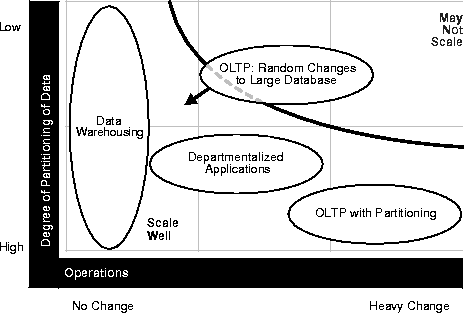
Figure 2-4 illustrates the relative scalability of different application types. Data warehousing applications, depicted by the left-most bubble, typically scale well since updates are less common and the degree of partitioning is higher than other application types. OLTP and departmentalized applications with partitioning and increasing rates of change also scale well.
OLTP applications making random changes to large databases were historically not considered good parallel server candidates. Such applications, however, are becoming more scalable with advanced intra-node communication by way of the interconnect. This is particularly true if, for example, a table is modified on one instance and then another instance reads the table. Such configurations are now much more scalable than in previous releases.
The following guidelines describe situations when parallel processing is not advantageous.
If many users on a large number of nodes modify a small set of data, then synchronization is likely to be very high. However, if they just read data, then no synchronization is required.
For example, it would not be effective to use a table with one row used primarily as a sequence numbering tool. Such a table would be a bottleneck because every process would have to select the row, update it, and release it sequentially.
This section provides general guidelines for partitioning decisions that decrease synchronization and improve performance.
You can partition any of the three elements of processing, depending on function, location, and so on, such that they do not interfere with each other. These elements are:
Partition data, based on groups of users who access it; partition applications into groups that access the same data. Also consider geographic partitioning or partitioning by location.
With vertical partitioning, many tasks can run on a large number of resources without much synchronization. Figure 2-5 illustrates vertical partitioning.
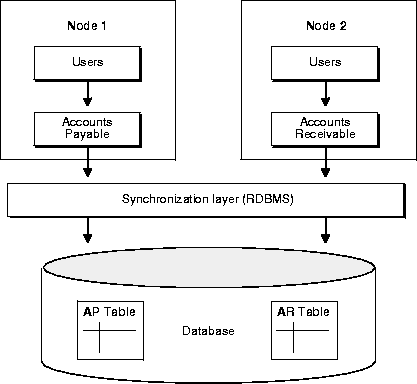
Here, a company's accounts payable and accounts receivable functions have been partitioned by users, application, and data. They have been placed on two separate nodes. Here, most synchronization occurs on the same node; this is very efficient. The cost of synchronization on the local node is cheaper than the cost of synchronization between nodes.
Partition tasks on a subset of resources to reduce synchronization. When you partition, a smaller set of tasks will require access to shared resources.
To illustrate the concept of horizontal partitioning, Figure 2-6 represents the rows of a stock table. If OPS has four instances, each on its own node, then partition them so that each instance accesses only a subset of the data.

In this example, very little synchronization is necessary because the instances access different sets of rows. Similarly, users partitioned by location can often run almost independently. Very little synchronization is needed if users do not access the same data.
Various mistaken notions can lead to unrealistic expectations about parallel processing. Consider the following:
In some applications, a single synchronization (hotshot) may be so expensive as to constitute a problem; in other applications, many synchronizations on less contentious data may be perfectly acceptable.
For example, on some MPP systems if one CPU dies, the entire machine dies. On a cluster, by contrast, if one node dies other nodes survive. The same is also true for MPP systems.