Release 8.1.5
A67775-01
Library |
Product |
Contents |
Index |
| Oracle8i Tuning Release 8.1.5 A67775-01 |
|
![]()
![]()
This chapter offers guidelines for tuning instance recovery. It includes the following topics:
Instance and crash recovery are the automatic application of redo log records to Oracle data blocks after a crash or system failure. If either a single instance database crashes or all instances of an OPS (Oracle Parallel Server) configuration crash, Oracle performs instance recovery at the next startup. If one or more instances of an OPS configuration crash, a surviving instance performs recovery.
Instance and crash recovery occur in two phases. In phase one, Oracle applies all committed and uncommitted changes in the redo log files to the affected datablocks. In phase two, Oracle applies information in the rollback segments to undo changes made by uncommitted transactions to the data blocks.
During normal operations, Oracle's DBWn processes periodically write dirty buffers, or buffers that have in-memory changes, to disk. Periodically, Oracle records the highest SCN of all changes to blocks such that all data blocks with changes below that SCN have been written to disk by DBWn. This SCN is the "checkpoint".
Records that Oracle appends to the redo log file after the change record that the checkpoint refers to are changes that Oracle has not yet written to disk. If a failure occurs, only redo log records containing changes at SCNs higher than the checkpoint need to be replayed during recovery.
The duration of recovery processing is directly influenced by the number of data blocks that have changes at SCNs higher than the SCN of the checkpoint. For example, Oracle will recover a redo log with 100 entries affecting one data block more quickly than it recovers a redo log with 10 entries for 10 different data blocks. This is because for each log record processed during recovery, the corresponding data block must be read from disk by Oracle so that the change represented by the redo log entry can be applied to that block.
The principal means of balancing the duration of instance recovery and daily performance is by influencing how aggressively Oracle advances the checkpoint. If you force Oracle to keep the checkpoint only a few blocks behind the most recent redo log record, you minimize the number of blocks Oracle processes during recovery.
The trade-off for having minimal recovery time, however, is increased performance overhead for normal database operations. If daily operational efficiency is more important than minimizing recovery time, decreasing the frequency of writes to the datafiles increases instance recovery time.
There are several methods for tuning instance and crash recovery to keep the duration of recovery within user-specified bounds. These methods are:
The Oracle8i Enterprise Edition also offers Fast-start fault recovery functionality to control instance recovery.
During recovery, Oracle performs two main tasks:
You can use three initialization parameters to influence how aggressively Oracle advances the checkpoint as shown in Table 25-1:
Set the initialization parameter LOG_CHECKPOINT_TIMEOUT to a value n (where n is an integer) to require that the latest checkpoint position follow the most recent redo block by no more than n seconds. In other words, at most, n seconds' worth of logging activity can occur between the most recent checkpoint position and the end of the redo log. This forces the checkpoint position to keep pace with the most recent redo block
You can also interpret LOG_CHECKPOINT_TIMEOUT as specifying an upper bound on the time a buffer can be dirty in the cache before DBWn must write it to disk. For example, if you set LOG_CHECKPOINT_TIMEOUT to 60, then no buffers remain dirty in the cache for more than 60 seconds. The default value for LOG_CHECKPOINT_TIMEOUT is 1800.
Set the initialization parameter LOG_CHECKPOINT_INTERVAL to a value n (where n is an integer) to require that the checkpoint position never follow the most recent redo block by more than n blocks. In other words, at most n redo blocks can exist between the checkpoint position and the last block written to the redo log. In effect, you are limiting the amount of redo blocks that can exist between the checkpoint and the end of the log.
Oracle limits the maximum value of LOG_CHECKPOINT_INTERVAL to 90% of the smallest log to ensure that the checkpoint advances far enough to eliminate "log wrap". Log wrap occurs when Oracle fills the last available redo log file and cannot write to any other log file because the checkpoint has not advanced far enough. By ensuring that the checkpoint never gets too far from the end of the log, Oracle never has to wait for the checkpoint to advance before it can switch logs.
LOG_CHECKPOINT_INTERVAL is specified in redo blocks. Redo blocks are the same size as operating system blocks. Use the LOG_FILE_SIZE_REDO_BLKS column in V$INSTANCE_RECOVERY to see the number of redo blocks corresponding to 90% of the size of the smallest log file.
You can only use the initialization parameter FAST_START_IO_TARGET if you have the Oracle8i Enterprise Edition. You can set this parameter to n, where n is an integer limiting to n the number of buffers that Oracle processes during crash or instance recovery. Because the number of I/Os to be processed during recovery correlates closely to the duration of recovery, the FAST_START_IO_TARGET parameter gives you the most precise control over the duration of recovery.
FAST_START_IO_TARGET advances the checkpoint because DBWn uses the value of FAST_START_IO_TARGET to determine how much writing to do. Assuming that users are making many updates to the database, a low value for this parameter forces DBWn to write changed buffers to disk. The CKPT process reflects this progress as the checkpoint advances. Of course, if user activity is low or non-existent, DBWn does not have any buffers to write, so the checkpoint does not advance.
The smaller the value of FAST_START_IO_TARGET, the better the recovery performance, since fewer blocks require recovery. If you use smaller values for this parameter, however, you impose higher overhead during normal processing, since DBWn must write more buffers to disk more frequently.
|
See Also:
For more information, see "Estimating Recovery Time" and "Calculating Performance Overhead". For more information about initialization parameters, see the Oracle8i Reference. |
The size of a redo log file directly influences checkpoint performance. The smaller the size of the smallest log, the more aggressively Oracle writes dirty buffers to disk to ensure the position of the checkpoint has advanced to the current log before that log completely fills. Oracle enforces this behavior by ensuring the number of redo blocks between the checkpoint and the most recent redo record is less than 90% of the size of the smallest log.
If your redo logs are small compared to the number of changes made against the database, Oracle must switch logs frequently. If the value of LOG_CHECKPOINT_INTERVAL is less than 90% of the size of the smallest log, this parameter will have the most influence over checkpointing behavior.
Although you specify the number and sizes of online redo log files at database creation, you can alter the characteristics of your redo log files after startup. Use the ADD LOGFILE clause of the ALTER DATABASE command to add a redo log file and specify its size, or the DROP LOGFILE clause to drop a redo log.
The size of the redo log appears in the LOG_FILE_SIZE_REDO_BLKS column of the V$INSTANCE_RECOVERY dynamic performance. This value shows how the size of the smallest online redo log is affecting checkpointing. By increasing or decreasing the size of your online redo logs, you indirectly influence the frequency of checkpoint writes.
|
See Also:
For information on using the V$INSTANCE_RECOVERY view to tune instance recovery, see "Estimating Recovery Time". |
Besides setting initialization parameters and sizing your redo log files, you can also influence checkpoints with SQL statements. ALTER SYSTEM CHECKPOINT directs Oracle to record a checkpoint for the node, and ALTER SYSTEM CHECKPOINT GLOBAL directs Oracle to record a checkpoint for every node in a cluster.
SQL-induced checkpoints are "heavyweight". This means Oracle records the checkpoint in a control file shared by all the redo threads. Oracle also updates the datafile headers. SQL-induced checkpoints move the checkpoint position to the point that corresponded to the end of the log when the command was initiated. These checkpoints can adversely affect performance because the additional writes to the datafiles increase system overhead.
Use the V$INSTANCE_RECOVERY view to see your current recovery parameter settings. You can also use statistics from this view to calculate which parameter has the greatest influence on checkpointing. V$INSTANCE_RECOVERY contains columns as shown in Table 25-2:
The value appearing in the TARGET_REDO_BLKS column equals a value appearing in another column in the view. This other column corresponds to the parameter or log file that is determining the maximum number of redo blocks that Oracle processes during recovery. The setting for the parameter in this column is imposing the heaviest requirement on redo block processing.
As an example, assume your initialization parameter settings are as follows:
FAST_START_IO_TARGET = 1000 LOG_CHECKPOINT_TIMEOUT = 1800 # default LOG_CHECKPOINT_INTERVAL = 0 # default: disabled interval checkpointing
You execute the query:
SELECT * FROM V$INSTANCE_RECOVERY;
Oracle responds with:
1 row selected.
As you can see by the values in the last three columns, the FAST_START_IO_TARGET parameter places heavier recovery demands on Oracle than the other two parameters: it requires that Oracle process no more than 4,215 redo blocks during recovery. The LOG_FILE_SIZE_REDO_BLKS column indicates that Oracle can process up to 55,296 blocks during recovery, so the log file size is not the heaviest influence on checkpointing.
The TARGET_REDO_BLKS column shows the smallest value of the last five columns. This shows the parameter or condition that exerts the heaviest requirement for Oracle checkpointing. In this example, the FAST_START_IO_TARGET parameter is the strongest influence with a value of 4,215.
Assume you make several updates to the database and query V$INSTANCE_RECOVERY three hours later. Oracle responds with the following:
1 row selected.
FAST_START_IO_TARGET is still exerting the strongest influence over checkpointing behavior, although the number of redo blocks corresponding to this target has changed dramatically. This change is not due to a change in FAST_START_IO_TARGET or the corresponding RECOVERY_ESTIMATED_IOS. Instead, this indicates that operations requiring I/O in the event of recovery are more frequent in the redo log, so fewer redo blocks now correspond to the same FAST_START_IO_TARGET.
Assume you decide that FAST_START_IO_TARGET is placing an excessive limit on the maximum number of redo blocks that Oracle processes during recovery. You adjust FAST_START_IO_TARGET to 8000, set LOG_CHECKPOINT_TIMEOUT to 60, and perform several updates. You reissue the query to V$INSTANCE_RECOVERY and Oracle responds with:
1 row selected.
Because the TARGET_REDO_BLKS column value of 6707 corresponds to the value in the LOG_CHKPT_TIMEOUT_REDO_BLKS column, LOG_CHECKPOINT_TIMEOUT is now exerting the most influence over checkpointing behavior.
Use statistics from the V$INSTANCE_RECOVERY view to estimate recovery time using the following formula:

For example, if RECOVERY_ESTIMATED_IOS is 2,500, and the maximum number of writes your system performs is 500 per second, then recovery time is 5 seconds. Note the following restrictions:
To adjust recovery time, change the initialization parameter that has the most influence over checkpointing. Use the V$INSTANCE_RECOVERY view as described in "Monitoring Instance Recovery" to determine which parameter to adjust. Then either adjust the parameter to decrease or increase recovery time as required.
As an example, assume as in "Determining the Strongest Checkpoint Influence: Scenario" that your initialization parameter settings are as follows:
FAST_START_IO_TARGET = 1000 LOG_CHECKPOINT_TIMEOUT = 1800 # default LOG_CHECKPOINT_INTERVAL = 0 # default: disabled interval checkpointing
You execute the query:
SELECT * FROM V$INSTANCE_RECOVERY;
Oracle responds with:
1 row selected.
You calculate recovery time using the formula, where RECOVERY_ESTIMATED_JOBS is 1025 and the maximum I/Os per second the system can perform is 500:
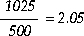
You decide you can afford slightly more than 2.05 seconds of recovery time: constant access to the data is not critical. You increase the value for the parameter FAST_START_IO_TARGET to 2000 and perform several updates. You then reissue the query and Oracle displays:
1 row selected.
Recalculate recovery time using the same formula:
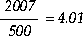
You have increased your recovery time by 1.96 seconds. If you can afford more time, repeat the procedure until you arrive at an acceptable recovery time.
To calculate performance overhead, use the V$SYSSTAT view. For example, assume you execute the query:
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME IN ( 'PHYSICAL READS', 'PHYSICAL WRITES',);
Oracle responds with:
NAME VALUE physical reads 2376 physical writes 14932 physical writes non checkpoint 11165 3 rows selected.
The first row shows the number of data blocks retrieved from disk. The second row shows the number of data blocks written to disk. The last row shows the value of the number of writes to disk that would occur if you turned off checkpointing.
Use this data to calculate the overhead imposed by setting the FAST_START_IO_TARGET initialization parameter. To effectively measure the percentage of extra writes, mark the values for these statistics at different times, T_1 and T_2. Use the following formula where the variables stand for the following:
Calculate the percentage of extra I/Os generated by fast-start checkpointing using this formula: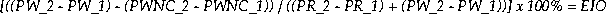
It can take some time for database statistics to stabilize after instance startup or dynamic initialization parameter modification. After such events, wait until all blocks age out of the buffer cache at least once before taking measurements.
If the percentage of extra I/Os is too high, increase the value for FAST_START_IO_TARGET. Adjust this parameter until you get an acceptable value for the RECOVERY_ESTIMATED_IOS in V$INSTANCE_RECOVERY as described in "Determining the Strongest Checkpoint Influence: Scenario".
The number of extra writes caused by setting FAST_START_IO_TARGET to a non-zero value is application-dependent. An application that repeatedly modifies the same buffers incurs a higher write penalty because of Fast-start checkpointing than an application that does not. The extra write penalty is not dependent on cache size.
As an example, assume your initialization parameter settings are:
FAST_START_IO_TARGET = 2000 LOG_CHECKPOINT_TIMEOUT = 1800 # default LOG_CHECKPOINT_INTERVAL = 0 # default: disabled interval checkpointing
After the statistics stabilize, you issue this query on V$SYSSTAT:
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME IN ('PHYSICAL READS', 'PHYSICAL WRITES', 'PHYSICAL WRITES NON CHECKPOINT');
Oracle responds with:
Name Value physical reads 2376 physical writes 14932 physical writes non checkpoint 11165 3 rows selected.
After making updates for a few hours, you re-issue the query and Oracle responds with:
Name Value physical reads 3011 physical writes 17467 physical writes non checkpoint 13231 3 rows selected.
Substitute the values from your select statements in the formula as described to determine how much performance overhead you are incurring:
[((17467 - 14932) - (13231 - 11165)) / ((3011 - 2376) + (17467 - 14932))] x 100% = 14.8%
As the result indicates, enabling fast-start checkpointing generates about 15% more I/O than would be required had you not enabled fast-start checkpointing. After calculating the extra I/O, you decide you can afford more system overhead if you decrease recovery time.
To decrease recovery time, reduce the value for the parameter FAST_START_IO_TARGET to 1000. After items in the buffer cache age out, calculate V$SYSSTAT statistics across a second interval to determine the new performance overhead. Query V$SYSSTAT:
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME IN ('PHYSICAL READS', 'PHYSICAL WRITES', 'PHYSICAL WRITES NON CHECKPOINT');
Oracle responds with:
Name Value physical reads 4652 physical writes 28864 physical writes non checkpoint 21784 3 rows selected.
After making updates, re-issue the query and Oracle responds with:
Name Value physical reads 6000 physical writes 35394 physical writes non checkpoint 26438 3 rows selected.
Calculate how much performance overhead you are incurring using the values from your two SELECT statements:
[(35394 - 28864) - (26438 - 21784)) / ((6000 - 4652) + (35394 - 28864))] x 100% = 23.8%
After changing the parameter, the percentage of I/Os performed by Oracle is now about 24% more than it would be if you disabled Fast-start checkpointing.
Besides using checkpoints to tune instance recovery, you can also use a variety of parameters to control Oracle's behavior during the rolling forward and rolling back phases of instance recovery. In some cases, you can parallelize operations and thereby increase recovery efficiency.
This section contains the following topics:
Use parallel block recovery to tune the roll forward phase of recovery. Parallel block recovery uses a "division of labor" approach to allocate different processes to different data blocks during the roll forward phase of recovery. For example, if the redo log contains a substantial number of entries, process 1 takes responsibility for one part of the log file, process 2 takes responsibility for another part, process 3 takes responsibility for a third part, and so on. Crash, instance, and media recovery of many datafiles on different disk drives are good candidates for parallel block recovery.
Use the RECOVERY_PARALLELISM initialization parameter to specify the number of concurrent recovery processes for instance or media recovery operations. Because crash recovery occurs at instance startup, this parameter is useful for specifying the number of processes to use for crash recovery. The value of this parameter is also the default number of processes used for media recovery if you do not specify the PARALLEL clause of the RECOVER command. The value of this parameter must be greater than 1 and cannot exceed the value of the PARALLEL_MAX_SERVERS parameter. Parallel block recovery requires a minimum of eight recovery processes for it to be more effective than serial recovery.
Recovery is usually I/O bound on reads to data blocks. Consequently, parallelism at the block level may only help recovery performance if it increases total I/Os. In other words, parallelism at the block level by-passes operating system restrictions on asynchronous I/Os. Performance on systems with efficient asynchronous I/O typically does not improve significantly with parallel block recovery.
During the second phase of instance recovery, Oracle rolls back uncommitted transactions. Oracle uses two features, Fast-start on-demand rollback and Fast-start parallel rollback, to increase the efficiency of this recovery phase.
This section contains the following topics:
Using the Fast-start on-demand rollback feature, Oracle automatically allows new transactions to begin immediately after the roll forward phase of recovery completes. Should a user attempt to access a row that is locked by a dead transaction, Oracle rolls back only those changes necessary to complete the transaction, in other words, it rolls them back "on demand." Consequently, new transactions do not have to wait until all parts of a long transaction are rolled back.
In Fast-start parallel rollback, the background process SMON acts as a coordinator and rolls back a set of transactions in parallel using multiple server processes. Essentially, Fast-start parallel rollback is to rolling back what parallel block recovery is to rolling forward.
Fast-start parallel rollback is mainly useful when a system has transactions that run a long time before committing, especially parallel INSERT, UPDATE, and DELETE operations. When SMON discovers that the amount of recovery work is above a certain threshold, it automatically begins parallel rollback by dispersing the work among several parallel processes: process 1 rolls back one transaction, process 2 rolls back a second transaction, and so on. The threshold is the point at which parallel recovery becomes cost-effective, in other words, when parallel recovery takes less time than serial recovery.
One special form of Fast-start parallel rollback is intra-transaction recovery. In intra-transaction recovery, a single transaction is divided among several processes. For example, assume 8 transactions require recovery with one parallel process assigned to each transaction. The transactions are all similar in size except for transaction 5, which is quite large. This means it takes longer for one process to roll this transaction back than for the other processes to roll back their transactions.
In this situation, Oracle automatically begins intra-transaction recovery by dispersing transaction 5 among the processes: process 1 takes one part, process 2 takes another part, and so on.
You control the number of processes involved in transaction recovery by setting the parameter FAST_START_PARALLEL_ROLLBACK to one of three values:
In OPS, you can perform Fast-start parallel rollback on each instance. Within each instance, you can perform parallel rollback on transactions that are:
Once a rollback segment is online for a given instance, only this instance can perform parallel rollback on transactions on that segment.
Monitor the progress of Fast-start parallel rollback by examining the V$FAST_START_SERVERS and V$FAST_START_TRANSACTIONS tables. V$FAST_START_SERVERS provides information about all recovery processes performing fast-start parallel rollback. V$FAST_START_TRANSACTIONS contains data about the progress of the transactions.
|
See Also:
For more information on Fast-start parallel rollback in an OPS environment, see Oracle8i Parallel Server Concepts and Administration. For more information about initialization parameters, see the Oracle8i Reference. |
This section covers the following topics:
To use transparent application failover, you must have the Oracle8i Enterprise Edition which is described in the text, Getting to Know Oracle8i.
Note:
Transparent application failover (TAF) is the ability of applications to automatically reconnect to the database if the connection fails. If the client is not involved in a database transaction, then users may not notice the failure of the server. Because this reconnect happens automatically from within the ../../server.815/a67846/toc.htm library, the client application code may not need changes to use TAF.
During normal client-server database operations, the client maintains a connection to the database so the client and server can communicate. If the server fails, the connection also fails. The next time the client tries to use the connection to execute a new SQL statement, for example, the operating system displays an error to the client. Oracle most commonly then issues the error "ORA-3113: end-of-file on communication channel". At this point, the user must log in to the database again.
With TAF, however, Oracle automatically obtains a new connection to the database. This allows the user to continue to work using the new connection as if the original connection had never failed.
There several elements associated with active database connections. These can include:
TAF automatically restores some of these elements. Other elements, however, may need to be embedded in the application code to enable TAF to recover the connection.
TAF automatically reestablishes the database connection. By default, TAF uses the same connect string to attempt to obtain a new database connection. Alternately, you can configure failover to use a different connect string; you can even pre-establish an alternate failover connection. For more information about these configurations, see "Configuring Application Failover".
TAF automatically logs a user in with the same user ID as was used prior to failure. If multiple users were using the connection, then TAF automatically logs them in as they attempt to process database commands. Unfortunately, TAF cannot automatically restore other session properties. If the application issued ALTER SESSION commands, then the application must re-issue them after TAF processing is complete. This can be done in failover callback processing, which is described in more detail in the Oracle Call Interface Programmer's Guide.
The client usually discovers a connection failure after a command is issued to the server that results in an error. The client cannot determine whether the command was completely executed prior to the server's failure. If the command was completely executed and it changed the state of the database, the command is not resent. If TAF reconnects in response to a command that may have changed the database, TAF issues an "ORA-25408: can not safely replay call" message to the application.
TAF automatically resends SELECT and fetch commands to the database after failover because these types of commands do not change the database's state.
TAF allows applications that began fetching rows from a cursor before failover to continue fetching rows after failover. This is called "select" failover. It is accomplished by re-executing a SELECT statement using the same snapshot and retrieving the same number of rows.
TAF also provides a safeguard to guarantee that the results of the select are consistent. If this safeguard fails, the application may receive the error message "ORA-25401 can not continue fetches".
Any active transactions are rolled back at the time of failure because TAF cannot preserve active transactions after failover. The application instead receives the error message "ORA-25402 transaction must roll back" until a ROLLBACK is submitted.
Server-side program variables, such as PL/SQL package states, are lost during failures; TAF cannot recover them. They can be initialized by making a call from the failover callback, which is described in more detail in the Oracle Call Interface Programmer's Guide.
For TAF to effectively mask a database failure, there must be a location to which the client can reconnect. This section discusses the following database configurations, and how they work with TAF.
TAF was initially conceived for Oracle Parallel Server environments. All TAF functionality works with OPS, and no special setup is required. For more information about OPS, see the Oracle8i Parallel Server Setup and Configuration Guide.
You can use TAF with Oracle Fail Safe. However, since the backup instance is not available to take connections, when the primary database fails, some clients may attempt to reconnect during the time when the database server is unavailable. The failover callback may be used to get around this. For more information about failover callback, see the Oracle Call Interface Programmer's Guide.
TAF works with replicated systems provided that all database objects are the same on both sides of the replication. This includes the same passwords, and so on. If the data in the tables are slightly out of sync with each other, then there is a higher probability of encountering an "ORA-25401: can not continue fetches". For more information about replication, see Oracle8i Replication.
TAF works with standby databases in a manner similar to TAF with Fail Safe. Since there may be a timeframe when a database is not available for the client to log into, the failover callback should be provided. Also, since changes made later than the most recent archive logs will not be present, there may be some data skew and hence a higher chance of encountering an "ORA-25401: can not continue fetches".
You can also use TAF in single instance Oracle database environments. After a failure in single instance environments, there can be a time period when the database is unavailable and TAF cannot re-establish a connection. For this reason, a failover callback can be used to periodically re-attempt failover. TAF successfully re-establishes the connection after the database is available again.
This section explains the following topics:
You can configure the connect string for the application at the names server, or put it in the TNSNAMES.ORA file. Alternatively, the connect string can be hard-coded in the application.
For each application, the names server provides information about the listener, the instance group, and the failover mode. The connect string failover_mode field specifies the type and method of failover. For more information on syntax, please refer to the Net8 Administrator's Guide.
The client's failover functionality is determined by the TYPE keyword in the connect string. The choices for the TYPE keyword are:
Improving the speed of application failover often requires putting more work on the backup instance. The DBA can use the METHOD keyword in the connect string to configure the BASIC or PRECONNECT performance options.
In many cases it is not convenient to use the same connect string for both the initial and backup connections. In these instances, you can use the BACKUP keyword in the connect string that specifies a different TNS alias or explicit connect string for backup connections.
The view V$SESSION has the following fields related to failover:
|
FAILED_OVER |
TRUE if using the backup, otherwise FALSE. |
|
TYPE |
One of SELECT, SESSION, or NONE. |
|
METHOD |
Either BASIC or PRECONNECT. |
The TRANSACTIONAL option to the SHUTDOWN command enables you to do a planned shutdown of one instance while minimally interrupting clients. This option waits for ongoing transactions to complete. The TRANSACTIONAL option is useful for installing patch releases. Also use this option when you must bring down the instance without interrupting service.
While waiting, clients cannot start new transactions on the instance. Clients are disconnected if they attempt to start a transaction and this triggers failover if failover is enabled. When the last transaction completes, the primary instance performs a SHUTDOWN IMMEDIATE.
The ALTER SYSTEM DISCONNECT SESSION POST_TRANSACTION statement disconnects a session on the first call after its current transaction has been finished. The application fails over automatically.
This statement works well with TAF as a way for you to control load. If one instance is overloaded, you can manually disconnect a group of sessions using this option. Since the option guarantees there is no transaction at the time the session is disconnected, the user should never notice the change, except for a slight delay in executing the next command following the disconnect. For complete syntax of this, see the Oracle8i SQL Reference.
The elapsed time of failover includes instance recovery as well as time needed to reconnect to the database. For best failover performance, tune instance recovery by having frequent checkpoints.
Performance can also be improved by using multiple listeners or by using the Multi-threaded Server (MTS). MTS connections tend to be much faster than connections by way of dedicated servers.
This section describes multiple user handles and failover callbacks.
Failover is supported for multiple user handles. In ../../server.815/a67846/toc.htm, server context handles and user handles are decoupled. You can have multiple user handles related to the server context handle, and multiple users can thus share the same connection to the database.
If the connection is destroyed, then every user associated with that connection is failed over. But if a single user session is destroyed, then failover does not occur because the connection is still there. Failover does not reauthenticate migrateable user handles.
Frequently failure of one instance and failover to another takes time. Because of this delay, you may want to inform users that failover is in progress. Additionally, the session on the initial instance may have received some ALTER SESSION commands. These will not be automatically replayed on the second instance. You may want to ensure that these commands are replayed on the second instance. To address such problems, you can register a callback function.
Failover calls the callback function several times when re-establishing user sessions. The first call occurs when instance's connection failure is first detected, so the application can inform users of upcoming delays. If failover is successful, the second call occurs when the connection is re-established and usable.
At this time, the client may wish to replay ALTER SESSION statements and inform users that failover has occurred. If failover is unsuccessful, then the callback can be called to inform the application that failover will not occur. If this happens, you can specify that the failover should be re-attempted. Additionally, the callback will be called for each user handle when it attempts to use the connection after failover.
When a connection is lost, you will see the following effects: