Release 8.1.5
A67772-01
Library |
Product |
Contents |
Index |
| Oracle8i Administrator's Guide Release 8.1.5 A67772-01 |
|
![]()
![]()
This chapter describes how to archive redo data. It includes the following topics:
See Also: If you are using Oracle with the Parallel Server, see Oracle8i Parallel Server Concepts and Administration for additional information about archiving in the OPS environment.
Oracle allows you to save filled groups of online redo log files, known as archived redo logs, to one or more offline destinations. Archiving is the process of turning online redo logs into archived redo logs. The background process ARCn automates archiving operations. You can use archived logs to:
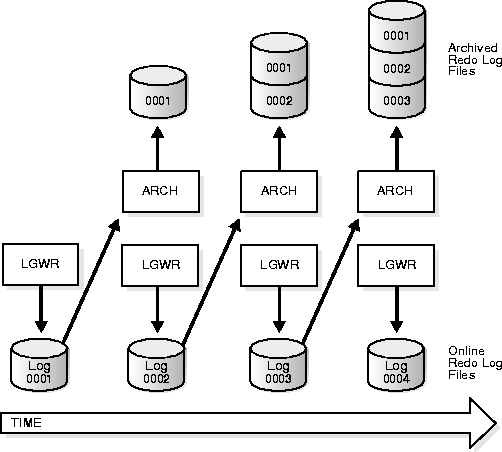
An archived redo log file is a copy of one of the identical filled members of an online redo log group: it includes the redo entries present in the identical members of a group and also preserves the group's unique log sequence number. For example, if you are multiplexing your online redo logs, and if Group 1 contains member files A_LOG1 and B_LOG1, then ARCn will archive one of these identical members. Should A_LOG1 become corrupted, then ARCn can still archive the identical B_LOG1.
If you enable archiving, LGWR is not allowed to re-use and hence overwrite an online redo log group until it has been archived. Therefore, the archived redo log contains a copy of every group created since you enabled archiving. Figure 7-1 shows how ARCn archives redo logs:
This section describes the issues you must consider when choosing to run your database in NOARCHIVELOG or ARCHIVELOG mode, and includes the following topics:
When you run your database in NOARCHIVELOG mode, you disable the archiving of the online redo log. The database's control file indicates that filled groups are not required to be archived. Therefore, when a filled group becomes inactive after a log switch, the group is available for reuse by LGWR.
The choice of whether to enable the archiving of filled groups of online redo log files depends on the availability and reliability requirements of the application running on the database. If you cannot afford to lose any data in your database in the event of a disk failure, use ARCHIVELOG mode. Note that the archiving of filled online redo log files can require you to perform extra administrative operations.
NOARCHIVELOG mode protects a database only from instance failure, but not from media failure. Only the most recent changes made to the database, which are stored in the groups of the online redo log, are available for instance recovery. In other words, if you are using NOARCHIVELOG mode, you can only restore (not recover) the database to the point of the most recent full database backup. You cannot recover subsequent transactions.
Also, in NOARCHIVELOG mode you cannot perform online tablespace backups. Furthermore, you cannot use online tablespace backups previously taken while the database operated in ARCHIVELOG mode. You can only use whole database backups taken while the database is closed to restore a database operating in NOARCHIVELOG mode. Therefore, if you decide to operate a database in NOARCHIVELOG mode, take whole database backups at regular, frequent intervals.
When you run a database in ARCHIVELOG mode, you enable the archiving of the online redo log. The database control file indicates that a group of filled online redo log files cannot be used by LGWR until the group is archived. A filled group is immediately available for archiving after a redo log switch occurs.
The archiving of filled groups has these advantages:
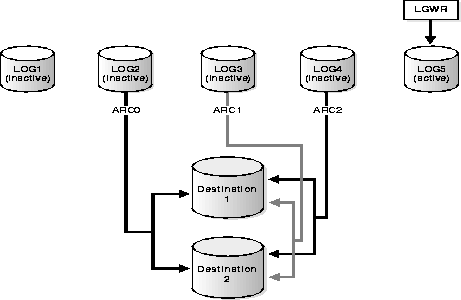
Decide how you plan to archive filled groups of the online redo log. You can configure an instance to archive filled online redo log files automatically, or you can archive manually. For convenience and efficiency, automatic archiving is usually best. Figure 7-2 illustrate how the process archiving the filled groups (ARCn in this illustration) generates the database's online redo log.
If all databases in a distributed database operate in ARCHIVELOG mode, you can perform coordinated distributed database recovery. If any database in a distributed database uses NOARCHIVELOG mode, however, recovery of a global distributed database (to make all databases consistent) is limited by the last full backup of any database operating in NOARCHIVELOG mode.
See Also: You can also configure Oracle to verify redo log blocks when they are archived. For more information, see "Verifying Blocks in Redo Log Files".
This section describes aspects of archiving, and includes the following topics:
See Also: If a database is automatically created during Oracle installation, the initial archiving mode of the database is operating system specific. See your operating system-specific Oracle documentation.
You set a database's initial archiving mode as part of database creation in the CREATE DATABASE statement. Usually, you can use the default of NOARCHIVELOG mode at database creation because there is no need to archive the redo information generated then. After creating the database, decide whether to change from the initial archiving mode.
To switch a database's archiving mode between NOARCHIVELOG and ARCHIVELOG mode, use the SQL statement ALTER DATABASE with the ARCHIVELOG or NOARCHIVELOG option. The following statement switches the database's archiving mode from NOARCHIVELOG to ARCHIVELOG:
ALTER DATABASE ARCHIVELOG;
Before switching the database's archiving mode, perform the following operations:
An open database must be closed and dismounted and any associated instances shut down before you can switch the database's archiving mode. You cannot disable archiving if any datafiles need media recovery.
Before making any major change to a database, always back up the database to protect against any problems.
To enable or disable archiving, the database must be mounted but not open.
After using the ALTER DATABASE command to switch a database's archiving mode, open the database for normal operation. If you switched to ARCHIVELOG mode, you should also set the archiving options--decide whether to enable Oracle to archive groups of online redo log files automatically as they fill.
If you want to archive filled groups, you may have to execute some additional steps, depending on your operating system; see your O/S-specific Oracle documentation for details for your system.
See Also: See Oracle8i Parallel Server Concepts and Administration for more information about switching the archiving mode when using the Oracle Parallel Server.
If your operating system permits, you can enable automatic archiving of the online redo log. Under this option, no action is required to copy a group after it fills; Oracle automatically archives it. For this convenience alone, automatic archiving is the method of choice for archiving.
You can enable automatic archiving before or after instance startup. To enable automatic archiving after instance startup, you must be connected to Oracle with administrator privileges.
See Also: Always specify an archived redo log destination and filename format when enabling automatic archiving; see "Specifying Archive Destinations". If automatic archiving is enabled, you can still perform manual archiving; see "Performing Manual Archiving".
To enable automatic archiving of filled groups each time an instance is started, include the initialization parameter LOG_ARCHIVE_START parameter in the database's parameter file and set it to TRUE:
LOG_ARCHIVE_START=TRUE
The new value takes effect the next time you start the database.
To enable automatic archiving of filled online redo log groups without shutting down the current instance, use the SQL statement ALTER SYSTEM with the ARCHIVE LOG START parameter; you can optionally include the archiving destination.
ALTER SYSTEM ARCHIVE LOG START;
If you use the ALTER SYSTEM method, you do not need to shut down the instance to enable automatic archiving. If an instance is shut down and restarted after automatic archiving is enabled, however, the instance is reinitialized using the settings of the parameter file, which may or may not enable automatic archiving.
You can disable automatic archiving of the online redo log groups at any time. Once you disable automatic archiving, however, you must manually archive groups of online redo log files in a timely fashion. If you run a database in ARCHIVELOG mode and disable automatic archiving, and if all groups of online redo log files are filled but not archived, then LGWR cannot reuse any inactive groups of online redo log groups to continue writing redo log entries. Therefore, database operation is temporarily suspended until you perform the necessary archiving.
You can disable automatic archiving at or after instance startup. To disable automatic archiving after instance startup, you must be connected with administrator privilege and have the ALTER SYSTEM privilege.
To disable the automatic archiving of filled online redo log groups each time a database instance is started, set the LOG_ARCHIVE_START parameter of a database's parameter file to FALSE:
LOG_ARCHIVE_START=FALSE
The new value takes effect the next time the database is started.
To disable the automatic archiving of filled online redo log groups without shutting down the current instance, use the SQL statement ALTER SYSTEM with the ARCHIVE LOG STOP parameter. The following statement stops archiving:
ALTER SYSTEM ARCHIVE LOG STOP;
If ARCn is archiving a redo log group when you attempt to disable automatic archiving, ARCn finishes archiving the current group, but does not begin archiving the next filled online redo log group.
The instance does not have to be shut down to disable automatic archiving. If an instance is shut down and restarted after automatic archiving is disabled, however, the instance is reinitialized using the settings of the parameter file, which may or may not enable automatic archiving.
If you operate your database in ARCHIVELOG mode, then you must archive inactive groups of filled online redo log files. You can manually archive groups of the online redo log whether or not automatic archiving is enabled:
To archive a filled online redo log group manually, connect with administrator privileges. Use the SQL statement ALTER SYSTEM with the ARCHIVE LOG clause to manually archive filled online redo log files. The following statement archives all unarchived log files:
ALTER SYSTEM ARCHIVE LOG ALL;
See Also: With both manual or automatic archiving, you need to specify a thread only when you are using the Oracle Parallel Server. See Oracle8i Parallel Server Concepts and Administration for more information.
When archiving redo logs, determine the destination to which you will archive. You should familiarize yourself with the various destination states as well as the practice of using fixed views to access archive information.
You must decide whether to make a single destination for the logs or multiplex them, i.e., archive the logs to more than one location.
Specify the number of locations for your primary database archived logs by setting the following initialization parameters:
The first method is to use the LOG_ARCHIVE_DEST_n parameter (where n is an integer from 1 to 5) to specify from one to five different destinations for archival. Each numerically-suffixed parameter uniquely identifies an individual destination, For example, LOG_ARCHIVE_DEST_1, LOG_ARCHIVE_DEST_2, and so on.
Specify the location for LOG_ARCHIVE_DEST_n using these keywords:
| Keyword | Indicates | Example |
|---|---|---|
|
LOCATION |
A local filesystem location. |
LOG_ARCHIVE_DEST_1= 'LOCATION=/arc' |
|
SERVICE |
Remote archival via Net8 service name. |
LOG_ARCHIVE_DEST_2 = 'SERVICE=standby1' |
If you use the LOCATION keyword, specify a valid pathname for your operating system. If you specify SERVICE, Oracle translates the net service name through the tnsnames.ora file to a connect descriptor. The descriptor contains the information necessary for connecting to the remote database. Note that the service name must have an associated database SID, so that Oracle correctly updates the log history of the control file for the standby database.
The second method, which allows you to specify a maximum of two locations, is to use the LOG_ARCHIVE_DEST parameter to specify a primary archive destination and the LOG_ARCHIVE_DUPLEX_DEST to determine an optional secondary location. Whenever Oracle archives a redo log, it archives it to every destination specified by either set of parameters.
SHUTDOWN IMMEDIATE;
LOG_ARCHIVE_DEST_1 = 'LOCATION = /disk1/archive' LOG_ARCHIVE_DEST_2 = 'LOCATION = /disk2/archive' LOG_ARCHIVE_DEST_3 = 'LOCATION = /disk3/archive'
If you are archiving to a standby database, use the SERVICE keyword to specify a valid net service name from the tnsnames.ora file. For example, enter:
LOG_ARCHIVE_DEST_4 = 'SERVICE = standby1'
%s to include the log sequence number as part of the filename and %t to include the thread number. Use capital letters (%S and %T) to pad the filename to the left with zeroes. For example, enter:
LOG_ARCHIVE_FORMAT = arch%s.arc
For example, the above settings will generate archived logs as follows for log sequence numbers 100, 101, and 102:
/disk1/archive/arch100.arc, /disk1/archive/arch101.arc, /disk1/archive/arch102.arc /disk2/archive/arch100.arc, /disk2/archive/arch101.arc, /disk2/archive/arch102.arc /disk3/archive/arch100.arc, /disk3/archive/arch101.arc, /disk3/archive/arch102.arc
SHUTDOWN IMMEDIATE;
LOG_ARCHIVE_DEST = '/disk1/archive' LOG_ARCHIVE_DUPLEX_DEST = '/disk2/archive'
%s to include the log sequence number as part of the filename and %t to include the thread number. Use capital letters (%S and %T) to pad the filename to the left with zeroes. For example, enter:
LOG_ARCHIVE_FORMAT = arch_%t_%s.arc
For example, the above settings will generate archived logs as follows for log sequence numbers 100 and 101 in thread 1:
/disk1/archive/arch_1_100.arc, /disk1/archive/arch_1_101.arc /disk2/archive/arch_1_100.arc, /disk2/archive/arch_1_100.arc
See Also: For more information about archiving to standby databases, see Oracle8i Backup and Recovery Guide.
The LOG_ARCHIVE_DEST_STATE_n (where n is an integer from 1 to 5) parameter identifies the status of the specified destination. The destination parameters can have two values: ENABLE and DEFER. ENABLE indicates that Oracle can use the destination, whereas DEFER indicates that it should not.
Each archive destination has three variable characteristics:
Several destination states are possible. Obtain the current destination status information for each instance by querying the V$ARCHIVE_DEST view. You will access the most recently entered parameter definition--which does not necessarily contain the complete archive destination data.
The status information that appears in the view is shown in Table 7-1:
See Also: For detailed information about V$ARCHIVE_DEST as well as the archive destination parameters, see the Oracle8i Reference.
There are two modes of transmitting archived logs to their destination: normal archiving transmission and standby transmission mode. Normal transmission involves transmitting files to a local disk. Standby transmission involves transmitting files via a network to either a local or remote standby database.
In normal transmission mode, the archiving destination is another disk drive of the database server, since in this configuration archiving does not contend with other files required by the instance and completes quickly so the group can become available to LGWR. Specify the destination with either the LOG_ARCHIVE_DEST_n or LOG_ARCHIVE_DEST parameters.
Ideally, you should permanently move archived redo log files and corresponding database backups from the local disk to inexpensive offline storage media such as tape. Because a primary value of archived logs is database recovery, you want to ensure that these logs are safe should disaster strike your primary database.
In standby transmission mode, the archiving destination is either a local or remote standby database.
If you are operating your standby database in managed recovery mode, you can keep your standby database in sync with your source database by automatically applying transmitted archive logs.
To transmit files successfully to a standby database, either ARCn or a server process must do the following:
Each ARCn process creates a corresponding RFS for each standby destination. For example, if three ARCn processes are archiving to two standby databases, then Oracle establishes six RFS connections.
You can transmit archived logs through a network to a remote location by using Net8. Indicate a remote archival by specifying a Net8 service name as an attribute of the destination. Oracle then translates the service name, which you set by means of the SERVICE_NAME parameter, through the tnsnames.ora file to a connect descriptor. The descriptor contains the information necessary for connecting to the remote database. Note that the service name must have an associated database SID, so that Oracle correctly updates the log history of the control file for the standby database.
The RFS process, which runs on the destination node, acts as a network server to the ARCn client. Essentially, ARCn pushes information to RFS, which transmits it to the standby database.
The RFS process, which is required when archiving to a remote destination, is responsible for the following tasks:
Archived redo logs are integral to maintaining a standby database, which is an exact replica of a database. You can operate your database in standby archiving mode, which automatically updates a standby database with archived redo logs from the original database.
See Also: For a detailed description of standby databases, see the relevant chapter in the Oracle8i Backup and Recovery Guide.
For information about Net8, see the Net8 Administrator's Guide.
Sometimes archive destinations can fail, which can obviously cause problems when you operate in automatic archiving mode. To minimize the problems associated with destination failure, Oracle8i allows you to specify:
The optional parameter LOG_ARCHIVE_MIN_SUCCEED_DEST=n (where n is an integer from 1 to 5) determines the minimum number of destinations to which Oracle must successfully archive a redo log group before it can reuse online log files. The default value is 1.
Using the LOG_ARCHIVE_DEST_n parameter, you can specify whether a destination has the attributes OPTIONAL (default) or MANDATORY. The LOG_ARCHIVE_MIN_SUCCEED_DEST=n parameter uses all MANDATORY destinations plus some number of OPTIONAL non-standby destinations to determine whether LGWR can over-write the online log.
When determining whether how to set your parameters, note that:
If you wish, you can also determine whether destinations are mandatory or optional by using the LOG_ARCHIVE_DEST and LOG_ARCHIVE_DUPLEX_DEST parameters. Note the following rules:
You can see the relationship between the LOG_ARCHIVE_DEST_n and LOG_ARCHIVE_MIN_SUCCEED_DEST parameters most easily through sample scenarios. In example 1, you archive to three local destinations, each of which you declare as OPTIONAL. Table 7-2 illustrates the possible values for LOG_ARCHIVE_MIN_SUCCEED_DEST=n in our example.
This example shows that even though you do not explicitly set any of your destinations to MANDATORY using the LOG_ARCHIVE_DEST_n parameter, Oracle must successfully archive to these locations when LOG_ARCHIVE_MIN_SUCCEED_DEST is set to 1, 2, or 3.
In example 2, consider a case in which:
Table 7-3 shows the possible values for LOG_ARCHIVE_MIN_SUCCEED_DEST=n:
This example shows that Oracle must archive to the destinations you specify as MANDATORY, regardless of whether you set LOG_ARCHIVE_MIN_SUCCEED_DEST to archive to a smaller number.
See Also: For additional information about LOG_ARCHIVE_MIN_SUCCEED_DEST=n or any other parameters that relate to archiving, see the Oracle8i Reference.
Use the REOPEN attribute of the LOG_ARCHIVE_DEST_n parameter to determine whether and when ARCn attempts to re-archive to a failed destination following an error. REOPEN applies to all errors, not just OPEN errors.
REOPEN=n sets the minimum number of seconds before ARCn should try to reopen a failed destination. The default value for n is 300 seconds. A value of 0 is the same as turning off the REOPEN option, in other words, ARCn will not attempt to archive after a failure. If you do not specify the REOPEN keyword, ARCn will never reopen a destination following an error.
You cannot use REOPEN to specify a limit on the number of attempts to reconnect and transfer archived logs. The REOPEN attempt either succeeds or fails, in which case the REOPEN information is reset.
If you specify REOPEN for an OPTIONAL destination, Oracle can overwrite online logs if there is an error. If you specify REOPEN for a MANDATORY destination, Oracle stalls the production database when it cannot successfully archive. This scenario requires you to:
When using the REOPEN keyword, note that:
For most databases, ARCn has no effect on overall system performance. On some large database sites, however, archiving can have an impact on system performance. On one hand, if ARCn works very quickly, overall system performance can be reduced while ARCn runs, since CPU cycles are being consumed in archiving. On the other hand, if ARCn runs extremely slowly, it has little detrimental effect on system performance, but it takes longer to archive redo log files, and can create a bottleneck if all redo log groups are unavailable because they are waiting to be archived.
Use the following methods to tune archiving:
See Also: For more information about tuning a database, see Oracle8i Tuning.
Specify up to ten ARCn processes for each database instance. Enable the multiple processing feature at startup or at runtime by setting the parameter LOG_ARCHIVE_MAX_PROCESSES=n (where n is any integer from 1 to 10). By default, the parameter is set to 0.
Because LGWR automatically increases the number of ARCn processes should the current number be insufficient to handle the current workload, the parameter is intended to allow you to specify the initial number of ARCn processes or to increase or decrease the current number.
Creating multiple processes is especially useful when you:
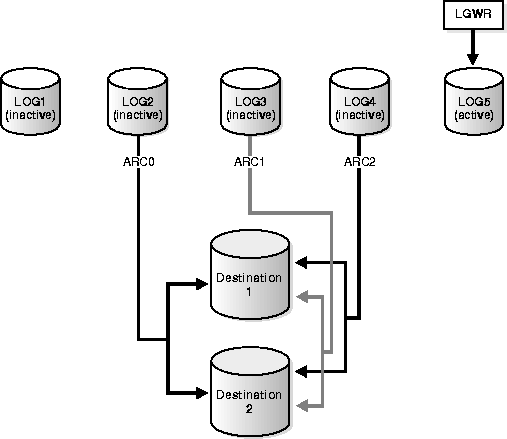
Multiple ARCn processing prevents the bottleneck that occurs when LGWR switches through the multiple online redo logs faster than a single ARCn process can write inactive logs to multiple destinations. Note that each ARCn process works on only one inactive log at a time, but must archive to each specified destination.
For example, if you maintain five online redo log files, then you may decide to start the instance using three ARCn processes. As LGWR actively writes to one of the log files, the ARCn processes can simultaneously archive up to three of the inactive log files to various destinations. As Figure illustrates, each instance of ARCn assumes responsibility for a single log file and archives it to all of the defined destinations.
This section describes aspects of using the archive buffer initialization parameters for tuning, and includes the following topics:
You can tune archiving to cause it to run either as slowly as possible without being a bottleneck or as quickly as possible without reducing system performance substantially. To do so, adjust the values of the initialization parameters LOG_ARCHIVE_BUFFERS (the number of buffers allocated to archiving) and LOG_ARCHIVE_BUFFER_SIZE (the size of each such buffer).
To make ARCn work as slowly as possible without forcing the system to wait for redo logs, begin by setting the number of archive buffers (LOG_ARCHIVE_BUFFERS) to 1 and the size of each buffer (LOG_ARCHIVE_BUFFER_SIZE) to the maximum possible.
If the performance of the system drops significantly while ARCn is working, make the value of LOG_ARCHIVE_BUFFER_SIZE lower until system performance is no longer reduced when ARCn runs.
To improve archiving performance, use multiple archive buffers to force the ARCn process or processes to read the archive log at the same time that they write the output log. You can set LOG_ARCHIVE_BUFFERS to 2, but for a very fast tape drive you may want to set it to 3 or more. Then,set the size of the archive buffers to a moderate number, and increase it until archiving is as fast as you want it to be without impairing system performance.
See Also: This maximum is operating system dependent; see your operating system-specific Oracle documentation. For more information about the LOG_ARCHIVE parameters, see the Oracle8i Reference.
There are several fixed views that contain useful information about archived redo logs.
For example, the following query displays which online redo log group requires archiving:
SELECT group#, archived FROM sys.v$log; GROUP# ARC ---------- --- 1 YES 2 NO
To see the current archiving mode, query the V$DATABASE view:
SELECT log_mode FROM sys.v$database; LOG_MODE ------------ NOARCHIVELOG
The SQL statement ARCHIVE LOG LIST also shows archiving information for the connected instance:
ARCHIVE LOG LIST; Database log mode ARCHIVELOG Automatic archival ENABLED Archive destination destination Oldest online log sequence 30 Next log sequence to archive 32 Current log sequence number 33
This display tells you all the necessary information regarding the archived redo log settings for the current instance:
You must archive all redo log groups with a sequence number equal to or greater than the Next log sequence to archive, yet less than the Current log sequence number. For example, the display above indicates that the online redo log group with sequence number 32 needs to be archived.
See Also: For more information on the data dictionary views, see the Oracle8i Reference.
The Oracle utility LogMiner allows you to read information contained in online and archived redo logs based on selection criteria. LogMiner's fully relational SQL interface provides direct access to a complete historical view of a database--without forcing you to restore archived redo log files.
This section contains the following topics:
LogMiner is especially useful for identifying and undoing logical corruption. LogMiner processes redo log files, translating their contents into SQL statements that represent the logical operations performed to the database. The V$LOGMNR_CONTENTS view then lists the reconstructed SQL statements that represent the original operations (SQL_REDO column) and the corresponding SQL statement to undo the operations (SQL_UNDO column). Apply the SQL_UNDO statements to roll back the original changes to the database.
Furthermore, you can use the V$LOGMNR_CONTENTS view to:
See Also: For more information about the LogMiner data dictionary views, see the Oracle8i Reference.
LogMiner has the following usage and compatibility requirements. LogMiner only:
LogMiner runs in an Oracle instance with the database either mounted or unmounted. LogMiner uses a dictionary file, which is a special file that indicates the database that created it as well as the time the file was created. The dictionary file is not required, but is recommended.
Without a dictionary file, the equivalent SQL statements will use Oracle internal object IDs for the object name and present column values as hex data. For example, instead of the SQL statement:
INSERT INTO emp(name, salary) VALUES ('John Doe', 50000);
LogMiner will display:
insert into Object#2581(col#1, col#2) values (hextoraw('4a6f686e20446f65'), hextoraw('c306'));"
Create a dictionary file by mounting a database and then extracting dictionary information into an external file. You must create the dictionary file from the same database that generated the log files you want to analyze. Once created, you can use the dictionary file to analyze redo logs.
When creating the dictionary, specify the following:
init.ora parameter UTL_FILE_DIR. If you do not reference this parameter, the procedure will fail. For example, set the following to use /oracle/logs:
UTL_FILE_DIR = /oracle/logs
STARTUP
dictionary.ora in /oracle/logs:
EXECUTE dbms_logmnr_d.build( dictionary_filename =>'dictionary.ora', dictionary_location => '/oracle/logs');
Although LogMiner only runs on databases of release 8.1 or higher, you can use it to analyze redo logs from release 8.0 databases.
dbmslogmnrd.sql script, which is contained in the $ORACLE_HOME/rdbms/admin directory on the Oracle8i database, to the same directory in the Oracle8 database. For example, enter:
% cp /8.1/oracle/rdbms/admin/dbmslogmnrd.sql /8.0/oracle/rdbms/admin/dbmslogmnrd.sql
STARTUP
dbmslogmnrd.sql script on the 8.0 database to create the DBMS_LOGMNR_D package. For example, enter:
@dbmslogmnrd.sql
init.ora parameter UTL_FILE_DIR. If you do not reference this parameter, the procedure will fail. For example, set the following to use /8.0/oracle/logs:
UTL_FILE_DIR = /8.0/oracle/logs
dictionary.ora in /8.0/oracle/logs:
EXECUTE dbms_logmnr_d.build( dictionary_filename =>'dictionary.ora', dictionary_location => '/8.0/oracle/logs');
See Also: For information about DBMS_LOGMNR_D, see the Oracle8i Supplied Packages Reference.
Once you have created a dictionary file, you can begin analyzing redo logs. Your first step is to specify the log files that you want to analyze using the ADD_LOGFILE procedure. Use the following constants:
startup
/oracle/logs/log1.f:
execute dbms_logmnr.add_logfile( LogFileName => '/oracle/logs/log1.f', Options => dbms_logmnr.NEW);
/oracle/logs/log2.f:
execute dbms_logmnr.add_logfile( LogFileName => '/oracle/logs/log2.f', Options => dbms_logmnr.ADDFILE);
/oracle/logs/log2.f:
execute dbms_logmnr.add_logfile( LogFileName => '/oracle/logs/log2.f', Options => dbms_logmnr.REMOVEFILE);See Also: For information about DBMS_LOGMNR, see the Oracle8i Supplied Packages Reference.
Once you have created a dictionary file and specified which logs to analyze, you can start LogMiner and begin your analysis. Use the following options to narrow the range of your search at start time:
Once you have started LogMiner, you can make use of the following data dictionary views for analysis:
/oracle/dictionary.ora, issue:
execute dbms_logmnr.start_logmnr( DictFileName =>'/oracle/dictionary.ora');
Optionally, set the StartTime and EndTime parameters to filter data by time. Note that the procedure expects date values: use the TO_DATE function to specify date and time, as in this example:
execute dbms_logmnr.start_logmnr( DictFileName => `/oracle/dictionary.ora', StartTime => to_date(`01-Jan-98 08:30:00', 'DD-MON-YYYY HH:MI:SS') EndTime => to_date('01-Jan-1998 08:45:00', 'DD-MON-YYYY HH:MI:SS'));
Use the StartScn and EndScn parameters to filter data by SCN, as in this example:
execute dbms_logmnr.start_logmnr( DictFileName => '/oracle/dictionary.ora', StartScn => 100, EndScn => 150);
SELECT operation, sql_redo FROM v$logmnr_contents; OPERATION SQL_REDO --------- ---------------------------------------------------------- INTERNAL INTERNAL START set transaction read write; UPDATE update SYS.UNDO$ set NAME = 'RS0', USER# = 1, FILE# = 1, BLOCK# = 2450, SCNBAS = COMMIT commit; START set transaction read write; UPDATE update SYS.UNDO$ set NAME = 'RS0', USER# = 1, FILE# = 1, BLOCK# = 2450, SCNBAS = COMMIT commit; START set transaction read write; UPDATE update SYS.UNDO$ set NAME = 'RS0', USER# = 1, FILE# = 1, BLOCK# = 2450, SCNBAS = COMMIT commit; 11 rows selected.
See Also: For information about DBMS_LOGMNR, see the Oracle8i Supplied Packages Reference.
For more information about the LogMiner data dictionary views, see Oracle8i Reference.
You can run LogMiner on an instance of a database while analyzing redo log files from a different database. To analyze archived redo log files from other databases, LogMiner must:
This section contains the following LogMiner scenarios:
In this example, you are interested in seeing all changes to the database in a specific time range by one of yours users: JOEDEVO. You perform this operation in the following steps:
To use the LogMiner to analyze JOEDEVO's data, you must create a dictionary file before starting LogMiner.
You decide to do the following:
orc1dict.ora.
/user/local/dbs.
/user/local/dbs.
# Set the initialization parameter UTL_FILE_DIR in the init.ora file UTL_FILE_DIR = /user/local/dbs # Start SQL*Plus and then connect to the database connect system/manager # Open the database to create the dictionary file startup # Create the dictionary file execute dbms_logmnr_d.build( dictionary_filename => `orcldict.ora', dictionary_location => `/usr/local/dbs'); # The dictionary has been created and can be used later shutdown;
Now that the dictionary is created, you decide to view the changes that happened at a specific time. You do the following:
log1orc1.ora.
log2orc1.ora to the list.
# Start SQL*Plus, connect as SYSTEM, then start the instance connect system/manager startup nomount # Supply the list of logfiles to the reader. The Options flag is set to indicate this is a # new list. execute dbms_logmnr.add_logfile( Options => dbms_logmnr.NEW, LogFileName => `log1orc1.ora'); # Add a file to the existing list. The Options flag is clear to indicate that you are # adding a file to the existing list execute dbms_logmnr.add_logfile(Options => dbms_logmnr.ADDFILE, LogFileName => `log2orc1.ora');
At this point the V$LOGMNR_CONTENTS table is available for queries. You decide to find all changes made by user JOEDEVO to the salary table. As you discover, JOEDEVO requested two operations: he deleted his old salary and then inserted a new, higher salary. You now have the data necessary to undo this operation (and perhaps to justify firing JOEDEVO!).
# Start the LogMiner. Limit the search to the specified time range. execute dbms_logmnr.start_logmnr( DictFileName => `orcldict.ora', StartTime => to_date(`01-Jan-98 08:30:00', 'DD-MON-YYYY HH:MI:SS') EndTime => to_date('01-Jan-1998 08:45:00', 'DD-MON-YYYY HH:MI:SS')); SELECT sql_redo, sql_undo FROM v$logmnr_contents WHERE username = `JOEDEVO' AND tablename = `SALARY'; # The following data is displayed (properly formatted) SQL_REDO SQL_UNDO -------- -------- delete * from SALARY insert into SALARY(NAME,EMPNO, SAL) where EMPNO = 12345 values (`JOEDEVO', 12345,500) and ROWID = `AAABOOAABAAEPCABA'; insert into SALARY(NAME, EMPNO, SAL) delete * from SALARY values(`JOEDEVO',12345,2500) where EMPNO = 12345 and ROWID = `AAABOOAABAAEPCABA'; 2 rows selected
The redo logs generated by Oracle RDBMS contain the history of all changes made to the database. Mining the redo logs can thus generate a wealth of information that can be used for tuning the database. In this example, you manage a direct marketing database and want to determine how productive the customer contacts have been in generating revenue for a two week period in August.
First, you start LogMiner and specify a range of times:
execute dbms_logmnr.start_logmnr( StartTime => `07-Aug-98', EndTime => `15-Aug-98', DictFileName => `/usr/local/dict.ora');
Next, you query V$LOGMNR_CONTENTS to determine which tables have been modified in the time range you specified:
select seg_owner, seg_name, count(*) as Hits from V$LOGMNR_CONTENTS where seg_name not like `%$' group by seg_owner, seg_name; SEG_OWNER SEG_NAME Hits --------- -------- ---- CUST ACCOUNT 384 SCOTT EMP 12 SYS DONOR 12 UNIV DONOR 234 UNIV EXECDONOR 325 UNIV MEGADONOR 32
See Also: For detailed information about V$LOGMNR_CONTENTS or any of the LogMiner views or initialization parameters, see the Oracle8i Reference.
For information about DBMS_LOGMNR.ADD_LOGFILE or any other PL/SQL packages, see the Oracle8i Supplied Packages Reference.