Release 8.0
A54651-01
Library |
Product |
Contents |
Index |
| Oracle8(TM) Server Replication Release 8.0 A54651-01 |
|
![]()
![]()
This chapter explains how to configure and manage a basic replication environment using read-only table snapshots. This chapter covers the following topics.
Note: Examples appear throughout this chapter of how to use both SQL commands and Oracle's Enterprise Manager to build and manage a basic replication system. For complete information about Enterprise Manager, see your Enterprise Manager documentation.
To create a basic replication environment that uses table snapshots to provide read-only access to a master site, you must complete the following steps:
For detailed information about each step, see the later sections of this chapter.
The following simple example demonstrates the steps necessary to build a basic replication environment.
The first step is to design the basic replication environment. This example demonstrates how to replicate the tables SCOTT.EMP and SCOTT.DEPT at the master site DBS1 using corresponding snapshots in DBS2.
Note: The primary key of SCOTT.EMP is the EMPNO column, and the primary key of SCOTT.DEPT is the DEPTNO column.
The master site, DBS1, already has the schema SCOTT with the tables EMP and DEPT, which have primary keys. The snapshot site must have a corresponding schema SCOTT to contain the proposed snapshots. Additionally, the snapshot schema SCOTT must have a private database link that establishes connections to the corresponding schema at the master site.
The following SQL command script completes schema and database link setup at the snapshot site.
CONNECT system/manager@dbs2; CREATE USER scott IDENTIFIED BY tiger QUOTA UNLIMITED ON data; GRANT CONNECT TO scott; CONNECT scott/tiger@dbs2; CREATE DATABASE LINK dbs1 CONNECT TO scott IDENTIFIED BY tiger;
Before creating snapshots, you should create the master site snapshot logs that will be necessary to support fast refreshes for the snapshots. The following SQL command script demonstrates how to create the snapshot logs at the master site that are necessary to support the snapshots.
CONNECT system/manager@dbs1; CREATE SNAPSHOT LOG ON scott.emp; CREATE SNAPSHOT LOG ON scott.dept;
Once the necessary snapshot logs are in place, you can create the snapshots. The following SQL command script demonstrates how to create the snapshots SCOTT.EMP and SCOTT.DEPT at the snapshot site.
CONNECT system/manager@dbs2; CREATE SNAPSHOT scott.emp AS SELECT * FROM scott.emp@dbs1.acme.com; CREATE SNAPSHOT scott.dept AS SELECT * FROM scott.dept@dbs1.acme.com;
After creating snapshots, make sure to assign all related snapshots to a refresh group that they will use to refresh. The following SQL command script demonstrates how to create and schedule the refresh group SCOTT.REFGRP1 at the snapshot site and assign to it the new EMP and DEPT snapshots.
CONNECT system/manager@dbs2; DBMS_REFRESH.MAKE(
name => 'scott.refgrp1',
list => 'scott.dept,scott.emp',
next_date => SYSDATE,
interval => 'SYSDATE+1/24'); COMMIT;
After configuring snapshots, grant access so that users can use them.
GRANT SELECT ON scott.emp TO ... ;
Before building snapshots in a basic replication environment, you must prepare for the snapshots at each snapshot site. Specifically, each snapshot site must have the schemas and database links necessary to support the proposed snapshots. To simplify the configuration of a basic replication environment, implement the schema and database link design that Figure 2-1 and the following sections explain.
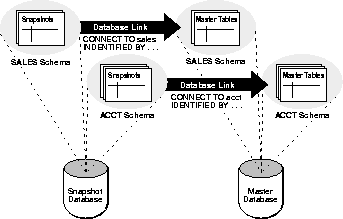
A schema that contains a snapshot in a snapshot database should correspond to the schema that contains the master table in the master database. Therefore, identify the tables and encompassing schemas in the master database that you want to replicate using read-only table snapshots. Then, in the snapshot database, create accounts with the same names as the schemas that contain master tables in the master database. For example, if all master tables are in the SALES schema of the DB1 database, create a corresponding SALES account in the snapshot database DB2.
The defining query of a snapshot uses one or more database links to reference remote table data. Before creating snapshots, the database links that you plan to use with snapshots must be available. Furthermore, the account that a database link uses to access a remote database defines the security context under which Oracle creates and subsequently refreshes a snapshot.
To ensure proper behavior, a snapshot's defining query must use a database link that includes an embedded user name and password in its definition. This type of database link always establishes connections to the remote database using the specified account. Additionally, the remote account that the link uses must have the privileges necessary to access the data referenced in the snapshot's defining query.
To simplify the setup of a basic replication environment, create a private database link from each snapshot schema in the snapshot database to the corresponding schema in the master database. Be sure to embed the associated master database account information in each private database link at the snapshot database. For example, the SALES schema at a snapshot database DB2 should have a private database link DB1 that connects using the SALES username and password.
Before you create snapshots, you should have an idea of how you would like to refresh them using snapshot refresh groups. Some planning will help make the configuration of refresh groups much easier.
Privilege management can be challenging in a basic replicated environment. To create and refresh a snapshot, both the creator and snapshot owner must be able to issue the defining query of the snapshot. This capability depends directly on the database link that the snapshot's defining query uses to access the master table of the snapshot. To simplify privilege management for snapshot refreshes in a basic replication environment, use the recommended schema/database link setup described in the previous sections.
Refresh groups not only provide a mechanism to refresh a number of snapshots efficiently as a group, but also allow you to preserve the referential integrity and transaction consistency among the table snapshots of several related master tables. After refreshing all of the snapshots in a refresh group, the data of all snapshots in the group corresponds to the same transaction consistent point in time.
Before building a basic replication environment, identify the snapshots that require referential and transaction integrity. Then group related snapshots accordingly into the same refresh group.
Note: Do not arbitrarily group snapshots together to form large refresh groups. Snapshot refreshes of an unnecessarily large refresh group can generate a significant amount of rollback data that requires the use of a large rollback segment.
Additionally, it's important to decide how often applications will require a refresh of its snapshots. If the master tables receive predictable updates, automatically refresh the associated snapshots at the appropriate interval.
To simplify administration, most basic replication environments configure refresh groups to refresh all snapshots automatically. Each snapshot database in a basic replication environment must start one or more SNP background processes to support the automatic refresh of snapshot refresh groups. The following initialization parameters control the SNP background process setting for each server.
Every master table must have an associated snapshot log to support efficient, fast refreshes of corresponding snapshots. If a master table does not have an associated snapshot log, then complete refreshes of corresponding snapshots are the only option.
Oracle creates the snapshot log for a master table in the same database as the table. A master table's snapshot log is a table itself. When a transaction changes information in the master table, an internal trigger on the master table automatically inserts rows into the corresponding snapshot log. Rows in a snapshot log list changes that have been made to the master table, as well as information about which snapshots have and have not been updated to reflect the changes at the master table.
A snapshot log is associated with a single master table; likewise, a master table can have only one snapshot log. When a master table is the data source for several different snapshots (perhaps in different databases), all snapshots of the master table use the same snapshot log.
Note: For complete information about managing snapshot logs, see "Managing Snapshot Logs" on page 2-28.
To create a snapshot log for a master table, you can use Enterprise Manager's Schema Manager application or the SQL command CREATE SNAPSHOT LOG. The following example creates a snapshot log.

The equivalent CREATE SNAPSHOT LOG statement is:
CREATE SNAPSHOT LOG ON scott.emp;
Before creating a snapshot log for a master table, you should consider several issues, as the described in the sections that follow.
When you create a snapshot log for a master table, Oracle automatically creates the log as a table MLOG$_master_table_name in the schema that contains the master table. If a master table name is longer than 20 bytes, Oracle truncates the master_table_name portion at 20 bytes and appends the name with a four-digit number to ensure uniqueness. This guarantees that the objects comply with the naming rules for schema objects.
The privileges required to create a snapshot log directly relate to the privileges necessary to create the underlying objects associated with a snapshot log.
In either case, the owner of the snapshot log must have sufficient quota in the tablespace intended to hold the snapshot log.
If you plan to perform a fast refresh for snapshots, be sure to create a corresponding snapshot log for the snapshot's master table before creating the snapshot. If you create the snapshot log after the snapshot, Oracle will perform the first refresh of the snapshot as a complete refresh rather than a fast refresh.
By default, Oracle creates a snapshot log to support primary key snapshots. Therefore, the master table must contain a valid PRIMARY KEY constraint before you can create a snapshot log.
You can set the storage options for a snapshot log during creation using the Storage page of the Create Snapshot Log property sheet in Schema Manager.

In general, it is best to set a snapshot log's storage options as follows:
To support a simple snapshot that uses a subquery in its defining query, the following requirements must be met:
Note: Columns that use a LOB datatype cannot be filter columns.
See "Advanced Subsetting with Subqueries" on page 2-16 for several examples of snapshot logs with filter columns that are necessary to support snapshots with subqueries.
When you create a snapshot log, Oracle performs several operations internally:
The schema that contains a master table also contains the base table for its snapshot log.
Caution: Do not alter or change data in the underlying table that supports a snapshot log.
To create a read-only snapshot, you can use the Create Snapshot property sheet of Enterprise Manager's Schema Manager application or the SQL command CREATE SNAPSHOT.
Note: For complete information about managing snapshots, see "Managing Read-Only Snapshots" on page 2-34.
The following example creates a simple, read-only snapshot.
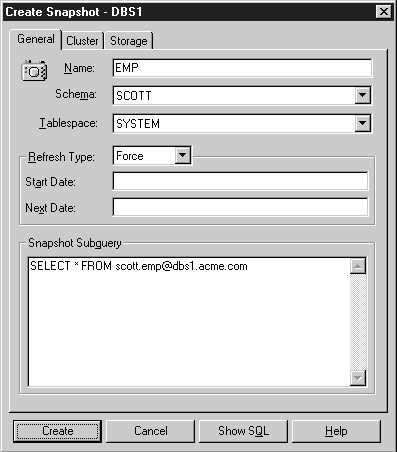
The equivalent CREATE SNAPSHOT statement is:
CREATE SNAPSHOT scott.emp
AS SELECT * FROM scott.emp@dbs1.acme.com;
Before creating a read-only table snapshot, consider the issues discussed in the sections that follow.
A snapshot name must be unique within the encompassing schema. A snapshot name can be up to 30 bytes in length; however, keep snapshot names to 19 or fewer bytes when possible. When a snapshot name contains more than 19 bytes, Oracle automatically truncates the prefixed names of the underlying table, and appends them with a four-digit number to ensure that new object names will be unique and comply with the naming rules for schema objects.
Several privileges are necessary to create a fully functional snapshot.
By default, Oracle creates all new snapshots as primary key snapshots. To create a snapshot:
Although Schema Manager and the CREATE SNAPSHOT command allows you to specify refresh settings for individual snapshots, you should always refresh a snapshot as part of a refresh group. See "Creating Refresh Groups" on page 2-25 for more information about configuring snapshot refreshes with refresh groups. Additionally, see "Individual Snapshot Refreshes" on page 2-44 for more information about configuring an individual snapshot for refresh.
When you create a new snapshot, consider the following issues that relate to the query that defines the snapshot's structure.
A snapshot's defining query can reference master table columns that use the following Oracle datatypes: NUMBER, DATE, CHAR, VARCHAR2, NCHAR, NVARCHAR2, RAW, ROWID, BLOB, CLOB, and NCLOB. Snapshots cannot include columns that use the LONG, LONG RAW, or BFILE datatypes. Additionally, Oracle does not support user-defined object types within snapshots.
Oracle propagates BLOBs, CLOBs, and NCLOBs during fast refresh only when:
A snapshot's defining query cannot reference a LOB column in its WHERE clause.
To create a simple snapshot, the snapshot's defining query cannot contain the following SQL attributes:
When a snapshot definition uses any of the above attributes, the snapshot is a complex snapshot. Oracle cannot use a snapshot log to perform fast refreshes for a complex snapshot.
Always design the defining query of a snapshot so that it explicitly references its remote data. Otherwise, the snapshot might reference different remote data during snapshot creation and subsequent refreshes. For example, consider when SCOTT creates a snapshot using the following commands:
CONNECT scott/tiger
CREATE DATABASE LINK sales.hq.com USING 'hq.sales.com';
CREATE SNAPSHOT emp AS SELECT * FROM emp@sales.hq.com;
In this example, the snapshot definition implicitly references the remote table SCOTT.EMP because the database link establishes a connection to the remote database as SCOTT/TIGER during snapshot creation. Instead, simply make the remote table reference explicit, as the following example shows.
CREATE SNAPSHOT emp AS SELECT * FROM scott.emp@sales.hq.com;
To identify clearly the remote data to which a snapshot corresponds, the snapshot's defining query should
You can set the storage options for a snapshot during creation using the Storage page of the Create Snapshot property sheet in Schema Manager.

In general, a simple snapshot's storage options should mimic the storage options for its master table, because they share the same characteristics. However, if a simple snapshot does not duplicate all columns of its master table, modify the snapshot storage items accordingly.
When a number of master tables are clustered in the master database, consider clustering the corresponding snapshots in the remote database. To create a snapshot as part of a data cluster, use the Cluster page of the Create Snapshot property sheet in Schema Manager.

When you create a snapshot in a data cluster, Oracle always uses the storage parameters of the cluster's data segment.
By default, when you create a snapshot, Oracle immediately executes the defining query of the snapshot to populate the snapshot's base table with the rows of the corresponding master table. In large replicated environments, you should consider using snapshot cloning to reduce the network overhead necessary to create snapshot databases. For more information about snapshot cloning, see "Snapshot Cloning and Offline Instantiation" on page 7-15.
In many cases, a snapshot must correspond to a subset of the rows in its master table. Often, you can use a simple WHERE clause in the defining query of a snapshot to identify the subset of master table rows. For example, consider a corporate salesforce automation system that defines the sales territory of each salesperson by the zip codes of customers. Each salesperson's personal computer database must maintain only the information about the customers in his or her sales territory, as well as the corresponding orders. For instance, a salesperson that is responsible for customers with the zip code 19555 can create a snapshot to provide read-only access to the customers in the corresponding sales territory.
CREATE SNAPSHOT sales.customers AS
SELECT * FROM sales.customers@dbs1.acme.com
WHERE zip = 19555;
This simple example shows how to create basic subsetting for simple snapshots. More advanced subsetting often requires the use of a subquery in a snapshot's defining query. The following sections extend the example above to explain the benefits of subquery snapshots. Each related example explains how to create a snapshot with a subquery.
A snapshot that uses a subquery can be a flexible solution for advanced subsetting requirements. The following examples demonstrate the creation and advantages of snapshots with subqueries in the fictional salesforce automation system described above. In the following examples, the name of the central company database is hq.acme.com. The following CREATE table commands describe some of the important master tables of the salesforce automation system in the SALES schema at the central company database:
CUSTOMERS Table
CREATE TABLE sales.customers
( c_id INTEGER PRIMARY KEY,
zip INTEGER
-- other columns defined here
);
ORDERS Table
CREATE TABLE sales.orders
( o_id INTEGER PRIMARY KEY,
c_id INTEGER
-- other columns defined here
);
ORDER_LINES Table
CREATE TABLE sales.order_lines
( ol_id INTEGER,
o_id INTEGER,
PRIMARY KEY (ol_id, o_id)
-- other columns defined here
);
ASSIGNMENTS Table
CREATE TABLE sales.assignments
( c_id INTEGER,
s_id INTEGER,
PRIMARY KEY (c_id, s_id)
);
SALESPERSONS Table
CREATE TABLE sales.salespersons
( s_id INTEGER PRIMARY KEY,
s_name VARCHAR2(30) UNIQUE
-- other columns defined here
);
To create snapshots that can refresh with fast refreshes, snapshot logs must also exist for the corresponding master tables. For each master table that will be referenced by a snapshot that uses a subquery, the associated snapshot log must include the appropriate filter columns. The following SQL commands build the necessary snapshot logs at the central database, hq.acme.com.
CREATE SNAPSHOT LOG ON sales.customers
WITH PRIMARY KEY (zip); CREATE SNAPSHOT LOG ON sales.orders
WITH PRIMARY KEY (c_id); CREATE SNAPSHOT LOG ON sales.order_lines
WITH PRIMARY KEY; CREATE SNAPSHOT LOG ON sales.assignments
WITH PRIMARY KEY; CREATE SNAPSHOT LOG ON sales.salespersons
WITH PRIMARY KEY (s_name);
The following examples also assume that the corresponding SALES schema and private database link that are necessary to support the snapshots already exist in the spdb1.acme.com database.
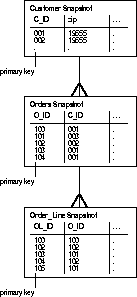
The CUSTOMERS snapshot in the previous section provides read-only access to the salesperson's customer records. The salesperson also requires snapshots that provide read-only access to the order information that corresponds to the salesperson's customers. One technique would be to add a zip code column to the master ORDERS and ORDER_LINES tables and then define simple snapshots similar to the CUSTOMERS snapshot. However, such denormalization of the master tables is not typically desirable and can be difficult to maintain. A better solution is to define snapshots on the ORDERS and ORDER_LINES master tables that reference the zip code column in the CUSTOMERS table using a subquery.
The following SQL commands show how to create snapshots of the ORDERS and ORDER_LINES master tables that contain the orders and line items that correspond to the salesperson's sales territory:
CREATE SNAPSHOT sales.orders AS
SELECT * FROM sales.orders@hq.acme.com o
WHERE EXISTS
( SELECT c_id FROM sales.customers@hq.acme.com c
WHERE o.c_id = c.c_id AND zip = 19555);
CREATE SNAPSHOT sales.order_lines AS
SELECT * FROM sales.order_lines@hq.acme.com ol
WHERE EXISTS
( SELECT o_id FROM sales.orders@hq.acme.com o
WHERE ol.o_id = o.o_id
AND EXISTS
( SELECT c_id FROM sales.customers@hq.acme.com c
WHERE o.c_id = c.c_id AND zip = 19555));
The subqueries in the example snapshots walk up the many-to-one references from the child to parent tables that may involve one or multiple levels. When these snapshots are created, Oracle fills the snapshot base tables with all orders or order line rows that belong to customers whose zip code column values match the snapshot selection criterion. Subsequent fast refreshes return only the rows that have changed since snapshot creation or since the last refresh.
If a zip code column is updated so that a customer no longer satisfies the selection criterion of the snapshot, the orders and order line rows for the customer will be removed from the snapshots during the next refresh. If a zip code column in another customer row is updated so that it now satisfies the selection criterion of the snapshot, the customer's orders and order line rows will be added during the next refresh.
The snapshots that the previous section define derive their subsets of the CUSTOMERS, ORDERS, and ORDER_LINES tables by embedding a zip code into each snapshot's defining query. Consequently, the snapshots cannot accommodate a simple change in the salesperson's territory-for example, the snapshots would have to be rebuilt if the salesperson's sales territory zip code changed from 19555 to 19500. For greater flexibility, the snapshots in the following example show how subqueries can also traverse many-to-many references between tables in selected cases.
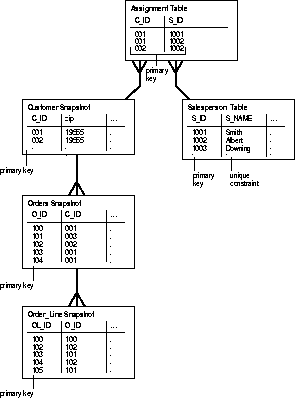
This example makes use of the SALESPERSONS and ASSIGMENTS tables. Each salesperson has a row in the SALESPERSONS table that maps their S_ID to their name. The ASSIGNMENTS table maps customers to salespersons, i.e., C_ID to S_ID. The ASSIGNMENTS table implements a many-to-many relationship between CUSTOMER and SALESPERSON: A salesperson can have multiple customers; a customer can have multiple salespersons.
The following SQL commands create new CUSTOMERS, ORDERS, and ORDER_LINES snapshots that can be fast refreshed.
CUSTOMERS Snapshot
CREATE SNAPSHOT sales.customers AS
SELECT * FROM sales.customers@hq.acme.com c
-- conditions for customers
WHERE EXISTS
( SELECT * FROM sales.assignments@hq.acme.com a
WHERE a.c_id = c.c_id
AND EXISTS
( SELECT * FROM sales.salespersons@hq.acme.com s
WHERE s.s_id = a.s_id AND s_name = 'gsmith'));
ORDERS Snapshot
CREATE SNAPSHOT sales.orders AS
SELECT * FROM sales.orders@hq.acme.com o
-- conditions for customers
WHERE EXISTS
( SELECT c_id FROM sales.customers@hq.acme.com c
WHERE o.c_id = c.c_id
AND EXISTS
( SELECT * FROM sales.assignments@hq.acme.com a
WHERE a.c_id = c.c_id
AND EXISTS
( SELECT * FROM sales.salespersons@hq.acme.com s
WHERE s.s_id = a.s_id AND s_name = 'gsmith')));
ORDER_LINES Snapshot
CREATE SNAPSHOT sales.order_lines AS
SELECT * FROM sales.order_lines@hq.acme.com ol
WHERE EXISTS
( SELECT o_id FROM sales.orders@hq.acme.com o
WHERE ol.o_id = o.o_id
AND EXISTS
( SELECT c_id FROM sales.customers@hq.acme.com c
WHERE o.c_id = c.c_id
-- conditions for customers
AND EXISTS
( SELECT * FROM sales.assignments@hq.acme.com a
WHERE a.c_id = c.c_id
AND EXISTS
( SELECT * FROM sales.salespersons@hq.acme.com s
WHERE s.s_id = a.s_id AND s_name = 'gsmith'))));
These subqueries walk up the many-to-one references from ORDER_LINES to ORDERS to CUSTOMERS and traverse the many-to-many references between CUSTOMERS and SALESPERSONS using the ASSIGNMENTS table. Again, when the CUSTOMERS, ORDERS, and ORDER_LINES snapshots are created, Oracle fills the snapshot base tables with all customer, order, and order line rows that belong to customers who have been assigned to the salesperson. Subsequent fast refreshes return only the rows that have changed since snapshot creation or since the last refresh. If an ASSIGNMENTS record is deleted or updated so that a customer is no longer assigned to the salesperson, the customer, order, and order line rows for the salesperson will be removed from the snapshots during the next refresh. If an ASSIGNMENTS record is inserted or updated so that a customer is now assigned to the salesperson, the appropriate customer, order, and order line rows will be added during the next refresh.
To avoid the join to the SALESPERSONS table, the previous snapshot definitions with subqueries could also be defined using only the ASSIGNMENTS table. For example, you could create the CUSTOMERS snapshot using only a reference to the S_ID column the ASSIGNMENTS table as follows:
CREATE SNAPSHOT sales.customers AS
SELECT * FROM sales.customers@dbs1.acme.com c
-- conditions for customers
WHERE EXISTS
( SELECT * FROM sales.assignments@dbs1.acme.com a
WHERE a.c_id = c.c_id AND a.s_id = 1001);
Using subqueries that traverse many-to-many relationships can provide greater flexibility in many cases. Note that in Example 2, salespeople can be assigned to different territories and hence different customers by performing the appropriate changes to the ASSIGNMENTS table. In the earlier examples, if a salesperson were assigned different zip codes to cover the snapshots would need to be dropped and re-created to include the new zip code territory assignment in the snapshot definition.
Similarly, in Example 2 the company could change the way territories are defined and allocated. Note that the company could move from a geographic territory scheme based on zip codes to a more elaborate scheme involving vertical industry specializations or national accounts by just rederiving and performing the appropriate updates to the ASSIGNMENTS table. In the first example, additional columns would need to be added to the CUSTOMERS table to contain the vertical industry and/or national account information, and the snapshots would again need to be dropped and re-created to use these new columns.
All issues relevant to simple snapshots are also relevant to snapshots with subqueries. See the section "Creating Simple Snapshots" on page 2-11 for complete information. Additionally, the defining query of a snapshot with a subquery is subject to several other restrictions to preserve the simple snapshot's fast refresh capability.
Note: To determine whether a simple subquery snapshot satisfies the many restrictions below, create the snapshot with "fast refresh." Oracle will return errors if the snapshot violates any restrictions for simple subquery snapshots.
A table snapshot is a representation of its master data as that data existed at a specific moment in time. To keep a snapshot's data relatively current with the data of its master, Oracle must periodically refresh the snapshot. A snapshot refresh is an efficient batch operation that makes that snapshot reflect a more current state of its master.
To preserve referential integrity and transaction consistency among the table snapshots of several related master tables, Oracle organizes and refreshes each snapshot as part of a refresh group. After refreshing all of the snapshots in a refresh group, the data of all snapshots in the group corresponds to the same transaction consistent point in time.
Note: For complete information about managing refresh groups, see "Managing Snapshot Refreshes and Refresh Groups" on page 2-38.
To create a refresh group, you can use Schema Manager or an equivalent call to the DBMS_REFRESH.MAKE procedure.
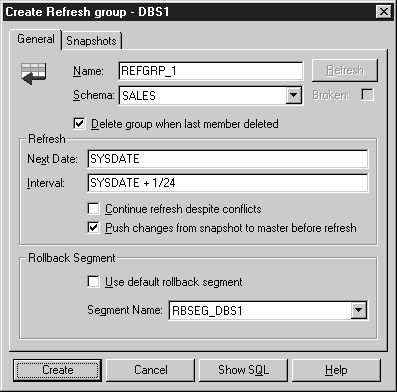
The equivalent call to the DBMS_REFRESH.MAKE procedure is:
DBMS_REFRESH.MAKE(
name => 'sales.refgrp_1',
list => 'sales.customers,sales.orders,sales.order_lines',
next_date => SYSDATE,
interval => 'SYSDATE + 1/24',
implicit_destroy => TRUE,
rollback_seg => 'trs_1'
);
Before creating refresh groups, there are several issues to consider.
When you create a refresh group, you can determine when to first refresh the group and then how often to refresh the group thereafter.
A refresh group's initial refresh is determined by the setting of the Next Date field in the Create Refresh Group property sheet of Schema Manager (the NEXT_DATE parameter of the DBMS_REFRESH.MAKE procedure).
A refresh group's refresh interval determines the automatic refresh interval for all snapshots in the group. When setting a group's automatic refresh interval, understand the following behaviors:
The following examples are typical date expressions you can use for a refresh group's refresh interval.
When you create a refresh group, you can specify other settings that are designed specifically for refresh groups that include updatable snapshots in an advanced replication environment. For basic, read-only replication environments, simply use the default settings. See "Managing Refresh Groups" on page 4-24 for more information about configuring these special refresh group settings with advanced replication systems.
By default, Oracle attempts to refresh each snapshot in a group using a fast refresh. Oracle performs a complete refresh of an individual snapshot in a refresh group only when one of the following situations is true:
When Oracle refreshes the snapshots in a refresh group, the server can generate a significant amount of rollback data. When you create a refresh group, be sure to target a sufficiently large rollback segment for the group's refreshes.
The following sections explain how to manage the various components of a basic replication environment, including snapshot logs, snapshots, and snapshot refresh groups.
The following sections explain how to manage snapshot logs. Topics include:
After you create a snapshot log, you can alter its storage parameters and support for corresponding snapshots. The following sections explain more about altering snapshot logs.
Only the owner of the master table or a user with the SELECT privilege for the master table can alter a snapshot log.
To alter a snapshot log's storage parameters, use the Storage and Options pages of the Snapshot Log property sheet or an equivalent ALTER SNAPSHOT LOG statement. For example:
ALTER SNAPSHOT LOG ON sales.customers
PCTFREE 25
PCTUSED 40;
To add new filter columns to a snapshot log, use the SQL command ALTER SNAPSHOT LOG. For example:
ALTER SNAPSHOT LOG ON sales.customers
ADD (zip);
Oracle automatically tracks which rows in a snapshot log have been used during the refreshes of snapshots, and purges these rows from the log so that the log does not grow endlessly. Because multiple simple snapshots can use the same snapshot log, rows already used to refresh one snapshot may still be needed to refresh another snapshot; Oracle does not delete rows from the log until all snapshots have used them.
For example, Oracle refreshes the CUSTOMERS snapshot at the SPDB1 database. However, the server that manages the master table and associated snapshot log does not purge the snapshot log rows used during the refresh of this snapshot until the CUSTOMERS snapshot at the SPDB2 database also refreshes using these rows.
As a result of how Oracle purges rows from a snapshot log, unwanted situations can occur that cause a snapshot log to grow indefinitely when multiple snapshots are based on the same master table. For example, such situations can occur when more than one snapshot is based on a master table and
Always try to keep a snapshot log as small as possible to minimize the database space that it uses. To remove rows from a snapshot log and free up space for newer log records, you can
To manually purge rows from a snapshot log, execute the PURGE_LOG stored procedure of the DBMS_SNAPSHOT package at the database that contains the log. For example, to purge entries from the snapshot log of the CUSTOMERS table that are necessary only for the least recently refreshed snapshot, execute the following procedure:
DBMS_SNAPSHOT.PURGE_LOG (
master => 'sales.customers',
num => 1,
flag => 'DELETE');
Additional Information: The parameters for the DBMS_SNAPSHOT. PURGE_LOG procedure are described in Table 10-209 on page 10-172.
The owner of a snapshot log or a user with the EXECUTE privilege for the DBMS_SNAPSHOT package can purge rows from the snapshot log by executing the PURGE_LOG procedure.
If a snapshot log grows and allocates many extents, purging the log of rows does not reduce the amount of space allocated for the log. To reduce the space allocated for a snapshot log:
LOCK TABLE sales.customers IN EXCLUSIVE MODE;
CREATE TABLE sales.templog AS SELECT * FROM sales.mlog$_customers;
TRUNCATE sales.mlog$_customers;
INSERT INTO sales.mlog$_customers SELECT * FROM sales.templog; DROP TABLE sales.templog;
ROLLBACK;
Note: Any changes made to the master table between the time you copy the rows to a new location and when you truncate the log do not appear until after you perform a complete refresh.
The owner of a snapshot log or a user with the DELETE ANY TABLE system privilege can truncate a snapshot log.
To improve performance and optimize disk use, you can periodically reorganize ("reorg") tables. This section discusses how to reorganize a master table and preserve the fast refresh capability of associated snapshots.
When you reorganize a table, any ROWID information of the snapshot log must be invalidated. Oracle detects a table reorganization automatically only if the table is truncated as part of the reorg. See "METHOD 2" on page 2-33.
If the table is not truncated, Oracle must be notified of the table reorganization. To support table reorganizations, two procedures, DBMS_SNAPSHOT.BEGIN_TABLE_REORGANIZATION and DBMS_SNAPSHOT.END_TABLE_REORGANIZATION notify Oracle that the specified table has been reorganized. The procedures perform clean-up operations, verify the integrity of the logs and triggers that the fast refresh mechanism needs, and invalidate the ROWID information in the table's snapshot log. The inputs are the owner and name of the master table to be reorganized. There is no output.
When a table is truncated, its snapshot log is also truncated. However, for primary key snapshots, you can preserve the snapshot log, allowing fast refreshes to continue. Although the information stored in a snapshot log is preserved, the snapshot log becomes invalid with respect to ROWIDs when the master table is truncated. The ROWID information in the snapshot log will seem to be newly created and cannot be used by ROWID snapshots for fast refresh.
If you specify the PRESERVE SNAPSHOT LOG option or no option, the information in the master table's snapshot log is preserved, but current ROWID snapshots can use the log for a fast refresh only after a complete refresh has been performed. This is the default.
Note: To ensure that any previously fast refreshable snapshot is still refreshable, follow the guidelines in "Methods of Reorganizing a Database Table" on page 2-33.
If the PURGE SNAPSHOT LOG option is specified, the snapshot log is purged along with the master table.
The following two statements preserve snapshot log information when the master table is truncated:
TRUNCATE TABLE tablename PRESERVE SNAPSHOT LOG;
TRUNCATE TABLE tablename;
The following statement truncates the snapshot log along with the master table:
TRUNCATE TABLE tablename PURGE SNAPSHOT LOG
Oracle provides four methods that enable you to reorganize a table while preserving the capability for fast refresh; see Table 2-1. Other reorg methods require an initial complete refresh to enable subsequent fast refreshes.
Note: Do not use direct loader during a reorg of a master table. (Direct Loader can cause reordering of the columns, which could invalidate the log information used in subquery and LOB snapshots.)
Table 2-1: Methods of Reorganizing a Database Table
You can drop a snapshot log independently of its master table or any existing snapshots. For example, you might decide to drop a snapshot log if one of the following situations is true:
To drop a snapshot log, you can use Schema Manager to remove the log or an equivalent DROP SNAPSHOT LOG statement.
DROP SNAPSHOT LOG ON sales.customers;
Only the owner of the master table or a user with the DROP ANY TABLE system privilege can drop a snapshot log.
The following sections describe how to create and manage read-only snapshots in a basic replication environment. Topics include:
Applications can query snapshots just like a table or view. For example, the following query references a local snapshot named CUSTOMERS.
SELECT * FROM sales.customers;
Applications cannot issue any INSERT, UPDATE, or DELETE statements when using a read-only snapshot; if they do, Oracle returns an error.
Caution: Although applications can issue INSERT, UPDATE, and DELETE statements against the base table of a snapshot, such operations will corrupt the snapshot. Applications should update a master table only, and allow Oracle to refresh the snapshot to make it a more current version of its master table. When applications must update a local snapshot rather than a remote master table, you must configure an advanced replication system using updatable snapshots. See Chapter 4, "Using Snapshot Site Replication" for more information.
Caution: Administrators should never modify the structure of a read-only snapshot in any way. For example, never add triggers, integrity constraints, or unique indexes to the base table of a snapshot.
To query a snapshot, a user must own the snapshot, have the SELECT privilege for the snapshot, or have the SELECT ANY TABLE system privilege.
Grant the SELECT privilege for a snapshot to all users who require access to the snapshot. Do not allow users to connect to the snapshot database using the account that owns any snapshots. Otherwise, a malicious user could use the private database link to access the remote master table in any way.
Optionally, you can create views and synonyms based on snapshots. For example, the following statement creates a view based on the EMP snapshot.
CREATE VIEW sales_dept AS
SELECT ename, empno
FROM scott.emp
WHERE deptno = 10;
At the master site, an Oracle database automatically registers information about the snapshots based on the master tables. The following sections explain more about Oracle's snapshot registration mechanism.
You can use the General page of the Snapshot Log property sheet in Schema Manager to list the snapshots associated with a snapshot log. For additional information, you can query the DBA_REGISTERED_SNAPSHOTS data dictionary view to list the following information about a remote snapshot:
You can also join the DBA_REGISTERED_SNAPSHOT view with the DBA_SNAPSHOT_LOGS view at the master site to obtain the last refresh times for each snapshot. Administrators can use this information to monitor snapshot activity from master sites and coordinate changes to snapshot sites if a master table needs to be dropped, altered, or relocated.
Oracle automatically registers a read-only snapshot at its master database when you create the snapshot, and unregisters the snapshot when you drop it.
Note: Oracle7 master sites cannot register snapshots.
Caution: Oracle cannot guarantee the registration or unregistration of a snapshot at its master site during the creation or drop of the snapshot, respectively. If Oracle cannot successfully register a snapshot during creation, Oracle completes snapshot registration during a subsequent refresh of the snapshot. If Oracle cannot successfully unregister a snapshot when you drop the snapshot, the registration information for the snapshot persists in the master database until it is manually unregistered.
If necessary, you can maintain registration manually. Use the REGISTER_SNAPSHOT and UNREGISTER_SNAPSHOT procedures of the DBMS_SNAPSHOT package at the master site to add, modify, or remove snapshot registration information.
Additional Information: The REGISTER_SNAPSHOT and UNREGISTER_SNAPSHOT procedures are described on page 10-175 and page 10-178, respectively.
To alter the storage parameter of a snapshot that is not in a data cluster, you can use Schema Manager or the SQL command ALTER SNAPSHOT.
ALTER SNAPSHOT sales.customers
STORAGE (NEXT 500K);
To alter a snapshot's storage parameters, the snapshot must be contained in your schema. Otherwise, you must have the ALTER ANY SNAPSHOT system privilege.
You can drop a snapshot independently of its master tables or its snapshot log. To drop a local snapshot, use Schema Manager or the SQL command DROP SNAPSHOT.
DROP SNAPSHOT sales.customers;
When you drop the only snapshot of a master table, you should also drop the snapshot log of the master table, if present.
When you drop a master table, Oracle automatically drops the associated snapshot log, if present. Alternatively, all associated snapshots remain and continue to be accessible. However, when Oracle attempts to refresh a snapshot based on a nonexistent master table, Oracle returns an error.
If you later re-create the master table, a dependent snapshot can again successfully complete refresh, as long as Oracle can successfully issue the defining query of the snapshot against the new master table. However, Oracle cannot perform a fast refresh of the snapshot until after you create a snapshot log for the new master table. If Oracle cannot successfully refresh a snapshot after dropping and re-creating its master table, drop and re-create the snapshot as well.
Only the owner of a snapshot or a user with the DROP ANY SNAPSHOT system privilege can drop a snapshot.
When a media failure occurs, it may be necessary to recover either a database that contains a master table of a snapshot or a database with a snapshot. If a master database is independently recovered to a past point in time (that is, coordinated time-based distributed database recovery is not performed), any dependent remote snapshot that refreshed in the interval of lost time will be inconsistent with its master table. In this case, the administrator of the master database should instruct the remote administrator to perform a complete refresh of any inconsistent snapshot.
Additional information: See Oracle8 Server Backup and Recovery Guide to learn about recovering from media failure.
The following sections describe how to manage refresh groups for the snapshots in an Oracle database. Topics include:
After you create a refresh group, you can alter it in several ways. The following sections explain how to add new member snapshots to a refresh group, remove member snapshots from a refresh group, and alter the automatic refresh interval for a refresh group.
To add member snapshots to a refresh group, use the Snapshots page of the Refresh Group property sheet in Schema Manager or call the DBMS_REFRESH.ADD procedure.
DBMS_REFRESH.ADD(
name => 'sales_refgrp_1',
list => 'sales.order_lines'
);
Note: The maximum number of snapshots in a refresh group is 100.
To remove member snapshots from a refresh group, use the Snapshots page of the Refresh Group property sheet in Schema Manager or call the DBMS_REFRESH.SUBTRACT procedure.
DBMS_REFRESH.SUBTRACT(
name => 'sales_refgrp_1',
list => 'sales.assignments'
);
After removing a snapshot from a refresh group, Oracle will not refresh the snapshot unless you add it to another refresh group or refresh it manually.
To change a refresh group's next refresh date or automatic refresh interval, use the General page of the Refresh Group property sheet in Schema Manager or call the DBMS_REFRESH.CHANGE procedure.
DBMS_REFRESH.CHANGE(
name => 'sales_refgrp_1',
next_date => SYSDATE,
interval => 'SYSDATE + 1'
);
To drop a refresh group and implicitly remove all member snapshots from the group, use Schema Manager or call the DBMS_REFRESH.DESTROY procedure.
DBMS_REFRESH.DESTROY( name => 'sales_refgrp_1');
When you drop a refresh group, Oracle will not refresh the former member snapshots unless you add them to another refresh group or refresh them manually.
Refresh groups enable you to configure automatic refresh settings that ease the administration of snapshots in a replication environment. However, some circumstances justify the need to refresh a snapshot manually. For example, immediately following a bulk data load into a master table, dependent snapshots will not represent the master table's data. Rather than wait for the next scheduled automatic group refreshes, you might want to manually refresh dependent snapshot groups to propagate the new rows of the master table immediately to associated snapshots.
To refresh a group of snapshots manually, use the Refresh button of the General page in the Refresh Group property sheet of Schema Manager, or call the DBMS_REFRESH.REFRESH procedure.
DBMS_REFRESH.REFRESH('sales_refgrp_1');
Forcing a manual refresh of a refresh group does not affect the next automatic refresh of the group.
The following sections explain several common snapshot refresh problems.
Several common factors can prevent the automatic refresh of a group of snapshots.
When a snapshot refresh group is experiencing problems, ensure that none of the above situations is preventing Oracle from completing group refreshes.
When Oracle fails to refresh a group automatically, the group remains due for its refresh to complete. Oracle will retry an automatic refresh of a group with the following behavior:
If after sixteen attempts to refresh a refresh group Oracle continues to encounter errors, Oracle considers the group broken. The General page of the Refresh Group property sheet in Schema Manager indicates when a refresh group is broken. You can also query the BROKEN column of the USER_REFRESH and USER_REFRESH_CHILDREN data dictionary views to see the current status of a refresh group.
The errors causing Oracle to consider a snapshot refresh group broken are recorded in a trace file. After you correct the problems preventing a refresh group from refreshing successfully, you must refresh the group manually. Oracle then resets the broken flag so that automatic refreshes can happen again.
Additional Information: The name of the snapshot trace file is of the form SNPn, where n is platform specific. See your platform-specific Oracle documentation for the name on your system.
If you encounter a situation where Oracle continually refreshes a group of snapshots, check the group's refresh interval. Oracle evaluates a group's automatic refresh interval before starting the refresh. If a group's refresh interval is less than the amount of time it takes to refresh all snapshots in the group, Oracle continually starts a group refresh each time the SNP background process checks the queue of outstanding jobs.
If a snapshot log is growing without bounds, check to see whether a network or site failure has prevented a master from becoming aware that a snapshot has been dropped. You may need to purge part of the log as described in "Purging Rows from a Snapshot Log" on page 2-29 and unregister the snapshot.
The following sections explain how you can tune the performance of snapshots.
To maximize the query performance of applications that use a snapshot, you can create indexes for the snapshot. To index a column (or columns) of a snapshot, create an index on the underlying base table of the snapshot.
Caution: Do not declare non-deferrable UNIQUE constraints for a snapshot.
On the master site, both sides of the equi-joins used by a simple snapshot with a subquery should have indexes to improve the efficiency of queries against the master tables during a fast refresh. A subquery could be written that efficiently executes without both tables involved in the equi-join having an index; however, the fast refresh algorithms used by a simple snapshot with a subquery transform the subquery into multiple new queries that may reverse the correlation used by the subquery. For simple snapshots with a subquery, unique indexes are guaranteed to be at the parent side, but not at the child side.
If you use the cost-based optimizer, be sure to analyze the master table, snapshot base table, snapshot log (at the master), and the updatable snapshot log (at the snapshot site, if updatable).
Recommendation: In general, it is best to analyze the snapshot logs when they are empty or nearly empty.
A variable number of indexes are automatically added on the underlying snapshot tables used by simple snapshot with a subquery. These indexes prevent full-table scans during refresh when a change to a row in a master table affects that snapshot's partitioning criteria.
See "Example 2: A Better Approach" on page 2-19. Using the example ORDER_LINES snapshot, the SNAP$_ORDER_LINE table would have a nonunique index on each of the following columns: C_ID, O_ID, and OL_ID.
Note: Frequent modification of columns used by snapshots with restricted subqueries to perform equi-joins or filtering can cause performance degradation during refresh.
Oracle supports some additional basic replication features that can be useful in certain situations.
When the defining query of a snapshot contains a distinct or aggregate function, a GROUP BY or CONNECT BY clause, join, restricted types of subqueries, or a set operation, the snapshot is a complex snapshot.
Note: In most cases, you should avoid using complex snapshots, because Oracle cannot perform a fast refresh of a complex snapshot. Consequently, the use of complex snapshots can degrade network performance during complete snapshot refreshes.
For certain applications, you might want to consider the use of a complex snapshot. Figure 3-1 and the following sections summarize some issues to consider.
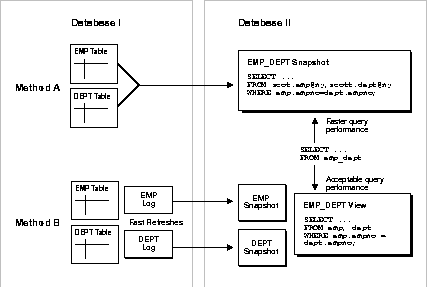
Method A shows a complex snapshot. The snapshot in Database II exhibits efficient query performance because the join operation has already been completed during the snapshot's refresh. However, complete refreshes must be performed, because it is a complex snapshot.
Method B shows two simple snapshots in Database II, as well as a view that performs the join in the snapshots' database. Query performance against the view would not be as good as the query performance against the complex snapshot in Method A. However, the simple snapshots can be more efficiently refreshed using snapshot logs.
In summary, to decide which method to use:
Because a complex snapshot is always completely refreshed, set its PCTFREE to 0 and PCTUSED to 100 for maximum efficiency.
For backward compatibility, Oracle supports ROWID snapshots in addition to the default, primary key snapshots. Oracle bases a ROWID snapshot on the physical row identifiers (ROWIDs) of rows in the master table. ROWID snapshots should be used only for snapshots of master tables in an Oracle7 database, and should not be used when creating new snapshots of master tables in Oracle databases.
To explicitly create a ROWID snapshot for an Oracle7 Release 7.3 master table, you must use a CREATE SNAPSHOT statement with the WITH ROWID clause.
CREATE SNAPSHOT ...
WITH ROWID
AS ...
To support fast refreshes of ROWID snapshots, you must create a snapshot log of a master table with a CREATE SNAPSHOT LOG statement that includes the WITH ROWID clause.
All ROWID snapshots of a master table require a full refresh after you reorganize the table. Subsequently, Oracle can fast refresh all ROWID snapshots.
In typical environments, all snapshots are refreshed as part of a refresh group. However, certain environments do not have concern for referential integrity among snapshots, and require or prefer that snapshots be refreshed individually. For example, you might want to refresh certain snapshots more frequently than others.
To configure a snapshot for individual refreshes, create a refresh group for only the single snapshot. Oracle automatically creates a refresh group for an individual snapshot when you:
The Schema Manager component of Enterprise Manager allows you to view the properties of snapshot logs, snapshots, and refresh groups quickly in a basic replication environment. Alternatively, you can query a database's data dictionary to view information about snapshot logs, snapshots, and refresh groups. The following data dictionary views provide information about the components of a basic replication environment:
Note: Most data dictionary views have three versions, which have different prefixes: USER_*, ALL_*, and SYS.DBA_*.