Release 8.0
A54651-01
Library |
Product |
Contents |
Index |
| Oracle8(TM) Server Replication Release 8.0 A54651-01 |
|
![]()
![]()
This chapter explains the basic concepts and terminology related to the Oracle replication features.
Note: If you are using Trusted Oracle, see the Trusted Oracle documentation for information about using replication in that environment.
Replication is the process of copying and maintaining database objects in multiple databases that make up a distributed database system. Replication can improve the performance and protect the availability of applications because alternate data access options exist. For example, an application might normally access a local database rather than a remote server to minimize network traffic and achieve maximum performance. Furthermore, the application can continue to function if the local server experiences a failure, but other servers with replicated data remain accessible. Oracle Server supports two different forms of replication: basic and advanced replication.
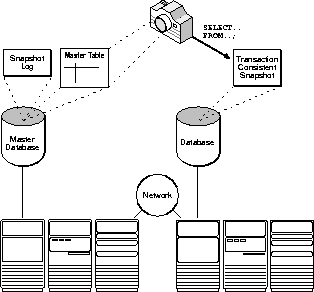
With basic replication, data replicas provide read-only access to the table data that originates from a primary (master) site. Applications can query data from local data replicas to avoid network access regardless of network availability. However, applications throughout the system must access data at the primary site when updates are necessary. Figure 1-1 illustrates basic replication.
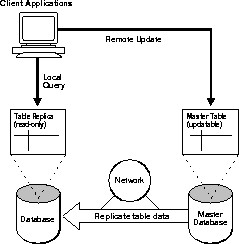
Oracle Server can support basic, read-only replication environments using read-only table snapshots. To learn more about basic replication and read-only snapshots, read "Basic Replication Concepts" on page 1-4.
The Oracle advanced replication features extend the capabilities of basic read-only replication by allowing applications to update table replicas throughout a replicated database system. With advanced replication, data replicas anywhere in the system can provide both read and update access to a table's data. Participating Oracle database servers automatically work to converge the data of all table replicas, and ensure global transaction consistency and data integrity. Figure 1-2 illustrates advanced replication.
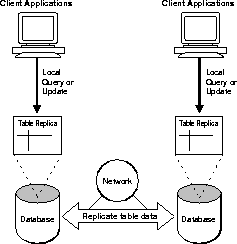
Oracle Server can support the requirements of advanced replication environments using several configurations. To learn more about advanced replication systems, read "Advanced Replication Concepts" on page 1-12.
Basic replication environments support applications that require read-only access to the table data that originates from a primary site. The following sections explain the fundamental concepts of basic replication environments.
Basic, read-only data replication is useful for several types of applications.
Basic replication is useful for information distribution. For example, consider the operation of a large consumer department store chain. With this type of business, it is critical to ensure that product price information is always available, relatively current, and consistent at all retail outlets. To achieve these goals, each retail store can have its own product price data that it refreshes nightly from a primary price table at corporate headquarters.
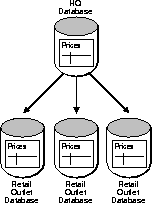
Basic replication is useful as a way to replicate entire databases or off-load information. For example, when the performance of high-volume transaction processing system is critical, it can be advantageous to maintain a duplicate database to isolate the demanding queries of decision support applications.
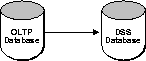
Basic replication can be useful as an information transport mechanism. For example, basic replication can periodically move data from a production transaction processing database to a data warehouse.
A read-only table snapshot is a local copy of table data that originates from one or more remote master tables. An application can query the data in a read-only table snapshot, but cannot insert, update, or delete rows in the snapshot. Figure 1-5 and the sections that follow explain more about read-only table snapshots and basic replication.
Oracle supports basic data replication with its table snapshot mechanism. The following sections explain the architecture of simple read-only table snapshots.
Note: Oracle offers other basic replication features such as complex snapshots and ROWID snapshots for unique application requirements. To learn more about these special configurations, read "Other Basic Replication Options" on page 1-10.
The logical data structure of a table snapshot is defined by a query that references data in one or more remote master tables. A snapshot's defining query determines what data the snapshot will contain.
A snapshot's defining query should be such that each row in the snapshot corresponds directly to a row or a part of a row in a single master table. Specifically, the defining query of a snapshot should not contain a distinct or aggregate function, a GROUP BY or CONNECT BY clause, join, restricted types of subqueries, or a set operation. The following example shows a simple table snapshot definition.
CREATE SNAPSHOT sales.customers AS
SELECT * FROM sales.customers@hq.acme.com
Note: In all cases, the defining query of the snapshot must reference all of the primary key columns in the master table.
A snapshot's defining query can include restricted types of subqueries that reference multiple tables to filter rows from the snapshot's master table. A subquery snapshot can be used to create snapshots that "walk up" the many-to-one references from child to parent tables that may involve multiple levels. The following example creates a simple subquery snapshot.
CREATE SNAPSHOT sales.orders AS
SELECT * FROM sales.orders@hq.acme.com o
WHERE EXISTS
( SELECT c_id FROM sales.customers@hq.acme.com c
WHERE o.c_id = c.c_id AND zip = 19555);
When you create a new read-only table snapshot, Oracle creates several underlying database objects to support the snapshot.
The data that a snapshot presents does not necessarily match the current data of its master tables. A table snapshot is a transaction-consistent reflection of its master data as that data existed at a specific point in time. To keep a snapshot's data relatively current with the data of its master, Oracle must periodically refresh the snapshot. A snapshot refresh is an efficient batch operation that makes that snapshot reflect a more current state of its master.
You must decide how and when it is appropriate to refresh each snapshot to make it a more current representation of its master data. For example, snapshots stemming from master tables that applications often update usually require frequent refreshes. In contrast, snapshots that depend on relatively static master tables usually require infrequent refreshes. In summary, analyze application characteristics and requirements to help determine appropriate snapshot refresh intervals.
To refresh snapshots, Oracle supports different types of refreshes (complete and fast), snapshot refresh groups, and manual and automatic refreshes.
Oracle can refresh an individual snapshot using either a complete refresh or a fast refresh.
To perform a complete refresh of a snapshot, the server that manages the snapshot executes the snapshot's defining query. The result set of the query replaces the existing snapshot data to refresh the snapshot. Oracle can perform a complete refresh for any snapshot.
To perform a fast refresh, the server that manages the snapshot first identifies the changes that took place in the master since the most recent refresh of the snapshot and then applies them to the snapshot. Fast refreshes are more efficient than complete refreshes when there are few changes to the master because participating servers and networks must replicate less data. Fast refreshes are available for snapshots only when the master table has a snapshot log.
When a master table corresponds to one or more snapshots, create a snapshot log for the table so that fast refreshes of the snapshots are an option. A master table's snapshot log keeps track of fast refresh data for all corresponding snapshots-only one snapshot log is possible per master table. When a server performs a fast refresh for a snapshot, it uses the data in its master table's snapshot log to refresh the snapshot efficiently. Oracle automatically purges specific refresh data from a snapshot log after all snapshots perform refreshes such that the log data is no longer needed.
When you create a snapshot log for a master table, Oracle creates an underlying table to support the snapshot log. A snapshot log's table holds the primary keys, timestamps, and optionally the ROWIDs of rows that applications update in the master table. A snapshot log can also contain filter columns to support fast refreshes for snapshots with subqueries. The name of a snapshot log's table is MLOG$_mastertablename.
To preserve referential integrity and transaction consistency among the table snapshots of several related master tables, Oracle organizes and refreshes each snapshot as part of a refresh group. Oracle refreshes all snapshots in a group as a single operation. After refreshing all of the snapshots in a refresh group, the data of all snapshots in the group corresponds to the same transaction consistent point in time.
When creating a snapshot refresh group, administrators usually configure the group so that Oracle automatically refreshes its snapshots. Otherwise, administrators would have to manually refresh the group whenever necessary.
When configuring a refresh group for automatic refreshes, it is necessary to
When you create a snapshot refresh group, you can specify an automatic refresh interval for the group. When setting a group's refresh interval, understand the following behaviors:
By default, Oracle attempts to perform a fast refresh of each snapshot in a refresh group. If, for some reason, Oracle cannot perform a fast refresh for an individual snapshot (for example, when a master table has no snapshot log), the server performs a complete refresh for the snapshot.
Oracle Server's automatic snapshot refresh facility functions by using job queues to schedule the periodic execution internal system procedures. Job queues require that at least one SNP background process be running. A SNP background process wakes up periodically, checks the job queue, and executes any outstanding jobs.
Scheduled, automatic snapshot refreshes may not always be adequate. For example, immediately following a bulk data load into a master table, dependent snapshots will no longer represent the master table's data. Rather than wait for the next scheduled automatic group refreshes, you might want to manually refresh dependent snapshot groups to immediately propagate the new rows of the master table to associated snapshots.
Oracle supports some additional basic replication features that can be useful in certain situations:
When the defining query of a snapshot contains a distinct or aggregate function, a GROUP BY or CONNECT BY clause, join, restricted types of subqueries, or a set operation, the snapshot is a complex snapshot. The following example is a complex table snapshot definition.
CREATE SNAPSHOT scott.emp AS
SELECT ename, dname
FROM scott.emp@hq.acme.com a, scott.dept@hq.acme.com b
WHERE a.deptno = b.deptno
SORT BY dname
The primary disadvantage of a complex snapshot is that Oracle cannot perform a fast refresh of the snapshot-Oracle can perform only complete refreshes of a complex snapshot. Consequently, the use of complex snapshots can affect network performance during complete snapshot refreshes.
Primary key snapshots (discussed implicitly in earlier sections of this chapter) are the default for Oracle. Oracle bases a primary key snapshot on the primary key of its master table. Because of this structure, you can:
For backward compatibility only, Oracle also supports ROWID snapshots based on the physical row identifiers (ROWIDs) of rows in the master table. ROWID snapshots should only be used for snapshots of master tables in an Oracle7.3 database, and should not be used when creating new snapshots of master tables in Oracle8 databases.
Note: To support a ROWID snapshot, Oracle creates an additional index on the snapshot's base table with the name I_SNAP$_snapshotname.
In advanced replication environments, data replicas anywhere in the system can provide both read and update access to a table's data. The following sections explain the principal concepts of an advanced replication system.
Advanced, symmetric data replication is useful for many types of application systems with special requirements.
Advanced replication is useful for the deployment of transaction processing applications that operate using disconnected components. For example, consider the typical sales force automation system for a life insurance company. Each salesperson must visit customers regularly with a laptop computer and record orders in a personal database while disconnected from the corporate computer network and centralized database system. Upon returning to the office, each salesperson must forward all orders to a centralized, corporate database.
Advanced replication can be useful to protect the availability of a mission critical database. For example, an advanced replication system can replicate an entire database to establish a failover site should the primary site become unavailable due to a system or network outage. In contrast with Oracle's standby database feature, such a failover site can also serve as a fully functional database to support application access when the primary site is concurrently operational.
Advanced replication is useful for transaction processing applications that require multiple points of access to database information for the purposes of distributing a heavy application load, ensuring continuous availability, or providing more localized data access. Applications that have such requirements commonly include customer service oriented applications.
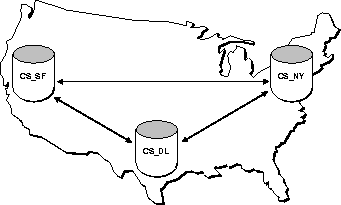
Advanced replication can be useful as an information transport mechanism. For example, an advanced replication system can periodically off-load data from an update-intensive operational database to a data warehouse or data mart.
Oracle supports the requirements of advanced replication environments using multimaster replication as well as snapshot sites.
Oracle's multimaster replication allows multiple sites, acting as equal peers, to manage groups of replicated database objects. Applications can update any replicated table at any site in a multimaster configuration. Figure 1-7 illustrates a multimaster advanced replication system.
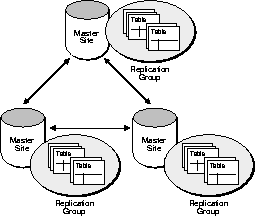
Master sites in an advanced replication system can consolidate the information that applications update at remote snapshot sites. Oracle's advanced replication facility allows applications to insert, update, and delete table rows through updatable snapshots. Figure 1-8 illustrates an advanced replication environment with updatable snapshots.
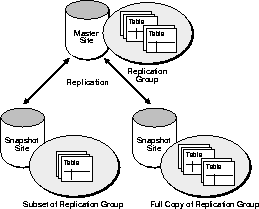
Updatable snapshots have the following properties.
Multimaster replication and updatable snapshots can be combined in hybrid (mixed) configurations to meet different application requirements. Mixed configurations can have any number of master sites and multiple snapshot sites for each master.
For example, as shown in Figure 1-9, n-way replication between two masters can support full-table replication between the databases that support two geographic regions. Snapshots can be defined on the masters to replicate full tables or table subsets to sites within each region.
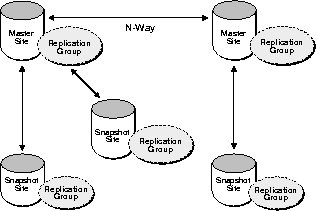
Some of the key differences between updatable snapshots and replicated masters include the following:
Advanced replication environments that support an update-anywhere data model can be challenging to configure and manage. To help administer advanced replication environments, Oracle provides a sophisticated management tool, Oracle Replication Manager. The other sections in this book include information and examples for using Replication Manager.
The following sections explain the basic components of an advanced replication system, including replication objects, groups, sites, and catalogs.
A replication object is a database object that exists on multiple servers in a distributed database system. Oracle's advanced replication facility enables you to replicate tables and supporting objects such as views, database triggers, packages, indexes, and synonyms.
In an advanced replication environment, Oracle manages replication objects using replication groups. By organizing related database objects within a replication group, it is easier to administer many objects together. Typically, you create and use a replication group to organize the schema objects necessary to support a particular database application. That is not to say that replication groups and schemas must correspond with one another-the objects in a replication group can originate from several database schemas, and a schema can contain objects that are members of different replication groups. The basic restriction is that a replication object can be a member of only one group.
A replication group can exist at multiple replication sites. Advanced replication environments support two basic types of sites: master sites and snapshot sites.
Every master and snapshot site in an advanced replication environment has a replication catalog. A site's replication catalog is a distinct set of data dictionary tables and views that maintain administrative information about replication objects and replication groups at the site. Every server that participates in an advanced replication environment can automate the replication of objects in replication groups using the information in its replication catalog.
To configure and manage an advanced replication environment, each participating server uses Oracle's replication application programming interface (API). A server's replication management API is a set of PL/SQL packages that encapsulate procedures and functions that administrators can use to configure Oracle's advanced replication features. Oracle Replication Manager also uses the procedures and functions of each site's replication management API to perform work.
An administration request is a call to a procedure or function in Oracle's replication management API. For example, when you use Replication Manager to create a new master group, Replication Manager completes the task by making a call to the DBMS_REPCAT.CREATE_MASTER_REPGROUP procedure. Some administration requests generate additional replication management API calls to complete the request.
Oracle converges the data of typical advanced replication configurations using row-level replication with asynchronous data propagation. The following sections explain how these mechanisms function.
Note: Oracle offers other advanced replication features such as procedural replication and synchronous data propagation for unique application requirements. To learn more about these special configurations, read "Unique Advanced Replication Options" on page 1-27.
Typical transaction processing applications modify small numbers of rows per transaction. Such applications at work in an advanced replication environment will usually depend on Oracle's row-level replication mechanism. With row-level replication, applications use standard DML statements to modify the data of local data replicas. When transactions change local data, the server automatically captures information about the modifications and queues corresponding deferred transactions to forward local changes to remote sites.
To support the replication of transactions in an advanced replication environment, you must generate one or more internal system objects to support each replicated table, package, or procedure.
Note: With previous versions of Oracle, the server also generates PL/SQL triggers to support a replicated table. However, Oracle now "activates" internal triggers when you choose to replicate a table.
Typical advanced replication configurations that rely on row-level replication propagate data level changes using asynchronous data replication. Asynchronous data replication occurs when an application updates a local replica of a table, stores replication information in a local queue, and then forwards the replication information to other replication sites at a later time. Consequently, asynchronous data replication is also called store-and-forward data replication.
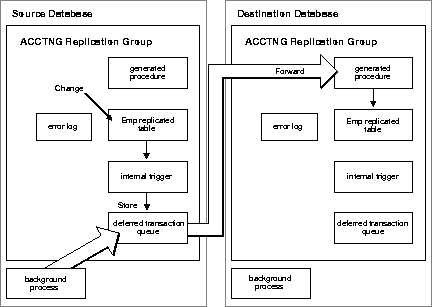
As Figure 1-10 shows, Oracle uses its internal system of triggers, deferred transactions, deferred transaction queues, and job queues to propagate data-level changes asynchronously among master sites in an advanced replication system, as well as from an updatable snapshot to its master table.
With serial propagation, Oracle asynchronously propagates replicated transactions, one at a time, in the same order of commit as on the originating site.
With parallel propagation, Oracle asynchronously propagates replicated transactions using multiple, parallel transit streams for higher throughput. When necessary, Oracle orders the execution of dependent transactions to ensure global database integrity.
Parallel propagation uses the same execution mechanism that Oracle uses for parallel query, load, recovery, and other parallel operations. Each server process propagates transactions through a single stream. A parallel coordinator process controls these server processes. The coordinator tracks transaction dependencies, allocates work to the server processes, and tracks their progress.
After a site pushes a deferred transaction to its destination, the transaction remains in the deferred transaction queue until another job purges the applied transaction from the queue.
Updatable snapshots in an advanced replication environment can both "push" and "pull" data to and from its master table, respectively.
Updates to an updatable snapshot are asynchronously pushed to its master table using Oracle's row-level, asynchronous data propagation mechanisms (RPCs, deferred transactions, and job queues).
Identical to basic replication environments, advanced replication systems use Oracle's snapshot refresh mechanism to pull changes asynchronously from a master table to associated updatable (and read-only) snapshots.
An updatable snapshot's push and pull tasks are independent operations that you can configure associatively or separately.
For example, an advanced replication environment that consolidates information at a master site might configure updatable snapshots to push changes to the master site every hour but refresh updatable snapshots infrequently, if ever.
An Oracle advanced replication environment requires several unique database user accounts to function properly, including replication administrators, propagators, and receivers.
In most advanced replication configurations, just one account is used for all purposes-as a replication administrator, a replication propagator, and a replication receiver. However, Oracle also supports distinct accounts for unique configurations.
Advanced replication systems that support an update-anywhere model of data replicas must address the possibility of replication conflicts. The following sections explain the different types of replication conflicts, when they can occur, and how Oracle can detect and resolve replication conflicts.
Three types of conflicts can occur in an advanced replication environment: uniqueness conflicts, update conflicts, and delete conflicts.
A uniqueness conflict happens when the replication of a row attempts to violate entity integrity (a PRIMARY KEY or UNIQUE constraint). For example, consider what happens when two transactions that originate from two different sites each insert a row into a respective table replica with the same primary key value-replication of the transactions will cause a uniqueness conflict.
An update conflict happens when the replication of an update to a row conflicts with another update to the same row. Update conflicts can happen when two different transactions, originating from different sites, update the same row at nearly the same time.
A delete conflict happens when two transactions originate from different sites, with one transaction deleting a row that the other transaction updates or deletes.
When designing applications that will work on top of a database system that uses advanced replication, you must consider the possibility of replication conflicts. In doing so, applications must choose to employ one of several different replicated data ownership models that will ensure global database integrity by avoiding or resolving replication conflicts.
Primary ownership, also called static ownership, is the replicated data model that basic read-only replication environments support. Primary ownership prevents all replication conflicts, because only a single server permits update access to a set of replicated data.
Rather than control the ownership of data at the table level, applications can employ horizontal and vertical partitioning to establish more granular static ownership of data. For example, applications might have update access to specific columns or rows in a replicated table on a site-by-site basis.
The dynamic ownership replicated data model is less restrictive than primary site ownership. With dynamic ownership, the capability to update a data replica moves from site to site, still ensuring that only one site provides update access to specific data at any given point in time. A workflow system clearly illustrates the concept of a dynamic ownership. For example, related departmental applications can read the status code of a product order to determine when they can and cannot update the order. Figure 1-11 illustrates an application that uses a dynamic ownership model.

Primary site ownership and dynamic ownership replication data models, which promote conflict avoidance, are often too restrictive or impossible to implement for some database applications. Some applications must operate using a shared ownership replicated data model in which applications can update the data of any table replica at any time.
When a shared data ownership system replicates changes asynchronously (store-and-forward replication), corresponding applications must be sure to avoid, or detect and resolve replication conflicts if and when they occur. For example:
When an application uses a shared ownership data model with asynchronous row-level replication, Oracle automatically detects uniqueness, update, and delete conflicts. To detect conflicts during replication, Oracle compares a minimal amount of row data from the originating site with the corresponding row information at the receiving site. When there are differences, Oracle detects the conflict.
To detect replication conflicts accurately, Oracle must be able to uniquely identify and match corresponding rows at different sites during data replication. Typically, Oracle's advanced replication facility uses the primary key of a table to uniquely identify rows in the table. When a table does not have a primary key, you must designate an alternate key-a column or set of columns that Oracle can use to identify rows in the table during data replication. In either case, applications should not be allowed to update the identity columns of a table to ensure that Oracle can identify rows and preserve the integrity of replicated data.
When a receiving site in an advanced replication system is using asynchronous row-level replication and it detects a conflict in a transaction, the default behavior is to log the conflict and the entire transaction, and leave the local version of the data intact. In most cases, you should use Oracle's advanced replication facility to automate the resolution of replication conflicts. You can also check each server's DEFERROR data dictionary view for transactions that caused conflicts, and resolve them manually, if necessary.
Oracle uses column groups to detect and resolve conflicts during asynchronous, row-level advanced replication. A column group is a logical grouping of one or more columns in a table. Every column in a replicated table is part of a single column group. When configuring replicated tables, you can create column groups and then assign columns and corresponding conflict resolution methods to each group.
Each column group in a replicated table can have a list of one or more conflict resolution methods. Indicating multiple conflict resolution methods for a group allows Oracle to resolve a conflict in different ways should others fail to resolve the conflict. When trying to resolve a conflict for a group, Oracle executes the group's resolution methods in the order that you list for the group.
By default, every replicated table has a shadow column group. A table's shadow column group contains all columns that are not within a specific column group. You cannot assign conflict resolution methods to a table's shadow group.
When designing column groups you can choose from among many built-in conflict resolution methods. For example, to resolve update conflicts, you might choose to have Oracle overwrite the column values at the destination site with the column values from the originating site. Oracle offers many other update conflict resolution methods.
However, Oracle offers no delete conflict resolution methods. Consequently, applications that operate within an asynchronous, shared ownership data model should avoid delete conflicts by not using DELETE statements to delete rows. Instead, applications can mark rows for deletion and configure the system to periodically purge deleted rows using procedural replication.
Some applications have special requirements of an advanced replication system. The following sections explain the Oracle unique advanced replication options, including
Batch processing applications can change large amounts of data within a single transaction. In such cases, typical row-level replication could saturate a network with a huge quantity of data changes. To avoid such problems, a batch processing application that operates in an advanced replication environment can use Oracle's procedural replication to replicate simple stored procedure calls that will converge data replicas. Procedural replication replicates only the call to a stored procedure that an application uses to update a table. Procedural replication does not replicate data modifications.
To use procedural replication, at all sites you must replicate the packages that modify data in the system. After replicating a package, you must generate a wrapper for this package at each site. When an application calls a packaged procedure at the local site to modify data, the wrapper ensures that the call is ultimately made to the same packaged procedure at all other sites in the replicated environment. Procedural replication can occur asynchronously or synchronously.
When an advanced replication system replicates data using procedural replication, the procedures that replicate data are responsible for ensuring the integrity of the replicated data. That is, you must design such procedures either to avoid or to detect replication conflicts and resolve them appropriately. Consequently, procedural replication is most typically used when databases are available only for the processing of large batch operations. In such situations, replication conflicts are unlikely because numerous transactions are not contending for the same data.
Additional Information: See "Using Procedural Replication" on page 7-2.
Asynchronous data propagation is the normal configuration for advanced replication environments. However, Oracle also supports synchronous data propagation for applications with special requirements. Synchronous data propagation occurs when an application updates a local replica of a table, and within the same transaction also updates all other replicas of the same table. Consequently, synchronous data replication is also called real-time data replication. Use synchronous replication only when applications require that replicated sites remain continuously synchronized.
Note: A replication system that uses real-time propagation of replication data is highly dependent on system and network availability because it can function only when all sites in the system are concurrently available.
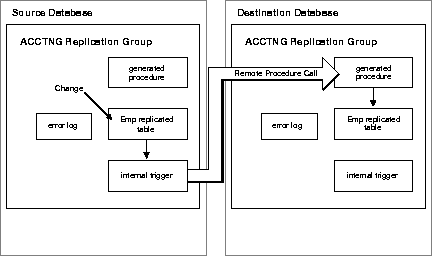
As Figure 1-12 shows, Oracle uses the same system of internal database triggers to generate RPCs that replicate data-level changes to other replication sites to support synchronous, row-level data replication. However, Oracle does not defer the execution of such RPCs. Instead, data replication RPCs execute within the boundary of the same transaction that modifies the local replica. Consequently, a data-level change must be possible at all sites that manage a replicated table or else a transaction rollback occurs.
You can choose to create a replicated environment in which some sites propagate changes synchronously while others use asynchronous propagation (deferred transactions).
When a shared ownership system replicates all changes synchronously (real-time replication), replication conflicts are not possible. With real-time replication, applications use distributed transactions to update all replicas of a table at the same time. As is the case in nondistributed database environments, Oracle automatically locks rows on behalf of each distributed transaction to prevent all types of destructive interference among transactions. While a real-time replication system can prevent replication conflicts, this type of system is highly dependent on system and network availability because it can function only when all sites in the system are available.