Release 8.1.5
A67842-01
Library |
Product |
Contents |
Index |
| PL/SQL User's Guide and Reference Release 8.1.5 A67842-01 |
|
![]()
![]()
Knowledge is that area of ignorance that we arrange and classify. --Ambrose Bierce
Increasingly, programmers are using collection types such as arrays, bags, lists, nested tables, sets, and trees in traditional database applications. To meet the growing demand, PL/SQL provides the datatypes TABLE and VARRAY, which allow you to declare index-by tables, nested tables and variable-size arrays. In this chapter, you learn how those types let you reference and manipulate collections of data as whole objects. You also learn how the datatype RECORD lets you treat related but dissimilar data as a logical unit.
A collection is an ordered group of elements, all of the same type (for example, the grades for a class of students). Each element has a unique subscript that determines its position in the collection. PL/SQL offers two collection types. Items of type TABLE are either index-by tables (Version 2 PL/SQL tables) or nested tables (which extend the functionality of index-by tables). Items of type VARRAY are varrays (short for variable-size arrays).
Collections work like the arrays found in most third-generation programming languages. However, collections can have only one dimension and must be indexed by integers. (In some languages such as Ada and Pascal, arrays can have multiple dimensions and can be indexed by enumeration types.)
Collections can store instances of an object type and, conversely, can be attributes of an object type. Also, collections can be passed as parameters. So, you can use them to move columns of data into and out of database tables or between client-side applications and stored subprograms. Furthermore, you can define collection types in a PL/SQL package, then use them programmatically in your applications.
Within the database, nested tables can be considered one-column database tables. Oracle stores the rows of a nested table in no particular order. But, when you retrieve the nested table into a PL/SQL variable, the rows are given consecutive subscripts starting at 1. That gives you array-like access to individual rows.
Within PL/SQL, nested tables are like one-dimensional arrays. However, nested tables differ from arrays in two important ways. First, arrays have a fixed upper bound, but nested tables are unbounded (see Figure 4-1). So, the size of a nested table can increase dynamically.
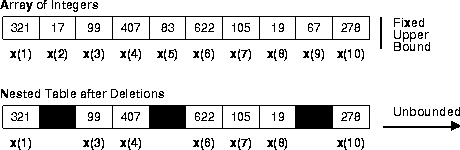
Second, arrays must be dense (have consecutive subscripts). So, you cannot delete individual elements from an array. Initially, nested tables are dense, but they can be sparse (have nonconsecutive subscripts). So, you can delete elements from a nested table using the built-in procedure DELETE. That might leave gaps in the index, but the built-in function NEXT lets you iterate over any series of subscripts.
Index-by tables and nested tables are similar. For example, they have the same structure, and their individual elements are accessed in the same way (using subscript notation). The main difference is that nested tables can be stored in a database column (hence the term "nested table") but index-by tables cannot.
Nested tables extend the functionality of index-by tables by letting you SELECT, INSERT, UPDATE, and DELETE nested tables stored in the database. (Remember, index-by tables cannot be stored in the database.) Also, some collection methods operate only on nested tables and varrays. For example, the built-in procedure TRIM cannot be applied to index-by tables.
Another advantage of nested tables is that an uninitialized nested table is atomically null (that is, the table itself is null, not its elements), but an uninitialized index-by table is merely empty. So, you can apply the IS NULL comparison operator to nested tables but not to index-by tables.
However, index-by tables also have some advantages. For example, PL/SQL supports implicit (automatic) datatype conversion between host arrays and index-by tables (but not nested tables). So, the most efficient way to pass collections to and from the database server is to use anonymous PL/SQL blocks to bulk-bind input and output host arrays to index-by tables.
Also, index-by tables are initially sparse. So, they are convenient for storing reference data using a numeric primary key (account numbers or employee numbers for example) as the index.
In some (relatively minor) ways, index-by tables are more flexible than nested tables. For example, subscripts for a nested table are unconstrained. In fact, index-by tables can have negative subscripts (nested tables cannot). Also, some element types are allowed for index-by tables but not for nested tables (see "Referencing Collection Elements"). Finally, to extend a nested table, you must use the built-in procedure EXTEND, but to extend an index-by table, you just specify larger subscripts.
Items of type VARRAY are called varrays. They allow you to associate a single identifier with an entire collection. This association lets you manipulate the collection as a whole and reference individual elements easily. To reference an element, you use standard subscripting syntax (see Figure 4-2). For example, Grade(3) references the third element in varray Grades.

A varray has a maximum size, which you must specify in its type definition. Its index has a fixed lower bound of 1 and an extensible upper bound. For example, the current upper bound for varray Grades is 7, but you can extend it to 8, 9, or 10. Thus, a varray can contain a varying number of elements, from zero (when empty) to the maximum specified in its type definition.
Nested tables differ from varrays in the following ways:
Which collection type should you use? That depends on your wants and the size of the collection. A varray is stored as an opaque object, whereas a nested table is stored in a storage table with every element mapped to a row in the table. So, if you want efficient queries, use nested tables. If you want to retrieve entire collections as a whole, use varrays. However, when collections get very large, it becomes impractical to retrieve more than subsets. So, varrays are better suited for small collections.
To create collections, you define a collection type, then declare collections of that type. You can define TABLE and VARRAY types in the declarative part of any PL/SQL block, subprogram, or package. For nested tables, use the syntax
TYPE type_name IS TABLE OF element_type [NOT NULL];
and for varrays, use the following syntax:
TYPE type_name IS {VARRAY | VARYING ARRAY} (size_limit) OF element_type [NOT NULL];
where type_name is a type specifier used later to declare collections, size_limit is a positive integer literal, and element_type is any PL/SQL datatype except
BINARY_INTEGER, PLS_INTEGER
BOOLEAN
BLOB, CLOB (restriction applies only to varrays)
LONG, LONG RAW
NATURAL, NATURALN
NCHAR, NCLOB, NVARCHAR2
BLOB or CLOB attributes (restriction applies only to varrays)
TABLE or VARRAY attributes
POSITIVE, POSITIVEN
REF CURSOR
SIGNTYPE
STRING
TABLE
VARRAY
If element_type is a record type, every field in the record must be a scalar type or an object type.
For index-by tables, use the syntax
TYPE type_name IS TABLE OF element_type [NOT NULL] INDEX BY BINARY_INTEGER;
Unlike nested tables and varrays, index-by tables can have the following element types: BINARY_INTEGER, BOOLEAN, LONG, LONG RAW, NATURAL, NATURALN, PLS_INTEGER, POSITIVE, POSITIVEN, SIGNTYPE, and STRING. That is because nested tables and varrays are intended mainly for database columns. As such, they cannot use PL/SQL-specific types. When declared locally, they could theoretically use those types, but the restriction is preserved for consistency.
Index-by tables are initially sparse. That enables you, for example, to store reference data in a temporary index-by table using a numeric primary key as the index. In the example below, you declare an index-by table of records. Each element of the table stores a row from the emp database table.
DECLARE TYPE EmpTabTyp IS TABLE OF emp%ROWTYPE INDEX BY BINARY_INTEGER; emp_tab EmpTabTyp; BEGIN /* Retrieve employee record. */ SELECT * INTO emp_tab(7468) FROM emp WHERE empno = 7788;
When defining a VARRAY type, you must specify its maximum size. In the following example, you define a type that stores up to 366 dates:
DECLARE TYPE Calendar IS VARRAY(366) OF DATE;
To specify the element type, you can use %TYPE, which provides the datatype of a variable or database column. Also, you can use %ROWTYPE, which provides the rowtype of a cursor or database table. Two examples follow:
DECLARE TYPE EmpList IS TABLE OF emp.ename%TYPE; -- based on column CURSOR c1 IS SELECT * FROM dept; TYPE DeptFile IS VARRAY(20) OF c1%ROWTYPE; -- based on cursor
In the next example, you use a RECORD type to specify the element type:
DECLARE TYPE AnEntry IS RECORD ( term VARCHAR2(20), meaning VARCHAR2(200)); TYPE Glossary IS VARRAY(250) OF AnEntry;
In the final example, you impose a NOT NULL constraint on the element type:
DECLARE TYPE EmpList IS TABLE OF emp.empno%TYPE NOT NULL;
An initialization clause is not required (or allowed).
Once you define a collection type, you can declare collections of that type, as the following SQL*Plus script shows:
CREATE TYPE CourseList AS TABLE OF VARCHAR2(10) -- define type / CREATE TYPE Student AS OBJECT ( -- create object id_num INTEGER(4), name VARCHAR2(25), address VARCHAR2(35), status CHAR(2), courses CourseList) -- declare nested table as attribute /
The identifier courses represents an entire nested table. Each element of courses will store the code name of a college course such as 'Math 1020'.
The script below creates a database column that stores varrays. Each element of the varrays will store a Project object.
CREATE TYPE Project AS OBJECT( --create object project_no NUMBER(2), title VARCHAR2(35), cost NUMBER(7,2)) / CREATE TYPE ProjectList AS VARRAY(50) OF Project -- define VARRAY type / CREATE TABLE department ( -- create database table dept_id NUMBER(2), name VARCHAR2(15), budget NUMBER(11,2), projects ProjectList) -- declare varray as column /
The following example shows that you can use %TYPE to provide the datatype of a previously declared collection:
DECLARE TYPE Platoon IS VARRAY(20) OF Soldier; p1 Platoon; p2 p1%TYPE;
You can declare collections as the formal parameters of functions and procedures. That way, you can pass collections to stored subprograms and from one subprogram to another. In the following example, you declare a nested table as the formal parameter of a packaged procedure:
CREATE PACKAGE personnel AS TYPE Staff IS TABLE OF Employee; ... PROCEDURE award_bonuses (members IN Staff); END personnel;
Also, you can specify a collection type in the RETURN clause of a function specification, as the following example shows:
DECLARE TYPE SalesForce IS VARRAY(25) OF Salesperson; FUNCTION top_performers (n INTEGER) RETURN SalesForce IS ...
Collections follow the usual scoping and instantiation rules. In a block or subprogram, collections are instantiated when you enter the block or subprogram and cease to exist when you exit. In a package, collections are instantiated when you first reference the package and cease to exist when you end the database session.
Until you initialize it, a nested table or varray is atomically null (that is, the collection itself is null, not its elements). To initialize a nested table or varray, you use a constructor, which is a system-defined function with the same name as the collection type. This function "constructs" collections from the elements passed to it. In the following example, you pass six elements to constructor CourseList(), which returns a nested table containing those elements:
DECLARE my_courses CourseList; BEGIN my_courses := CourseList('Econ 2010', 'Acct 3401', 'Mgmt 3100', 'PoSc 3141', 'Mktg 3312', 'Engl 2005'); ... END;
In the next example, you pass three objects to constructor ProjectList(), which returns a varray containing those objects:
DECLARE accounting_projects ProjectList; BEGIN accounting_projects := ProjectList(Project(1, 'Design New Expense Report', 3250), Project(2, 'Outsource Payroll', 12350), Project(3, 'Audit Accounts Payable', 1425)); ... END;
You need not initialize the whole varray. For example, if a varray has a maximum size of 50, you can pass fewer than 50 elements to its constructor.
Unless you impose the NOT NULL constraint or specify a record type for elements, you can pass null elements to a constructor. An example follows:
BEGIN my_courses := CourseList('Math 3010', NULL, 'Stat 3202', ...);
The next example shows that you can initialize a collection in its declaration, which is a good programming practice:
DECLARE my_courses CourseList := CourseList('Art 1111', 'Hist 3100', 'Engl 2005', ...);
If you call a constructor without arguments, you get an empty but non-null collection, as the following example shows:
DECLARE TYPE Clientele IS VARRAY(100) OF Customer; vips Clientele := Clientele(); -- initialize empty varray BEGIN IF vips IS NOT NULL THEN -- condition yields TRUE ... END IF; END;
Except for index-by tables, PL/SQL never calls a constructor implicitly, so you must call it explicitly. Constructor calls are allowed wherever function calls are allowed. That includes the SELECT, VALUES, and SET clauses.
In the example below, you insert a Student object into object table sophomores. The table constructor CourseList() provides a value for attribute courses.
BEGIN INSERT INTO sophomores VALUES (Student(5035, 'Janet Alvarez', '122 Broad St', 'FT', CourseList('Econ 2010', 'Acct 3401', 'Mgmt 3100', ...))); ...
In the final example, you insert a row into database table department. The varray constructor ProjectList() provides a value for column projects.
BEGIN INSERT INTO department VALUES(60, 'Security', 750400, ProjectList(Project(1, 'Issue New Employee Badges', 9500), Project(2, 'Find Missing IC Chips', 2750), Project(3, 'Inspect Emergency Exits', 1900))); ...
Every reference to an element includes a collection name and a subscript enclosed in parentheses. The subscript determines which element is processed. To reference an element, you specify its subscript using the syntax
collection_name(subscript)
where subscript is an expression that yields an integer. For index-by tables, the legal subscript range is -2147483647 .. 2147483647. For nested tables, the legal range is 1 .. 2147483647. And, for varrays, the legal range is 1 .. size_limit.
You can reference a collection in all expression contexts. In the following example, you reference an element in nested table names:
DECLARE TYPE Roster IS TABLE OF VARCHAR2(15); names Roster := Roster('J Hamil', 'D Caruso', 'R Singh', ...); i BINARY_INTEGER; BEGIN ... IF names(i) = 'J Hamil' THEN ... END IF; END;
The next example shows that you can reference the elements of a collection in subprogram calls:
DECLARE TYPE Roster IS TABLE OF VARCHAR2(15); names Roster := Roster('J Hamil', 'D Piro', 'R Singh', ...); i BINARY_INTEGER; BEGIN ... verify_name(names(i)); -- call procedure END;
When calling a function that returns a collection, use the following syntax to reference elements in the collection:
function_name(parameter_list)(subscript)
For example, the following call references the third element in the varray returned by function new_hires:
DECLARE TYPE Staff IS VARRAY(20) OF Employee; staffer Employee; FUNCTION new_hires (hiredate DATE) RETURN Staff IS ... BEGIN staffer := new_hires('16-OCT-96')(3); -- call function ... END;
One collection can be assigned to another by an INSERT, UPDATE, FETCH, or SELECT statement, an assignment statement, or a subprogram call. As the example below shows, the collections must have the same datatype. Having the same element type is not enough.
DECLARE TYPE Clientele IS VARRAY(100) OF Customer; TYPE Vips IS VARRAY(100) OF Customer; group1 Clientele := Clientele(...); group2 Clientele := Clientele(...); group3 Vips := Vips(...); BEGIN group2 := group1; group3 := group2; -- illegal; different datatypes
If you assign an atomically null collection to another collection, the other collection becomes atomically null (and must be reinitialized). Consider the following example:
DECLARE TYPE Clientele IS TABLE OF Customer; group1 Clientele := Clientele(...); -- initialized group2 Clientele; -- atomically null BEGIN IF group1 IS NULL THEN ... -- condition yields FALSE group1 := group2; IF group1 IS NULL THEN ... -- condition yields TRUE ... END;
Likewise, if you assign the non-value NULL to a collection, the collection becomes atomically null.
You can assign the value of an expression to a specific element in a collection using the syntax
collection_name(subscript) := expression;
where expression yields a value of the type specified for elements in the collection type definition. If subscript is null or not convertible to an integer, PL/SQL raises the predefined exception VALUE_ERROR. If the collection is atomically null, PL/SQL raises COLLECTION_IS_NULL. Some examples follow:
DECLARE TYPE NumList IS TABLE OF INTEGER; nums NumList := NumList(10,20,30); ints NumList; ... BEGIN ... nums(1) := TRUNC(high/low); nums(3) := nums(1); nums(2) := ASCII('B'); /* Assume execution continues despite the raised exception. */ nums('A') := 40; -- raises VALUE_ERROR ints(1) := 15; -- raises COLLECTION_IS_NULL END;
Nested tables and varrays can be atomically null, so they can be tested for nullity, as the following example shows:
DECLARE TYPE Staff IS TABLE OF Employee; members Staff; BEGIN ... IF members IS NULL THEN ... -- condition yields TRUE; END;
However, collections cannot be compared for equality or inequality. For instance, the following IF condition is illegal:
DECLARE TYPE Clientele IS TABLE OF Customer; group1 Clientele := Clientele(...); group2 Clientele := Clientele(...); BEGIN ... IF group1 = group2 THEN -- causes compilation error ... END IF; END;
This restriction also applies to implicit comparisons. For example, collections cannot appear in a DISTINCT, GROUP BY, or ORDER BY list.
Within PL/SQL, collections add flexibility and procedural power. A big advantage is that your program can compute subscripts to process specific elements. A bigger advantage is that the program can use SQL to manipulate in-memory collections.
In SQL*Plus, suppose you define object type Course, as follows:
SQL> CREATE TYPE Course AS OBJECT ( 2 course_no NUMBER(4), 3 title VARCHAR2(35), 4 credits NUMBER(1));
Next, you define TABLE type CourseList, which stores Course objects:
SQL> CREATE TYPE CourseList AS TABLE OF Course;
Finally, you create database table department, which has a column of type CourseList, as follows:
SQL> CREATE TABLE department ( 2 name VARCHAR2(20), 3 director VARCHAR2(20), 4 office VARCHAR2(20), 5 courses CourseList) 6 NESTED TABLE courses STORE AS courses_tab;
Each item in column courses is a nested table that will store the courses offered by a given department. The NESTED TABLE clause is required because department has a nested table column. The clause identifies the nested table and names a system-generated store table, in which Oracle stores data out-of-line (in another tablespace).
Now, you can populate database table department. In the following example, notice how table constructor CourseList() provides values for column courses:
BEGIN INSERT INTO department VALUES('Psychology', 'Irene Friedman', 'Fulton Hall 133', CourseList(Course(1000, 'General Psychology', 5), Course(2100, 'Experimental Psychology', 4), Course(2200, 'Psychological Tests', 3), Course(2250, 'Behavior Modification', 4), Course(3540, 'Groups and Organizations', 3), Course(3552, 'Human Factors in Busines', 4), Course(4210, 'Theories of Learning', 4), Course(4320, 'Cognitive Processes', 4), Course(4410, 'Abnormal Psychology', 4))); INSERT INTO department VALUES('History', 'John Whalen', 'Applegate Hall 142', CourseList(Course(1011, 'History of Europe I', 4), Course(1012, 'History of Europe II', 4), Course(1202, 'American History', 5), Course(2130, 'The Renaissance', 3), Course(2132, 'The Reformation', 3), Course(3105, 'History of Ancient Greece', 4), Course(3321, 'Early Japan', 4), Course(3601, 'Latin America Since 1825', 4), Course(3702, 'Medieval Islamic History', 4))); INSERT INTO department VALUES('English', 'Lynn Saunders', 'Breakstone Hall 205', CourseList(Course(1002, 'Expository Writing', 3), Course(2020, 'Film and Literature', 4), Course(2418, 'Modern Science Fiction', 3), Course(2810, 'Discursive Writing', 4), Course(3010, 'Modern English Grammar', 3), Course(3720, 'Introduction to Shakespeare', 4), Course(3760, 'Modern Drama', 4), Course(3822, 'The Short Story', 4), Course(3870, 'The American Novel', 5))); END;
In the following example, you revise the list of courses offered by the English Department:
DECLARE new_courses CourseList := CourseList(Course(1002, 'Expository Writing', 3), Course(2020, 'Film and Literature', 4), Course(2810, 'Discursive Writing', 4), Course(3010, 'Modern English Grammar', 3), Course(3550, 'Realism and Naturalism', 4), Course(3720, 'Introduction to Shakespeare', 4), Course(3760, 'Modern Drama', 4), Course(3822, 'The Short Story', 4), Course(3870, 'The American Novel', 4), Course(4210, '20th-Century Poetry', 4), Course(4725, 'Advanced Workshop in Poetry', 5)); BEGIN UPDATE department SET courses = new_courses WHERE name = 'English'; END;
In the next example, you retrieve all the courses offered by the Psychology Department into a local nested table:
DECLARE psyc_courses CourseList; BEGIN SELECT courses INTO psyc_courses FROM department WHERE name = 'Psychology'; ... END;
In SQL*Plus, suppose you define object type Project, as follows:
SQL> CREATE TYPE Project AS OBJECT ( 2 project_no NUMBER(2), 3 title VARCHAR2(35), 4 cost NUMBER(7,2));
Next, you define VARRAY type ProjectList, which stores Project objects:
SQL> CREATE TYPE ProjectList AS VARRAY(50) OF Project;
Finally, you create relational table department, which has a column of type ProjectList, as follows:
SQL> CREATE TABLE department ( 2 dept_id NUMBER(2), 3 name VARCHAR2(15), 4 budget NUMBER(11,2), 5 projects ProjectList);
Each item in column projects is a varray that will store the projects scheduled for a given department.
Now, you are ready to populate relational table department. In the following example, notice how varray constructor ProjectList() provides values for column projects:
BEGIN INSERT INTO department VALUES(30, 'Accounting', 1205700, ProjectList(Project(1, 'Design New Expense Report', 3250), Project(2, 'Outsource Payroll', 12350), Project(3, 'Evaluate Merger Proposal', 2750), Project(4, 'Audit Accounts Payable', 1425))); INSERT INTO department VALUES(50, 'Maintenance', 925300, ProjectList(Project(1, 'Repair Leak in Roof', 2850), Project(2, 'Install New Door Locks', 1700), Project(3, 'Wash Front Windows', 975), Project(4, 'Repair Faulty Wiring', 1350), Project(5, 'Winterize Cooling System', 1125))); INSERT INTO department VALUES(60, 'Security', 750400, ProjectList(Project(1, 'Issue New Employee Badges', 13500), Project(2, 'Find Missing IC Chips', 2750), Project(3, 'Upgrade Alarm System', 3350), Project(4, 'Inspect Emergency Exits', 1900))); END;
In the following example, you update the list of projects assigned to the Security Department:
DECLARE new_projects ProjectList := ProjectList(Project(1, 'Issue New Employee Badges', 13500), Project(2, 'Develop New Patrol Plan', 1250), Project(3, 'Inspect Emergency Exits', 1900), Project(4, 'Upgrade Alarm System', 3350), Project(5, 'Analyze Local Crime Stats', 825)); BEGIN UPDATE department SET projects = new_projects WHERE dept_id = 60; END;
In the next example, you retrieve all the projects for the Accounting Department into a local varray:
DECLARE my_projects ProjectList; BEGIN SELECT projects INTO my_projects FROM department WHERE dept_id = 30; ... END;
In the final example, you delete the Accounting Department and its project list from table department:
BEGIN DELETE FROM department WHERE dept_id = 30; END;
So far, you have manipulated whole collections. Within SQL, to manipulate the individual elements of a collection, use the operator TABLE. The operand of TABLE is a subquery that returns a single column value for you to manipulate. That value is a nested table or varray.
In the following example, you add a row to the History Department nested table stored in column courses:
BEGIN INSERT INTO TABLE(SELECT courses FROM department WHERE name = 'History') VALUES(3340, 'Modern China', 4); END;
In the next example, you revise the number of credits for two courses offered by the Psychology Department:
DECLARE adjustment INTEGER DEFAULT 1; BEGIN UPDATE TABLE(SELECT courses FROM department WHERE name = 'Psychology') SET credits = credits + adjustment WHERE course_no IN (2200, 3540); END;
In the following example, you retrieve the number and title of a specific course offered by the History Department:
DECLARE my_course_no NUMBER(4); my_title VARCHAR2(35); BEGIN SELECT course_no, title INTO my_course_no, my_title FROM TABLE(SELECT courses FROM department WHERE name = 'History') WHERE course_no = 3105; ... END;
In the next example, you delete all 5-credit courses offered by the English Department:
BEGIN DELETE TABLE(SELECT courses FROM department WHERE name = 'English') WHERE credits = 5; END;
In the following example, you retrieve the title and cost of the Maintenance Department's fourth project from the varray column projects:
DECLARE my_cost NUMBER(7,2); my_title VARCHAR2(35); BEGIN SELECT cost, title INTO my_cost, my_title FROM TABLE(SELECT projects FROM department WHERE dept_id = 50) WHERE project_no = 4; ... END;
Currently, you cannot reference the individual elements of a varray in an INSERT, UPDATE, or DELETE statement. So, you must use PL/SQL procedural statements. In the following example, stored procedure add_project inserts a new project into a department's project list at a given position:
CREATE PROCEDURE add_project ( dept_no IN NUMBER, new_project IN Project, position IN NUMBER) AS my_projects ProjectList; BEGIN SELECT projects INTO my_projects FROM department WHERE dept_no = dept_id FOR UPDATE OF projects; my_projects.EXTEND; -- make room for new project /* Move varray elements forward. */ FOR i IN REVERSE position..my_projects.LAST - 1 LOOP my_projects(i + 1) := my_projects(i); END LOOP; my_projects(position) := new_project; -- add new project UPDATE department SET projects = my_projects WHERE dept_no = dept_id; END add_project;
The following stored procedure updates a given project:
CREATE PROCEDURE update_project ( dept_no IN NUMBER, proj_no IN NUMBER, new_title IN VARCHAR2 DEFAULT NULL, new_cost IN NUMBER DEFAULT NULL) AS my_projects ProjectList; BEGIN SELECT projects INTO my_projects FROM department WHERE dept_no = dept_id FOR UPDATE OF projects; /* Find project, update it, then exit loop immediately. */ FOR i IN my_projects.FIRST..my_projects.LAST LOOP IF my_projects(i).project_no = proj_no THEN IF new_title IS NOT NULL THEN my_projects(i).title := new_title; END IF; IF new_cost IS NOT NULL THEN my_projects(i).cost := new_cost; END IF; EXIT; END IF; END LOOP; UPDATE department SET projects = my_projects WHERE dept_no = dept_id; END update_project;
Within PL/SQL, to manipulate a local collection, use the operators TABLE and CAST. The operands of CAST are a collection declared locally (in a PL/SQL anonymous block for example) and a SQL collection type. CAST converts the local collection to the specified type. That way, you can manipulate the collection as if it were a SQL database table. In the following example, you count the number of differences between a revised course list and the original (notice that the number of credits for course 3720 changed from 4 to 3):
DECLARE revised CourseList := CourseList(Course(1002, 'Expository Writing', 3), Course(2020, 'Film and Literature', 4), Course(2810, 'Discursive Writing', 4), Course(3010, 'Modern English Grammar ', 3), Course(3550, 'Realism and Naturalism', 4), Course(3720, 'Introduction to Shakespeare',3), Course(3760, 'Modern Drama', 4), Course(3822, 'The Short Story', 4), Course(3870, 'The American Novel', 5), Course(4210, '20th-Century Poetry', 4), Course(4725, 'Advanced Workshop in Poetry',5)); num_changed INTEGER; BEGIN SELECT COUNT(*) INTO num_changed FROM TABLE(CAST(revised AS CourseList)) AS new, TABLE(SELECT courses FROM department WHERE name = 'English') AS old WHERE new.course_no = old.course_no AND (new.title != old.title OR new.credits != old.credits); DBMS_OUTPUT.PUT_LINE(num_changed); END;
The following collection methods help generalize code, make collections easier to use, and make your applications easier to maintain:
A collection method is a built-in function or procedure that operates on collections and is called using dot notation. The syntax follows:
collection_name.method_name[(parameters)]
Collection methods can be called from procedural statements but not from SQL statements. EXISTS, COUNT, LIMIT, FIRST, LAST, PRIOR, and NEXT are functions, which appear as part of an expression. EXTEND, TRIM, and DELETE are procedures, which appear as a statement. Also, EXISTS, PRIOR, NEXT, TRIM, EXTEND, and DELETE take parameters. Each parameter must be an integer expression.
Only EXISTS can be applied to atomically null collections. If you apply another method to such collections, PL/SQL raises COLLECTION_IS_NULL.
EXISTS(n) returns TRUE if the nth element in a collection exists. Otherwise, EXISTS(n) returns FALSE. Mainly, you use EXISTS with DELETE to maintain sparse nested tables. You can also use EXISTS to avoid raising an exception when you reference a nonexistent element. In the following example, PL/SQL executes the assignment statement only if element i exists:
IF courses.EXISTS(i) THEN courses(i) := new_course; END IF;
When passed an out-of-range subscript, EXISTS returns FALSE instead of raising SUBSCRIPT_OUTSIDE_LIMIT.
COUNT returns the number of elements that a collection currently contains. For instance, if varray projects contains 15 elements, the following IF condition is true:
IF projects.COUNT = 15 THEN ...
COUNT is useful because the current size of a collection is not always known. For example, if you fetch a column of Oracle data into a nested table, how many elements does the table contain? COUNT gives you the answer.
You can use COUNT wherever an integer expression is allowed. In the next example, you use COUNT to specify the upper bound of a loop range:
FOR i IN 1..courses.COUNT LOOP ...
For varrays, COUNT always equals LAST. For nested tables, COUNT normally equals LAST. But, if you delete elements from the middle of a nested table, COUNT becomes smaller than LAST.
When tallying elements, COUNT ignores deleted elements.
For nested tables, which have no maximum size, LIMIT returns NULL. For varrays, LIMIT returns the maximum number of elements that a varray can contain (which you must specify in its type definition). For instance, if the maximum size of varray projects is 25 elements, the following IF condition is true:
IF projects.LIMIT = 25 THEN ...
You can use LIMIT wherever an integer expression is allowed. In the following example, you use LIMIT to determine if you can add 20 more elements to varray projects:
IF (projects.COUNT + 20) < projects.LIMIT THEN ...
FIRST and LAST return the first and last (smallest and largest) index numbers in a collection. If the collection is empty, FIRST and LAST return NULL. If the collection contains only one element, FIRST and LAST return the same index number, as the following example shows:
IF courses.FIRST = courses.LAST THEN ... -- only one element
The next example shows that you can use FIRST and LAST to specify the lower and upper bounds of a loop range provided each element in that range exists:
FOR i IN courses.FIRST..courses.LAST LOOP ...
In fact, you can use FIRST or LAST wherever an integer expression is allowed. In the following example, you use FIRST to initialize a loop counter:
i := courses.FIRST; WHILE i IS NOT NULL LOOP ...
For varrays, FIRST always returns 1 and LAST always equals COUNT. For nested tables, FIRST normally returns 1. But, if you delete elements from the beginning of a nested table, FIRST returns a number larger than 1. Also for nested tables, LAST normally equals COUNT. But, if you delete elements from the middle of a nested table, LAST becomes larger than COUNT.
When scanning elements, FIRST and LAST ignore deleted elements.
PRIOR(n) returns the index number that precedes index n in a collection. NEXT(n) returns the index number that succeeds index n. If n has no predecessor, PRIOR(n) returns NULL. Likewise, if n has no successor, NEXT(n) returns NULL.
PRIOR and NEXT do not wrap from one end of a collection to the other. For example, the following statement assigns NULL to n because the first element in a collection has no predecessor:
n := courses.PRIOR(courses.FIRST); -- assigns NULL to n
PRIOR is the inverse of NEXT. For instance, if element i exists, the following statement assigns element i to itself:
projects(i) := projects.PRIOR(projects.NEXT(i));
You can use PRIOR or NEXT to traverse collections indexed by any series of subscripts. In the following example, you use NEXT to traverse a nested table from which some elements have been deleted:
i := courses.FIRST; -- get subscript of first element WHILE i IS NOT NULL LOOP -- do something with courses(i) i := courses.NEXT(i); -- get subscript of next element END LOOP;
When traversing elements, PRIOR and NEXT ignore deleted elements.
To increase the size of a collection, use EXTEND. This procedure has three forms. EXTEND appends one null element to a collection. EXTEND(n) appends n null elements to a collection. EXTEND(n,i) appends n copies of the ith element to a collection. For example, the following statement appends 5 copies of element 1 to nested table courses:
courses.EXTEND(5,1);
You cannot use EXTEND to initialize an atomically null collection. Also, if you impose the NOT NULL constraint on a TABLE or VARRAY type, you cannot apply the first two forms of EXTEND to collections of that type.
EXTEND operates on the internal size of a collection, which includes any deleted elements. So, if EXTEND encounters deleted elements, it includes them in its tally. PL/SQL keeps placeholders for deleted elements so that you can replace them if you wish. Consider the following example:
DECLARE TYPE CourseList IS TABLE OF VARCHAR2(10); courses CourseList; BEGIN courses := CourseList('Biol 4412', 'Psyc 3112', 'Anth 3001'); courses.DELETE(3); -- delete element 3 /* PL/SQL keeps a placeholder for element 3. So, the next statement appends element 4, not element 3. */ courses.EXTEND; -- append one null element /* Now element 4 exists, so the next statement does not raise SUBSCRIPT_BEYOND_COUNT. */ courses(4) := 'Engl 2005';
When it includes deleted elements, the internal size of a nested table differs from the values returned by COUNT and LAST. For instance, if you initialize a nested table with five elements, then delete elements 2 and 5, the internal size is 5, COUNT returns 3, and LAST returns 4. All deleted elements (whether leading, in the middle, or trailing) are treated alike.
This procedure has two forms. TRIM removes one element from the end of a collection. TRIM(n) removes n elements from the end of a collection. For example, this statement removes the last three elements from nested table courses:
courses.TRIM(3);
If n is greater than COUNT, TRIM(n) raises SUBSCRIPT_BEYOND_COUNT.
TRIM operates on the internal size of a collection. So, if TRIM encounters deleted elements, it includes them in its tally. Consider the following example:
DECLARE TYPE CourseList IS TABLE OF VARCHAR2(10); courses CourseList; BEGIN courses := CourseList('Biol 4412', 'Psyc 3112', 'Anth 3001'); courses.DELETE(courses.LAST); -- delete element 3 /* At this point, COUNT equals 2, the number of valid elements remaining. So, you might expect the next statement to empty the nested table by trimming elements 1 and 2. Instead, it trims valid element 2 and deleted element 3 because TRIM includes deleted elements in its tally. */ courses.TRIM(courses.COUNT); DBMS_OUTPUT.PUT_LINE(courses(1)); -- prints 'Biol 4412'
In general, do not depend on the interaction between TRIM and DELETE. It is better to treat nested tables like fixed-size arrays and use only DELETE, or to treat them like stacks and use only TRIM and EXTEND.
PL/SQL does not keep placeholders for trimmed elements. So, you cannot replace a trimmed element simply by assigning it a new value.
This procedure has three forms. DELETE removes all elements from a collection. DELETE(n) removes the nth element from a nested table. If n is null, DELETE(n) does nothing. DELETE(m,n) removes all elements in the range m..n from an index-by table or a nested table. If m is larger than n or if m or n is null, DELETE(m,n) does nothing. Some examples follow:
BEGIN ... courses.DELETE(2); -- deletes element 2 courses.DELETE(7,7); -- deletes element 7 courses.DELETE(6,3); -- does nothing courses.DELETE(3,6); -- deletes elements 3 through 6 projects.DELETE; -- deletes all elements END;
Varrays are dense, so you cannot delete their individual elements.
If an element to be deleted does not exist, DELETE simply skips it; no exception is raised. PL/SQL keeps placeholders for deleted elements. So, you can replace a deleted element simply by assigning it a new value.
DELETE allows you to maintain sparse nested tables. In the following example, you retrieve nested table prospects into a temporary table, prune it, then store it back in the database:
DECLARE my_prospects ProspectList; revenue NUMBER; BEGIN SELECT prospects INTO my_prospects FROM customers WHERE ... FOR i IN my_prospects.FIRST..my_prospects.LAST LOOP estimate_revenue(my_prospects(i), revenue); -- call procedure IF revenue < 25000 THEN my_prospects.DELETE(i); END IF; END LOOP; UPDATE customers SET prospects = my_prospects WHERE ...
The amount of memory allocated to a nested table can increase or decrease dynamically. As you delete elements, memory is freed page by page. If you delete the entire table, all the memory is freed.
Within a subprogram, a collection parameter assumes the properties of the argument bound to it. So, you can apply the built-in collection methods (FIRST, LAST, COUNT, and so on) to such parameters. In the following example, a nested table is declared as the formal parameter of a packaged procedure:
CREATE PACKAGE personnel AS TYPE Staff IS TABLE OF Employee; ... PROCEDURE award_bonuses (members IN Staff); END personnel; CREATE PACKAGE BODY personnel AS ... PROCEDURE award_bonuses (members IN Staff) IS BEGIN ... IF members.COUNT > 10 THEN -- apply method ... END IF; END; END personnel;
Note: For varray parameters, the value of LIMIT is always derived from the parameter type definition, regardless of the parameter mode.
In most cases, if you reference a nonexistent collection element, PL/SQL raises a predefined exception. Consider the following example:
DECLARE TYPE NumList IS TABLE OF NUMBER; nums NumList; -- atomically null BEGIN /* Assume execution continues despite the raised exceptions. */ nums(1) := 1; -- raises COLLECTION_IS_NULL (1) nums := NumList(1,2); -- initialize table nums(NULL) := 3 -- raises VALUE_ERROR (2) nums(0) := 3; -- raises SUBSCRIPT_OUTSIDE_LIMIT (3) nums(3) := 3; -- raises SUBSCRIPT_BEYOND_COUNT (4) nums.DELETE(1); -- delete element 1 IF nums(1) = 1 THEN ... -- raises NO_DATA_FOUND (5)
In the first case, the nested table is atomically null. In the second case, the subscript is null. In the third case, the subscript is outside the legal range. In the fourth case, the subscript exceeds the number of elements in the table. In the fifth case, the subscript designates a deleted element.
The following list shows when a given exception is raised:
In some cases, you can pass "invalid" subscripts to a method without raising an exception. For instance, when you pass a null subscript to procedure DELETE, it does nothing. Also, you can replace deleted elements without raising NO_DATA_FOUND, as the following example shows:
DECLARE TYPE NumList IS TABLE OF NUMBER; nums NumList := NumList(10,20,30); -- initialize table BEGIN ... nums.DELETE(-1); -- does not raise SUBSCRIPT_OUTSIDE_LIMIT nums.DELETE(3); -- delete 3rd element DBMS_OUTPUT.PUT_LINE(nums.COUNT); -- prints 2 nums(3) := 30; -- legal; does not raise NO_DATA_FOUND DBMS_OUTPUT.PUT_LINE(nums.COUNT); -- prints 3 END;
Packaged collection types and local collection types are never compatible. For example, suppose you want to call the following packaged procedure:
CREATE PACKAGE pkg1 AS TYPE NumList IS VARRAY(25) OF NUMBER(4); PROCEDURE delete_emps (emp_list NumList); ... END pkg1; CREATE PACKAGE BODY pkg1 AS PROCEDURE delete_emps (emp_list NumList) IS ... ... END pkg1;
When you run the PL/SQL block below, the second procedure call fails with a wrong number or types of arguments error. That is because the packaged and local VARRAY types are incompatible even though their definitions are identical.
DECLARE TYPE NumList IS VARRAY(25) OF NUMBER(4); emps pkg1.NumList := pkg1.NumList(7369, 7499); emps2 NumList := NumList(7521, 7566); BEGIN pkg1.delete_emps(emps); pkg1.delete_emps(emps2); -- causes a compilation error END;
Embedded in the Oracle RDBMS, the PL/SQL engine accepts any valid PL/SQL block or subprogram. As Figure 4-3 shows, the PL/SQL engine executes procedural statements but sends SQL statements to the SQL engine, which executes the SQL statements and, in some cases, returns data to the PL/SQL engine.
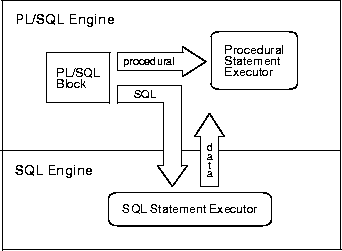
Each context switch between the PL/SQL and SQL engines adds to overhead. So, if many switches are required, performance suffers. That can happen when SQL statements execute inside a loop using collection (index-by table, nested table, varray, or host array) elements as bind variables. For example, the following DELETE statement is sent to the SQL engine with each iteration of the FOR loop:
DECLARE TYPE NumList IS VARRAY(20) OF NUMBER; depts NumList := NumList(10, 30, 70, ...); -- department numbers BEGIN ... FOR i IN depts.FIRST..depts.LAST LOOP ... DELETE FROM emp WHERE deptno = depts(i); END LOOP; END;
In such cases, if the SQL statement affects five or more database rows, the use of bulk binds can improve performance considerably.
The assigning of values to PL/SQL variables in SQL statements is called binding. The binding of an entire collection at once is called bulk binding. Bulk binds improve performance by minimizing the number of context switches between the PL/SQL and SQL engines. With bulk binds, entire collections, not just individual elements, are passed back and forth. For example, the following DELETE statement is sent to the SQL engine just once, with an entire nested table:
DECLARE TYPE NumList IS TABLE OF NUMBER; mgrs NumList := NumList(7566, 7782, ...); -- manager numbers BEGIN ... FORALL i IN mgrs.FIRST..mgrs.LAST DELETE FROM emp WHERE mgr = mgrs(i); END;
In the example below, 5000 part numbers and names are loaded into index-by tables. Then, all table elements are inserted into a database table twice. First, they are inserted using a FOR loop, which completes in 38 seconds. Then, they are bulk-inserted using a FORALL statement, which completes in only 3 seconds.
SQL> SET SERVEROUTPUT ON SQL> CREATE TABLE parts (pnum NUMBER(4), pname CHAR(15)); Table created. SQL> GET test.sql 1 DECLARE 2 TYPE NumTab IS TABLE OF NUMBER(4) INDEX BY BINARY_INTEGER; 3 TYPE NameTab IS TABLE OF CHAR(15) INDEX BY BINARY_INTEGER; 4 pnums NumTab; 5 pnames NameTab; 6 t1 CHAR(5); 7 t2 CHAR(5); 8 t3 CHAR(5); 9 PROCEDURE get_time (t OUT NUMBER) IS 10 BEGIN SELECT TO_CHAR(SYSDATE,'SSSSS') INTO t FROM dual; END; 11 BEGIN 12 FOR j IN 1..5000 LOOP -- load index-by tables 13 pnums(j) := j; 14 pnames(j) := 'Part No. ' || TO_CHAR(j); 15 END LOOP; 16 get_time(t1); 17 FOR i IN 1..5000 LOOP -- use FOR loop 18 INSERT INTO parts VALUES (pnums(i), pnames(i)); 19 END LOOP; 20 get_time(t2); 21 FORALL i IN 1..5000 -- use FORALL statement 22 INSERT INTO parts VALUES (pnums(i), pnames(i)); 23 get_time(t3); 24 DBMS_OUTPUT.PUT_LINE('Execution Time (secs)'); 25 DBMS_OUTPUT.PUT_LINE('---------------------'); 26 DBMS_OUTPUT.PUT_LINE('FOR loop: ' || TO_CHAR(t2 - t1)); 27 DBMS_OUTPUT.PUT_LINE('FORALL: ' || TO_CHAR(t3 - t2)); 28* END; SQL> / Execution Time (secs) --------------------- FOR loop: 38 FORALL: 3 PL/SQL procedure successfully completed.
To bulk-bind input collections, use the FORALL statement. To bulk-bind output collections, use the BULK COLLECT clause.
The keyword FORALL instructs the PL/SQL engine to bulk-bind input collections before sending them to the SQL engine. Although the FORALL statement contains an iteration scheme, it is not a FOR loop. Its syntax follows:
FORALL index IN lower_bound..upper_bound sql_statement;
The index can be referenced only within the FORALL statement and only as a collection subscript. The SQL statement must be an INSERT, UPDATE, or DELETE statement that references collection elements. And, the bounds must specify a valid range of consecutive index numbers. The SQL engine executes the SQL statement once for each index number in the range. As the following example shows, you can use the bounds to bulk-bind arbitrary slices of a collection:
DECLARE TYPE NumList IS VARRAY(15) OF NUMBER; depts NumList := NumList(); BEGIN -- fill varray here ... FORALL j IN 6..10 -- bulk-bind middle third of varray UPDATE emp SET sal = sal * 1.10 WHERE deptno = depts(j); END;
The SQL statement can reference more than one collection. However, the PL/SQL engine bulk-binds only subscripted collections. So, in the following example, it does not bulk-bind the collection sals, which is passed to the function median:
FORALL i IN 1..20 INSERT INTO emp2 VALUES (enums(i), names(i), median(sals), ...);
The next example shows that the collection subscript cannot be an expression:
FORALL j IN mgrs.FIRST..mgrs.LAST DELETE FROM emp WHERE mgr = mgrs(j+1); -- illegal subscript
All collection elements in the specified range must exist. If an element is missing or was deleted, you get an error, as the following example shows:
DECLARE TYPE NumList IS TABLE OF NUMBER; depts NumList := NumList(10, 20, 30, 40); BEGIN depts.DELETE(3); -- delete third element FORALL i IN depts.FIRST..depts.LAST DELETE FROM emp WHERE deptno = depts(i); -- raises an "element does not exist" exception END;
If a FORALL statement fails, database changes are rolled back to an implicit savepoint marked before each execution of the SQL statement. Changes made during previous executions are not rolled back. For example, suppose you create a database table that stores department numbers and job titles, as follows:
CREATE TABLE emp2 (deptno NUMBER(2), job VARCHAR2(15));
Next, you insert some rows into the table, as follows:
INSERT INTO emp2 VALUES(10, 'Clerk'); INSERT INTO emp2 VALUES(10, 'Clerk'); INSERT INTO emp2 VALUES(20, 'Bookkeeper'); -- 10-char job title INSERT INTO emp2 VALUES(30, 'Analyst'); INSERT INTO emp2 VALUES(30, 'Analyst');
Then, you try to append the 7-character string ' (temp)' to certain job titles using the following UPDATE statement:
DECLARE TYPE NumList IS TABLE OF NUMBER; depts NumList := NumList(10, 20); BEGIN FORALL j IN depts.FIRST..depts.LAST UPDATE emp2 SET job = job || ' (temp)' WHERE deptno = depts(j); -- raises a "value too large" exception EXCEPTION WHEN OTHERS THEN COMMIT; END;
The SQL engine executes the UPDATE statement twice, once for each index number in the specified range; that is, once for depts(10) and once for depts(20). The first execution succeeds, but the second execution fails because the string value 'Bookkeeper (temp)' is too large for the job column. In this case, only the second execution is rolled back.
The keywords BULK COLLECT tell the SQL engine to bulk-bind output collections before returning them to the PL/SQL engine. You can use these keywords in the SELECT INTO, FETCH INTO, and RETURNING INTO clauses. Here is the syntax:
... BULK COLLECT INTO collection_name[, collection_name] ...
The SQL engine bulk-binds all collections referenced in the INTO list. The corresponding columns must store scalar (not composite) values. In the following example, the SQL engine loads the entire empno and ename database columns into nested tables before returning the tables to the PL/SQL engine:
DECLARE TYPE NumTab IS TABLE OF emp.empno%TYPE; TYPE NameTab IS TABLE OF emp.ename%TYPE; enums NumTab; -- no need to initialize names NameTab; BEGIN SELECT empno, ename BULK COLLECT INTO enums, names FROM emp; ... END;
The SQL engine initializes and extends collections for you. (However, it cannot extend varrays beyond their maximum size.) Then, starting at index 1, it inserts elements consecutively and overwrites any pre-existent elements.
The SQL engine bulk-binds entire database columns. So, if a table has 50,000 rows, the engine loads 50,000 column values into the target collection. However, you can use the pseudocolumn ROWNUM to limit the number of rows processed. In the following example, you limit the number of rows to 100:
DECLARE TYPE NumTab IS TABLE OF emp.empno%TYPE; sals NumTab; BEGIN SELECT sal BULK COLLECT INTO sals FROM emp WHERE ROWNUM <= 100; ... END;
The following example shows that you can bulk-fetch from a cursor into one or more collections:
DECLARE TYPE NameTab IS TABLE OF emp.ename%TYPE; TYPE SalTab IS TABLE OF emp.sal%TYPE; names NameTab; sals SalTab; CURSOR c1 IS SELECT ename, sal FROM emp WHERE sal > 1000; BEGIN OPEN c1; FETCH c1 BULK COLLECT INTO names, sals; ... END;
Restriction: You cannot bulk-fetch from a cursor into a collection of records, as the following example shows:
DECLARE TYPE EmpRecTab IS TABLE OF emp%ROWTYPE; emp_recs EmpRecTab; CURSOR c1 IS SELECT ename, sal FROM emp WHERE sal > 1000; BEGIN OPEN c1; FETCH c1 BULK COLLECT INTO emp_recs; -- illegal ... END;
You can combine the BULK COLLECT clause with a FORALL statement, in which case, the SQL engine bulk-binds column values incrementally. In the following example, if collection depts has 3 elements, each of which causes 5 rows to be deleted, then collection enums has 15 elements when the statement completes:
FORALL j IN depts.FIRST..depts.LAST DELETE FROM emp WHERE empno = depts(j) RETURNING empno BULK COLLECT INTO enums;
The column values returned by each execution are added to the values returned previously. (With a FOR loop, the previous values are overwritten.)
Restriction: You cannot use the SELECT ... BULK COLLECT statement in a FORALL statement.
Client-side programs can use anonymous PL/SQL blocks to bulk-bind input and output host arrays. In fact, that is the most efficient way to pass collections to and from the database server.
Host arrays are declared in a host environment such as an OCI or Pro*C program and must be prefixed with a colon to distinguish them from PL/SQL collections. In the example below, an input host array is used in a DELETE statement. At run time, the anonymous PL/SQL block is sent to the database server for execution.
DECLARE ... BEGIN -- assume that values were assigned to the host array -- and host variables in the host environment FORALL i IN :lower..:upper DELETE FROM emp WHERE deptno = :depts(i); ... END;
You cannot use collection methods such as FIRST and LAST with host arrays. For example, the following statement is illegal:
FORALL i IN :depts.FIRST..:depts.LAST -- illegal DELETE FROM emp WHERE deptno = :depts(i);
To process SQL data manipulation statements, the SQL engine opens an implicit cursor named SQL. This cursor's attributes (%FOUND, %ISOPEN, %NOTFOUND, and %ROWCOUNT) return useful information about the most recently executed SQL data manipulation statement.
The SQL cursor has only one composite attribute, %BULK_ROWCOUNT, which has the semantics of an index-by table. Its ith element stores the number of rows processed by the ith execution of a SQL statement. If the ith execution affects no rows, %BULK_ROWCOUNT(i) returns zero. An example follows:
DECLARE TYPE NumList IS TABLE OF NUMBER; depts NumList := NumList(10, 20, 50); BEGIN FORALL j IN depts.FIRST..depts.LAST UPDATE emp SET sal = sal * 1.10 WHERE deptno = depts(j); IF SQL%BULK_ROWCOUNT(3) = 0 THEN ... END IF END;
%BULK_ROWCOUNT and the FORALL statement use the same subscripts. For instance, if the FORALL statement uses the range -5..10, so does %BULK_ROWCOUNT.
Note: Only index-by tables can have negative subscripts.
You can also use the scalar attributes %FOUND, %NOTFOUND, and %ROWCOUNT with bulk binds. For example, %ROWCOUNT returns the total number of rows processed by all executions of the SQL statement.
%FOUND and %NOTFOUND refer only to the last execution of the SQL statement. However, you can use %BULK_ROWCOUNT to infer their values for individual executions. For example, when %BULK_ROWCOUNT(i) is zero, %FOUND and %NOTFOUND are FALSE and TRUE, respectively.
Restrictions: %BULK_ROWCOUNT cannot be assigned to other collections. Also, it cannot be passed as a parameter to subprograms.
A record is a group of related data items stored in fields, each with its own name and datatype. Suppose you have various data about an employee such as name, salary, and hire date. These items are logically related but dissimilar in type. A record containing a field for each item lets you treat the data as a logical unit. Thus, records make it easier to organize and represent information.
The attribute %ROWTYPE lets you declare a record that represents a row in a database table. However, you cannot specify the datatypes of fields in the record or declare fields of your own. The datatype RECORD lifts those restrictions and lets you define your own records.
To create records, you define a RECORD type, then declare records of that type. You can define RECORD types in the declarative part of any PL/SQL block, subprogram, or package using the syntax
TYPE type_name IS RECORD (field_declaration[,field_declaration]...);
where field_declaration stands for
field_name field_type [[NOT NULL] {:= | DEFAULT} expression]
and where type_name is a type specifier used later to declare records, field_type is any PL/SQL datatype except REF CURSOR, and expression yields a value of the same type as field_type.
Note: Unlike TABLE and VARRAY types, RECORD types cannot be CREATEd and stored in the database.
You can use %TYPE and %ROWTYPE to specify field types. In the following example, you define a RECORD type named DeptRec:
DECLARE TYPE DeptRec IS RECORD ( dept_id dept.deptno%TYPE, dept_name VARCHAR2(15), dept_loc VARCHAR2(15));
Notice that field declarations are like variable declarations. Each field has a unique name and specific datatype. So, the value of a record is actually a collection of values, each of some simpler type.
As the example below shows, PL/SQL lets you define records that contain objects, collections, and other records (called nested records). However, object types cannot have attributes of type RECORD.
DECLARE TYPE TimeRec IS RECORD ( seconds SMALLINT, minutes SMALLINT, hours SMALLINT); TYPE FlightRec IS RECORD ( flight_no INTEGER, plane_id VARCHAR2(10), captain Employee, -- declare object passengers PassengerList, -- declare varray depart_time TimeRec, -- declare nested record airport_code VARCHAR2(10));
The next example shows that you can specify a RECORD type in the RETURN clause of a function specification. That allows the function to return a user-defined record of the same type.
DECLARE TYPE EmpRec IS RECORD ( emp_id INTEGER last_name VARCHAR2(15), dept_num INTEGER(2), job_title VARCHAR2(15), salary REAL(7,2)); ... FUNCTION nth_highest_salary (n INTEGER) RETURN EmpRec IS ...
Once you define a RECORD type, you can declare records of that type, as the following example shows:
DECLARE TYPE StockItem IS RECORD ( item_no INTEGER(3), description VARCHAR2(50), quantity INTEGER, price REAL(7,2)); item_info StckItem; -- declare record
The identifier item_info represents an entire record.
Like scalar variables, user-defined records can be declared as the formal parameters of procedures and functions. An example follows:
DECLARE TYPE EmpRec IS RECORD ( emp_id emp.empno%TYPE, last_name VARCHAR2(10), job_title VARCHAR2(15), salary NUMBER(7,2)); ... PROCEDURE raise_salary (emp_info EmpRec);
The example below shows that you can initialize a record in its type definition. When you declare a record of type TimeRec, its three fields assume an initial value of zero.
DECLARE TYPE TimeRec IS RECORD ( secs SMALLINT := 0, mins SMALLINT := 0, hrs SMALLINT := 0);
The next example shows that you can impose the NOT NULL constraint on any field, and so prevent the assigning of nulls to that field. Fields declared as NOT NULL must be initialized.
DECLARE TYPE StockItem IS RECORD ( item_no INTEGER(3) NOT NULL := 999, description VARCHAR2(50), quantity INTEGER, price REAL(7,2));
Unlike elements in a collection, which are accessed using subscripts, fields in a record are accessed by name. To reference an individual field, use dot notation and the following syntax:
record_name.field_name
For example, you reference field hire_date in record emp_info as follows:
emp_info.hire_date ...
When calling a function that returns a user-defined record, use the following syntax to reference fields in the record:
function_name(parameter_list).field_name
For example, the following call to function nth_highest_sal references the field salary in record emp_info:
DECLARE TYPE EmpRec IS RECORD ( emp_id NUMBER(4), job_title CHAR(14), salary REAL(7,2)); middle_sal REAL; FUNCTION nth_highest_sal (n INTEGER) RETURN EmpRec IS emp_info EmpRec; BEGIN ... RETURN emp_info; -- return record END; BEGIN middle_sal := nth_highest_sal(10).salary; -- call function
When calling a parameterless function, use the following syntax:
function_name().field_name -- note empty parameter list
To reference nested fields in a record returned by a function, use extended dot notation. The syntax follows:
function_name(parameter_list).field_name.nested_field_name
For instance, the following call to function item references the nested field minutes in record item_info:
DECLARE TYPE TimeRec IS RECORD (minutes SMALLINT, hours SMALLINT); TYPE AgendaItem IS RECORD ( priority INTEGER, subject VARCHAR2(100), duration TimeRec); FUNCTION item (n INTEGER) RETURN AgendaItem IS item_info AgendaItem; BEGIN ... RETURN item_info; -- return record END; BEGIN ... IF item(3).duration.minutes > 30 THEN ... -- call function END;
Also, use extended dot notation to reference the attributes of an object stored in a field, as the following example shows:
DECLARE TYPE FlightRec IS RECORD ( flight_no INTEGER, plane_id VARCHAR2(10), captain Employee, -- declare object passengers PassengerList, -- declare varray depart_time TimeRec, -- declare nested record airport_code VARCHAR2(10)); flight FlightRec; BEGIN ... IF flight.captain.name = 'H Rawlins' THEN ... END;
You can assign the value of an expression to a specific field in a record using the following syntax:
record_name.field_name := expression;
In the following example, you convert an employee name to upper case:
emp_info.ename := UPPER(emp_info.ename);
Instead of assigning values separately to each field in a record, you can assign values to all fields at once. This can be done in two ways. First, you can assign one user-defined record to another if they have the same datatype. Having fields that match exactly is not enough. Consider the following example:
DECLARE TYPE DeptRec IS RECORD ( dept_num NUMBER(2), dept_name VARCHAR2(14), location VARCHAR2(13)); TYPE DeptItem IS RECORD ( dept_num NUMBER(2), dept_name VARCHAR2(14), location VARCHAR2(13)); dept1_info DeptRec; dept2_info DeptItem; BEGIN ... dept1_info := dept2_info; -- illegal; different datatypes END;
As the next example shows, you can assign a %ROWTYPE record to a user-defined record if their fields match in number and order, and corresponding fields have compatible datatypes:
DECLARE TYPE DeptRec IS RECORD ( dept_num NUMBER(2), dept_name CHAR(14), location CHAR(13)); dept1_info DeptRec; dept2_info dept%ROWTYPE; BEGIN SELECT * INTO dept2_info FROM dept WHERE deptno = 10; dept1_info := dept2_info;
Second, you can use the SELECT or FETCH statement to fetch column values into a record, as the example below shows. The columns in the select-list must appear in the same order as the fields in your record.
DECLARE TYPE DeptRec IS RECORD ( dept_num NUMBER(2), dept_name CHAR(14), location CHAR(13)); dept_info DeptRec; BEGIN SELECT deptno, dname, loc INTO dept_info FROM dept WHERE deptno = 20; ... END;
However, you cannot use the INSERT statement to insert user-defined records into a database table. So, the following statement is illegal:
INSERT INTO dept VALUES (dept_info); -- illegal
Also, you cannot assign a list of values to a record using an assignment statement. Therefore, the following syntax is illegal:
record_name := (value1, value2, value3, ...); -- illegal
The example below shows that you can assign one nested record to another if they have the same datatype. Such assignments are allowed even if the enclosing records have different datatypes.
DECLARE TYPE TimeRec IS RECORD (mins SMALLINT, hrs SMALLINT); TYPE MeetingRec IS RECORD ( day DATE, time_of TimeRec, -- nested record room_no INTEGER(4)); TYPE PartyRec IS RECORD ( day DATE, time_of TimeRec, -- nested record place VARCHAR2(25)); seminar MeetingRec; party PartyRec; BEGIN ... party.time_of := seminar.time_of; END;
Records cannot be tested for nullity, equality, or inequality. For instance, the following IF conditions are illegal:
BEGIN ... IF emp_info IS NULL THEN ... -- illegal IF dept2_info > dept1_info THEN ... -- illegal END;
The datatype RECORD lets you collect information about the attributes of something. The information is easy to manipulate because you can refer to the collection as a whole. In the following example, you collect accounting figures from database tables assets and liabilities, then use ratio analysis to compare the performance of two subsidiary companies:
DECLARE TYPE FiguresRec IS RECORD (cash REAL, notes REAL, ...); sub1_figs FiguresRec; sub2_figs FiguresRec; FUNCTION acid_test (figs FiguresRec) RETURN REAL IS ... BEGIN SELECT cash, notes, ... INTO sub1_figs FROM assets, liabilities WHERE assets.sub = 1 AND liabilities.sub = 1; SELECT cash, notes, ... INTO sub2_figs FROM assets, liabilities WHERE assets.sub = 2 AND liabilities.sub = 2; IF acid_test(sub1_figs) > acid_test(sub2_figs) THEN ... ... END;
Notice how easy it is to pass the collected figures to the function acid_test, which computes a financial ratio.
In SQL*Plus, suppose you define object type Passenger, as follows:
SQL> CREATE TYPE Passenger AS OBJECT( 2 flight_no NUMBER(3), 3 name VARCHAR2(20), 4 seat CHAR(5));
Next, you define VARRAY type PassengertList, which stores Passenger objects:
SQL> CREATE TYPE PassengerList AS VARRAY(300) OF Passenger;
Finally, you create relational table flights, which has a column of type PassengerList, as follows:
SQL> CREATE TABLE flights ( 2 flight_no NUMBER(3), 3 gate CHAR(5), 4 departure CHAR(15), 5 arrival CHAR(15), 6 passengers PassengerList);
Each item in column passengers is a varray that will store the passenger list for a given flight. Now, you can populate database table flights, as follows:
BEGIN INSERT INTO flights VALUES(109, '80', 'DFW 6:35PM', 'HOU 7:40PM', PassengerList(Passenger(109, 'Paula Trusdale', '13C'), Passenger(109, 'Louis Jemenez', '22F'), Passenger(109, 'Joseph Braun', '11B'), ...)); INSERT INTO flights VALUES(114, '12B', 'SFO 9:45AM', 'LAX 12:10PM', PassengerList(Passenger(114, 'Earl Benton', '23A'), Passenger(114, 'Alma Breckenridge', '10E'), Passenger(114, 'Mary Rizutto', '11C'), ...)); INSERT INTO flights VALUES(27, '34', 'JFK 7:05AM', 'MIA 9:55AM', PassengerList(Passenger(27, 'Raymond Kiley', '34D'), Passenger(27, 'Beth Steinberg', '3A'), Passenger(27, 'Jean Lafevre', '19C'), ...)); END;
In the example below, you fetch rows from database table flights into record flight_info. That way, you can treat all the information about a flight, including its passenger list, as a logical unit.
DECLARE TYPE FlightRec IS RECORD ( flight_no NUMBER(3), gate CHAR(5), departure CHAR(15), arrival CHAR(15), passengers PassengerList); flight_info FlightRec; CURSOR c1 IS SELECT * FROM flights; BEGIN OPEN c1; LOOP FETCH c1 INTO flight_info; EXIT WHEN c1%NOTFOUND; FOR i IN 1..flight_info.passengers.LAST LOOP IF flight_info.passengers(i).seat = 'NA' THEN DBMS_OUTPUT.PUT_LINE(flight_info.passengers(i).name); RAISE seat_not_available; END IF; ... END LOOP; END LOOP; CLOSE c1; EXCEPTION WHEN seat_not_available THEN ... END;