Release 8.1.5
A67775-01
Library |
Product |
Contents |
Index |
| Oracle8i Tuning Release 8.1.5 A67775-01 |
|
![]()
![]()
This chapter provides an overview of data access methods that can enhance performance. It also warns of situations to avoid. This chapter also explains how to used hints to force various approaches. Topics in this chapter include:
This section describes:
Indexes improve the performance of queries that select a small percentage of rows from a table. As a general guideline, create indexes on tables that are queried for less than 2% or 4% of the table's rows. This value may be higher in situations where all data can be retrieved from an index, or where the indexed columns and expressions can be used for joining to other tables.
This guideline is based on these assumptions:
If these assumptions do not describe the data in your table and the queries that access it, then an index may not be helpful unless your queries typically access at least 25% of the table's rows.
Although cost-based optimization helps avoid the use of nonselective indexes within query execution, the SQL engine must continue to maintain all indexes defined against a table regardless of whether they are used. Index maintenance can present a significant CPU and I/O resource demand in any I/O intensive application. Put another way, building indexes "just in case" is not a good practice; indexes should not be built until required.
To maintain optimal performance as far as indexes are concerned, drop indexes that your application is not using. You can find indexes that are not referenced in execution plans by processing all of your application SQL through EXPLAIN PLAN and capturing the resulting plans. Unused indexes are typically, though not necessarily, nonselective.
Indexes within an application sometimes have uses that are not immediately apparent from a survey of statement execution plans. In particular, Oracle uses "pins" (nontransactional locks) on foreign key indexes to avoid using shared locks on the child table when enforcing foreign key constraints.
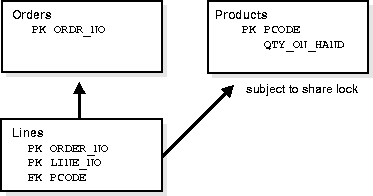
In many applications a foreign key index never, or rarely, supports a query. In the example shown in Figure 6-1, the need to locate all of the order lines for a given product may never arise. However, when no index exists with LINES(PCODE) as its leading portion (as described in "Choosing Composite Indexes"), then Oracle places a share lock on the LINES table each time PRODUCTS(PCODE) is updated or deleted. Such a share lock is a problem only if the PRODUCTS table is subject to frequent DML.
If this contention arises, then to remove it the application must either:
A key is a column or expression on which you can build an index. Follow these guidelines for choosing index keys to index:
You can determine the selectivity of an index by dividing the number of rows in the table by the number of distinct indexed values. You can obtain these values using the ANALYZE statement. Selectivity calculated in this manner should be interpreted as a percentage.
A composite index contains more than one key column. Composite indexes can provide additional advantages over single-column indexes:
A SQL statement can use an access path involving a composite index if the statement contains constructs that use a leading portion of the index. A leading portion of an index is a set of one or more columns that were specified first and consecutively in the list of columns in the CREATE INDEX statement that created the index. Consider this CREATE INDEX statement:
CREATE INDEX comp_ind ON tab1(x, y, z);
These combinations of columns are leading portions of the index: X, XY, and XYZ. These combinations of columns are not leading portions of the index: YZ, Z, and Y.
Follow these guidelines for choosing keys for composite indexes:
Of course, consider the guidelines associated with the general performance advantages and trade-offs of indexes described in the previous sections. Follow these guidelines for ordering keys in composite indexes:
Even after you create an index, the optimizer cannot use an access path that uses the index simply because the index exists. The optimizer can choose such an access path for a SQL statement only if it contains a construct that makes the access path available.
To be sure that a SQL statement can use an access path that uses an index, be sure the statement contains a construct that makes such an access path available. If you are using the cost-based approach, also generate statistics for the index. Once you have made the access path available for the statement, the optimizer may or may not choose to use the access path, based on the availability of other access paths.
If you create new indexes to tune statements, you can also use the EXPLAIN PLAN statement to determine whether the optimizer will choose to use these indexes when the application is run. If you create new indexes to tune a statement that is currently parsed, Oracle invalidates the statement. When the statement is next executed, the optimizer automatically chooses a new execution plan that could potentially use the new index. If you create new indexes on a remote database to tune a distributed statement, the optimizer considers these indexes when the statement is next parsed.
Also keep in mind that the way you tune one statement may affect the optimizer's choice of execution plans for others. For example, if you create an index to be used by one statement, the optimizer may choose to use that index for other statements in your application as well. For this reason, you should re-examine your application's performance and rerun the SQL trace facility after you have tuned those statements that you initially identified for tuning.
In some cases, you may want to prevent a SQL statement from using an access path that uses an existing index. You may want to do this if you know that the index is not very selective and that a full table scan would be more efficient. If the statement contains a construct that makes such an index access path available, you can force the optimizer to use a full table scan through one of these methods:
The behavior of the optimizer may change in future versions of Oracle, so relying on methods such as the first to choose access paths may not be a good long-range plan. Instead, use hints to suggest specific access paths to the optimizer.
A crude way to determine whether an index is good is to create it, analyze it, and use EXPLAIN PLAN on your query to see if the optimizer uses it. If it does, keep the index unless it is expensive to maintain. This method, however, is very time- and resource-consuming. A preferable method is to compare the optimizer cost (in the first row of EXPLAIN PLAN output) of the plans with and without the index.
Parallel execution uses indexes effectively. It does not perform parallel index range scans, but it does perform parallel index lookups for parallel nested loop join execution. If an index is very selective (there are few rows per index entry), then it may be better to use sequential index lookup than parallel table scan.
The fast full index scan is an alternative to a full table scan when there is an index that contains all the keys that are needed for the query. A fast full scan is faster than a normal full index scan in that it can use multiblock I/O and can be parallelized just like a table scan. Unlike regular index scans, however, you cannot use keys and the rows will not necessarily come back in sorted order. The following query and plan illustrate this feature.
SELECT COUNT(*) FROM t1, t2 WHERE t1.c1 > 50 and t1.c2 = t2.c1;
The plan is as follows:
SELECT STATEMENTSORT AGGREGATEHASH JOINTABLE ACCESS1FULL INDEXT2_C1_IDX FAST FULL SCAN
Since index T2_C1_IDX contains all columns needed from table T2(C2), the optimizer uses a fast full index scan on that index.
Fast full scan has the following restrictions:
Fast full scan has a special index hint, INDEX_FFS, which has the same format and arguments as the regular INDEX hint.
You may wish to re-create an index to compact it and minimize fragmented space, or to change the index's storage characteristics. When creating a new index that is a subset of an existing index, or when rebuilding an existing index with new storage characteristics, Oracle may use the existing index instead of the base table to improve performance.
However, there are cases where it may be beneficial to use the base table instead of the existing index. Consider an index on a table on which a lot of DML has been performed. Because of the DML, the size of the index may increase to the point where each block is only 50% full, or even maybe less. If the index refers to most of the columns in the table, the index could actually be larger than the table. In this case, it is faster to use the base table rather than the index to re-create the index. Another option is to create a new index on a subset of the columns of the original index.
Consider, for example, a table named CUST with columns NAME, CUSTID, PHONE, ADDR, BALANCE, and an index named I_CUST_CUSTINFO on table columns NAME, CUSTID and BALANCE. To create a new index named I_CUST_CUSTNO on columns CUSTID and NAME, you would enter:
CREATE INDEX I_CUST_CUSTNO ON CUST(CUSTID,NAME);
Oracle automatically uses the existing index (I_CUST_CUSTINFO) to create the new index rather than accessing the entire table. The syntax used is the same as if the index I_CUST_CUSTINFO did not exist.
Similarly, if you have an index on the EMPNO and MGR columns of the EMP table, and you want to change the storage characteristics of that composite index, Oracle can use the existing index to create the new index.
Use the ALTER INDEX ... REBUILD statement to reorganize or compact an existing index or to change its storage characteristics. The REBUILD statement uses the existing index as the basis for the new one. All index storage statements are supported, such as STORAGE (for extent allocation), TABLESPACE (to move the index to a new tablespace), and INITRANS (to change the initial number of entries).
ALTER INDEX ... REBUILD is usually faster than dropping and re-creating an index, because this statement uses the fast full scan feature. It reads all the index blocks using multiblock I/O then discards the branch blocks. A further advantage of this approach is that the old index is still available for queries (but not for DML) while the rebuild is in progress.
|
See Also:
Oracle8i SQL Reference for more information about the CREATE INDEX and ALTER INDEX statements and for restrictions on re-building indexes. |
You can coalesce leaf blocks of an index using the ALTER INDEX statement with the COALESCE option. This allows you to combine leaf levels of an index to free blocks for re-use. You can also rebuild the index online.
For more information about the syntax for this statement, please refer to the Oracle8i SQL Reference and the Oracle8i Administrator's Guide.
You can use an existing nonunique index on a table to enforce uniqueness, either for UNIQUE constraints or the unique aspect of a PRIMARY KEY constraint. The advantage of this approach is that the index remains available and valid when the constraint is disabled. Therefore, enabling a disabled UNIQUE or PRIMARY KEY constraint does not require rebuilding the unique index associated with the constraint. This can yield significant time savings on enable operations for large tables.
Using a nonunique index to enforce uniqueness also allows you to eliminate redundant indexes. You do not need a unique index on a primary key column if that column already is included as the prefix of a composite index. You may use the existing index to enable and enforce the constraint. You also save significant space by not duplicating the index.
An enabled novalidated constraint behaves similarly to an enabled validated constraint. Placing a constraint in the enabled novalidated state signifies that any new data entered into the table must conform to the constraint. Existing data is not checked. Placing a constraint in the enabled novalidated state allows you to enable the constraint without locking the table.
If you change a constraint from disabled to enabled, the table must be locked. No new DML, queries, or DDL can occur because there is no mechanism to ensure that operations on the table conform to the constraint during the enable operation. The enabled novalidated state prevents operations violating the constraint from being performed on the table.
An enabled novalidated constraint can be validated with a parallel, consistent-read query of the table to determine whether any data violates the constraint. No locking is performed and the enable operation does not block readers or writers to the table. In addition, enabled novalidated constraints can be validated in parallel: multiple constraints can be validated at the same time and each constraint's validity check can be determined using parallel query.
Use the following approach to create tables with constraints and indexes:
For example,
CREATE TABLE t (a NUMBER CONSTRAINT apk PRIMARY KEY DISABLE, b NUMBER NOT NULL); CREATE TABLE x (c NUMBER CONSTRAINT afk REFERENCES t DISABLE);
At this point, use import or fast loader to load data into t.
CREATE UNIQUE INDEX tai ON t (a); CREATE INDEX tci ON x (c); ALTER TABLE t MODIFY CONSTRAINT apk ENABLE NOVALIDATE; ALTER TABLE x MODIFY CONSTRAINT afk ENABLE NOVALIDATE;
Now users can start performing inserts, updates, deletes, and selects on t.
ALTER TABLE t ENABLE CONSTRAINT apk; ALTER TABLE x ENABLE CONSTRAINT afk;
Now the constraints are enabled and validated.
A function-based index is an index on an expression. Oracle strongly recommends using function-based indexes whenever possible. Define function-based indexes anywhere where you use an index on a column, except for columns with LOBs, or REFs. Nested table columns and object types cannot contain these columns.
You can create function-based indexes for any repeatable SQL function. Oracle recommends using function-based indexes for range scans and for functions in ORDER BY clauses.
Function-based indexes are an efficient mechanism for evaluating statements that contain functions in WHERE clauses. You can create a function-based index to materialize computational-intensive expressions in the index. This permits Oracle to bypass computing the value of the expression when processing SELECT and DELETE statements. When processing INSERT and UPDATE statements, however, Oracle evaluates the function to process the statement.
For example, if you create the following index:
CREATE INDEX idx ON table_1 (a + b * (c - 1), a, b);
Oracle can use it when processing queries such as:
SELECT a FROM table_1 WHERE a + b * (c - 1) < 100;
Function-based indexes defined with the UPPER(column_name) or LOWER(column_name) keywords allow case-insensitive searches. For example, the following index:
CREATE INDEX uppercase_idx ON emp (UPPER(empname));
Facilitates processing queries such as:
SELECT * FROM emp WHERE UPPER(empname) = 'MARK';
You can also use function-based indexes for NLS sort indexes that provide efficient linguistic collation in SQL statements.
Oracle treats indexes with columns marked DESC as function-based indexes. The columns marked DESC are sorted in descending order.
The secondary index on an IOT can be a function-based index.
This section describes:
This section describes three aspects of indexing that you must evaluate when considering whether to use bitmap indexing on a given table: performance, storage, and maintenance.
Bitmap indexes can substantially improve performance of queries with the following characteristics:
You can use multiple bitmap indexes to evaluate the conditions on a single table. Bitmap indexes are thus highly advantageous for complex ad hoc queries that contain lengthy WHERE clauses. Bitmap indexes can also provide optimal performance for aggregate queries and for optimizing joins in star schemas.
|
See Also:
For more information, please refer to the optimizing anti-joins and semi-joins discussion in Oracle8i Concepts. |
Bitmap indexes can provide considerable storage savings over the use of multicolumn (or concatenated) B*-tree indexes. In databases containing only B*-tree indexes, you must anticipate the columns that would commonly be accessed together in a single query, and create a composite B*-tree index on these columns.
Not only would this B*-tree index require a large amount of space, but it would also be ordered. That is, a B*-tree index on (MARITAL_STATUS, REGION, GENDER) is useless for queries that only access REGION and GENDER. To completely index the database, you must create indexes on the other permutations of these columns. For the simple case of three low-cardinality columns, there are six possible composite B*-tree indexes. You must consider the trade-offs between disk space and performance needs when determining which composite B*-tree indexes to create.
Bitmap indexes solve this dilemma. Bitmap indexes can be efficiently combined during query execution, so three small single-column bitmap indexes can do the job of six three-column B*-tree indexes.
Bitmap indexes are much more efficient than B*-tree indexes, especially in data warehousing environments. Bitmap indexes are created not only for efficient space usage, but also for efficient execution, and the latter is somewhat more important.
If a bitmap index is created on a unique key column, it requires more space than a regular B*-tree index. However, for columns where each value is repeated hundreds or thousands of times, a bitmap index typically is less than 25% of the size of a regular B*-tree index. The bitmaps themselves are stored in compressed format.
Simply comparing the relative sizes of B*-tree and bitmap indexes is not an accurate measure of effectiveness, however. Because of their different performance characteristics, you should keep B*-tree indexes on high-cardinality data, while creating bitmap indexes on low-cardinality data.
Bitmap indexes benefit data warehousing applications but they are not appropriate for OLTP applications with a heavy load of concurrent INSERTs, UPDATEs, and DELETEs. In a data warehousing environment, data is usually maintained by way of bulk inserts and updates. Index maintenance is deferred until the end of each DML operation. For example, if you insert 1000 rows, the inserted rows are placed into a sort buffer and then the updates of all 1000 index entries are batched. (This is why SORT_AREA_SIZE must be set properly for good performance with inserts and updates on bitmap indexes.) Thus each bitmap segment is updated only once per DML operation, even if more than one row in that segment changes.
|
Note: The sorts described above are regular sorts and use the regular sort area, determined by SORT_AREA_SIZE. The BITMAP_MERGE_AREA_SIZE and CREATE_BITMAP_AREA_SIZE parameters described in "Initialization Parameters for Bitmap Indexing" only affect the specific operations indicated by the parameter names. |
DML and DDL statements such as UPDATE, DELETE, DROP TABLE, affect bitmap indexes the same way they do traditional indexes: the consistency model is the same. A compressed bitmap for a key value is made up of one or more bitmap segments, each of which is at most half a block in size (but may be smaller). The locking granularity is one such bitmap segment. This may affect performance in environments where many transactions make simultaneous updates. If numerous DML operations have caused increased index size and decreasing performance for queries, you can use the ALTER INDEX ... REBUILD statement to compact the index and restore efficient performance.
A B*-tree index entry contains a single rowid. Therefore, when the index entry is locked, a single row is locked. With bitmap indexes, an entry can potentially contain a range of rowids. When a bitmap index entry is locked, the entire range of rowids is locked. The number of rowids in this range affects concurrency. For example, a bitmap index on a column with unique values would lock one rowid per value: concurrency would be the same as for B*-tree indexes. As the number of rowids increases in a bitmap segment, concurrency decreases.
Locking issues affect DML operations, and thus may affect heavy OLTP environments. Locking issues do not, however, affect query performance. As with other types of indexes, updating bitmap indexes is a costly operation. Nonetheless, for bulk inserts and updates where many rows are inserted or many updates are made in a single statement, performance with bitmap indexes can be better than with regular B*-tree indexes.
To create a bitmap index, use the BITMAP keyword in the CREATE INDEX statement:
CREATE BITMAP INDEX ...
Multi-column (concatenated) bitmap indexes are supported; they can be defined over no more than 32 columns. Other SQL statements concerning indexes, such as DROP, ANALYZE, ALTER, and so on, can refer to bitmap indexes without any extra keyword. For information on bitmap index restrictions, please refer to Oracle8i SQL Reference
System index views USER_INDEXES, ALL_INDEXES, and DBA_INDEXES indicate bitmap indexes by the word BITMAP appearing in the TYPE column. A bitmap index cannot be declared as UNIQUE.
The INDEX hint works with bitmap indexes in the same way as with traditional indexes.
The INDEX_COMBINE hint identifies the most cost effective hints for the optimizer. The optimizer recognizes all indexes that can potentially be combined, given the predicates in the WHERE clause. However, it may not be cost effective to use all of them. Oracle recommends using INDEX_COMBINE rather than INDEX for bitmap indexes because it is a more versatile hint.
In deciding which of these hints to use, the optimizer includes non-hinted indexes that appear cost effective as well as indexes named in the hint. If certain indexes are given as arguments for the hint, the optimizer tries to use some combination of those particular bitmap indexes.
If the hint does not name indexes, all indexes are considered hinted. Hence, the optimizer tries to combine as many as is possible given the WHERE clause, without regard to cost effectiveness. The optimizer always tries to use hinted indexes in the plan regardless of whether it considers them cost effective.
To obtain optimal performance and disk space usage with bitmap indexes, note the following considerations:
Use SQL statements with the ALTER TABLE syntax to optimize the mapping of bitmaps to rowids. The MINIMIZE RECORDS_PER_BLOCK clause enables this optimization and the NOMINIMIZE RECORDS_PER_BLOCK clause disables it.
When enabled, Oracle scans the table and determines the maximum number of records in any block and restricts this table to this maximum number. This enables bitmap indexes to allocate fewer bits per block and results in smaller bitmap indexes. The block and record allocation restrictions this statement places on the table are only beneficial to bitmap indexes. Therefore, Oracle does not recommend using this mapping on tables that are not heavily indexed with bitmap indexes.
|
See Also:
"Using Bitmap Indexes". Also refer to the Oracle8i SQL Reference for details on the use of the MINIMIZE and NOMINIMIZE syntax. |
Bitmap indexes index nulls, whereas all other index types do not. Consider, for example, a table with STATE and PARTY columns, on which you want to perform the following query:
SELECT COUNT(*) FROM people WHERE state='CA' and party !='D';
Indexing nulls enables a bitmap minus plan where bitmaps for party equal to 'D' and NULL are subtracted from state bitmaps equal to 'CA'. The EXPLAIN PLAN output would look like this:
SELECT STATEMENT SORT AGGREGATE BITMAP CONVERSION COUNT BITMAP MINUS BITMAP MINUS BITMAP INDEX SINGLE VALUE STATE_BM BITMAP INDEX SINGLE VALUE PARTY_BM BITMAP INDEX SINGLE VALUE PARTY_BM
If a NOT NULL constraint existed on party, the second minus operation (where party is null) would be left out because it is not needed.
The following two initialization parameters have an effect on performance.
This parameter determines the amount of memory allocated for bitmap creation. The default value is 8MB. A larger value may lead to faster index creation. If cardinality is very small, you can set a small value for this parameter. For example, if cardinality is only 2, then the value can be on the order of kilobytes rather than megabytes. As a general rule, the higher the cardinality, the more memory is needed for optimal performance. You cannot dynamically alter this parameter at the system or session level.
This parameter determines the amount of memory used to merge bitmaps retrieved from a range scan of the index. The default value is 1 MB. A larger value should improve performance because the bitmap segments must be sorted before being merged into a single bitmap. You cannot dynamically alter this parameter at the system or session level.
|
See Also:
For more information on improving bitmap index efficiency, please see "Efficient Mapping of Bitmaps to Rowids" . |
If there is at least one bitmap index on the table, the optimizer considers using a bitmap access path using regular B*-tree indexes for that table. This access path may involve combinations of B*-tree and bitmap indexes, but might not involve any bitmap indexes at all. However, the optimizer will not generate a bitmap access path using a single B*-tree index unless instructed to do so by a hint.
To use bitmap access paths for B*-tree indexes, the rowids stored in the indexes must be converted to bitmaps. After such a conversion, the various Boolean operations available for bitmaps can be used. As an example, consider the following query, where there is a bitmap index on column C1, and regular B*-tree indexes on columns C2 and C3.
EXPLAIN PLAN FOR SELECT COUNT(*) FROM T WHERE C1 = 2 AND C2 = 6 OR C3 BETWEEN 10 AND 20; SELECT STATEMENT SORT AGGREGATE BITMAP CONVERSION COUNT BITMAP OR BITMAP AND BITMAP INDEX C1_IND SINGLE VALUE BITMAP CONVERSION FROM ROWIDS INDEX C2_IND RANGE SCAN BITMAP CONVERSION FROM ROWIDS SORT ORDER BY INDEX C3_IND RANGE SCAN
Here, a COUNT option for the BITMAP CONVERSION row source counts the number of rows matching the query. There are also conversions FROM rowids in the plan to generate bitmaps from the rowids retrieved from the B*-tree indexes. The occurrence of the ORDER BY sort in the plan is due to the fact that the conditions on column C3 result in more than one list of rowids being returned from the B*-tree index. These lists are sorted before they can be converted into a bitmap.
Although it is not possible to precisely size a bitmap index, you can estimate its size. This section describes how to determine the size of a bitmap index for a table using the computed size of a B*-tree index. It also illustrates how cardinality, NOT NULL constraints, and number of distinct values affect bitmap size.
To estimate the size of a bitmap index for a given table, you may extrapolate from the size of a B*-tree index for the table. Use the following approach:
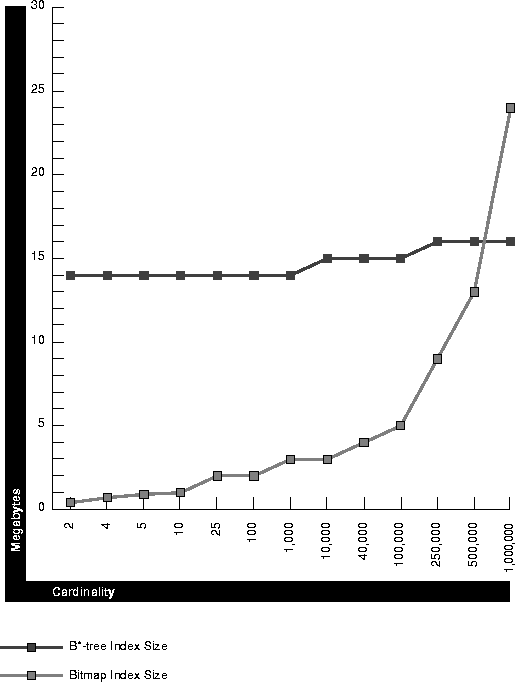
For a 1 million row table, Figure 6-2 shows index size on columns with different numbers of distinct values, for B*-tree indexes and bitmap indexes. Using Figure 6-2 you can estimate the size of a bitmap index relative to that of a B*-tree index for the table. Sizing is not exact: results vary somewhat from table to table.
Randomly distributed data was used to generate the graph. If, in your data, particular values tend to cluster close together, you may generate considerably smaller bitmap indexes than indicated by the graph. Bitmap indexes may be slightly smaller than those in the graph if columns contain NOT NULL constraints.
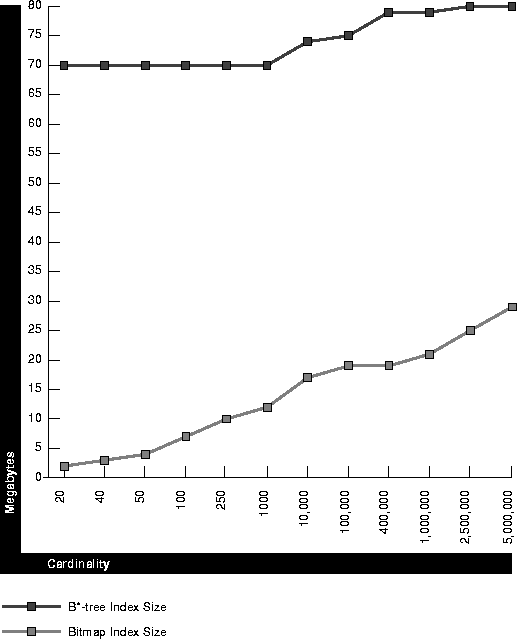
Figure 6-3 shows similar data for a table with 5 million rows. When cardinality exceeds 100,000, bitmap index size does not increase as fast as it does in Figure 6-2. For a table with more rows, there are more repeating values for a given cardinality.
Bitmap indexes have the following restrictions:
Domain indexes are built using the indexing logic supplied by a user-defined indextype. Typically, the user-defined indextype is part of a data cartridge. For example, the Spatial cartridge provides a SpatialIndextype to index spatial data.
An indextype provides an efficient mechanism to access data that satisfy certain operator predicates. For example, the SpatialIndextype allows efficient search and retrieval of spatial data that overlap a given bounding box.
The cartridge determines the parameters you can specify in creating and maintaining the domain index. Similarly, the performance and storage characteristics of the domain index are presented in the specific cartridge documentation.
Refer to the appropriate cartridge documentation for information such as:
For information about the SpatialIndextype, please refer to the Oracle8i Spatial User's Guide and Reference.
See Also:
Follow these guidelines when deciding whether to cluster tables:
Consider the benefits and drawbacks of clusters with respect to the needs of your application. For example, you may decide that the performance gain for join statements outweighs the performance loss for statements that modify cluster key values. You may want to experiment and compare processing times with your tables both clustered and stored separately. To create a cluster, use the CREATE CLUSTER statement.
|
See Also:
For more information on creating clusters, see Oracle8i Application Developer's Guide - Fundamentals. |
Hash clusters group table data by applying a hash function to each row's cluster key value. All rows with the same cluster key value are stored on disk. Consider the benefits and drawbacks of hash clusters with respect to the needs of your application. You may want to experiment and compare processing times with a particular table as it is stored in a hash cluster, and as it is stored alone with an index. This section describes:
Follow these guidelines for choosing when to use hash clusters:
To create a hash cluster, use the CREATE CLUSTER statement with the HASHKEYS parameter.
When you create a hash cluster, you must use the HASHKEYS parameter of the CREATE CLUSTER statement to specify the number of hash values for the hash cluster. For best performance of hash scans, choose a HASHKEYS value that is at least as large as the number of cluster key values. Such a value reduces the chance of collisions, or multiple cluster key values resulting in the same hash value. Collisions force Oracle to test the rows in each block for the correct cluster key value after performing a hash scan. Collisions reduce the performance of hash scans.
Oracle always rounds up the HASHKEYS value that you specify to the nearest prime number to obtain the actual number of hash values. This rounding is designed to reduce collisions.
|
See Also:
For more information on creating hash clusters, see Oracle8i Application Developer's Guide - Fundamentals. |