Release 8.1.5
A67773-01
Library |
Product |
Contents |
Index |
| Oracle8i Backup and Recovery Guide Release 8.1.5 A67773-01 |
|
![]()
![]()
This chapter describes how to manage data structures that are crucial for successful backup and recovery. It includes the following topics:
See Also: For a conceptual overview of these data structures, see Oracle8i Concepts. For detailed administration information, see the Oracle8i Administrator's Guide. If you are using Oracle with the Parallel Server, see Oracle8i Parallel Server Concepts and Administration.
The single most useful strategy in backup and recovery is planning ahead. To prevent data loss, you must foresee the various ways that data can be lost and develop your defense accordingly.
An important aspect of planning head is the intelligent management of database data structures. For example, what can you do to prevent a database crash if your control file become corrupted? What can you do to prevent the loss of archived redo logs if a disk failure occurs? Besides the datafiles, the data structures that are most important for developing a backup and recovery strategy are:
If these structures become corrupted or unavailable, you may find yourself unable to recover lost data.
If you have sufficient resources, you can help protect yourself from data loss by following this basic data management strategy:
This chapter assumes that you understand the function of the control file, online redo logs, and archived redo logs as well as the basics of how to administer them. If you do not, refer to the relevant chapters in Oracle8i Concepts and the Oracle8i Administrator's Guide.
Note:
The control file is a small binary file containing a record of the database schema. It is one of the most essential files in the database because it is necessary for the database to start and operate successfully. Oracle updates a control file continuously during database use, so it must be available for writing whenever the database is mounted. If for some reason the control file is not accessible, then the database cannot be mounted and recovery is difficult.
A control file contains information about the associated database that is required for the database to be accessed by an instance, both at startup and during normal operation. Only the Oracle server can modify a control file's information; no user can edit a database's control file.
The control file has various properties that make it crucial for backup and recovery. For example, the control file:
This section addresses the following topics relating to control file management:
Your first step in managing the control file is learning how to gain information about it. The following data dictionary views contain useful information:
For example, the following query displays the database control files:
SELECT name FROM v$controlfile; NAME -------------------------------------------------------------------------------- /vobs/oracle/dbs/cf1.f /vobs/oracle/dbs/cf2.f 2 rows selected.
To display the control file type, query the V$DATABASE view:
SELECT controlfile_type FROM v$database; CONTROL ------------ BACKUP
The following useful command displays all control files, datafiles, and online redo log files for the database:
SELECT member FROM v$logfile UNION ALL SELECT name FROM v$datafile UNION ALL SELECT name FROM v$controlfile; MEMBER -------------------------------------------------------------------------------- /vobs/oracle/dbs/rdo_log1.f /vobs/oracle/dbs/rdo_log2.f /vobs/oracle/dbs/tbs_01.f /vobs/oracle/dbs/tbs_02.f /vobs/oracle/dbs/tbs_11.f /vobs/oracle/dbs/tbs_12.f /vobs/oracle/dbs/tbs_21.f /vobs/oracle/dbs/tbs_22.f /vobs/oracle/dbs/tbs_13.f /vobs/oracle/dbs/cf1.f /vobs/oracle/dbs/cf2.f 11 rows selected.
See Also: For more information on the dynamic performance views, see the Oracle8i Reference.
Each time that a user adds, renames, or drops a datafile or an online redo log file from the database, Oracle updates the control file to reflect this physical structure change. Oracle records these changes so that it can identify:
Therefore, if you make a change to your database's physical structure, immediately back up your control file. If you do not, and your control file is corrupted or destroyed, then your backup control file will not accurately reflect the state of the database at the time of the failure.
Generate a binary copy of the control file or back up to a text trace file (with the destination specified by the USER_DUMP_DEST initialization parameter). You can run the script in the text trace file to re-create the control file. Back up the control file after you issue any of the following commands:
SQL> ALTER DATABASE MOUNT;
SQL> ALTER DATABASE BACKUP CONTROLFILE TO '/oracle/backup/cf.f';
You can back up the control file to a trace file and then use the script in this file to re-create the control file.
SQL> ALTER DATABASE MOUNT;
SQL> ALTER DATABASE BACKUP CONTROLFILE TO TRACE;
For example, to edit trace rman_ora_839.trc on UNIX enter:
% vi rman_ora_839.trc *** SESSION ID:(8.1) 1998.12.09.13.26.36.000 *** 1998.12.09.13.26.36.000 # The following commands will create a new control file and use it # to open the database. # Data used by the recovery manager will be lost. Additional logs may # be required for media recovery of offline data files. Use this # only if the current version of all online logs are available. STARTUP NOMOUNT CREATE CONTROLFILE REUSE DATABASE "RMAN" NORESETLOGS ARCHIVELOG MAXLOGFILES 32 MAXLOGMEMBERS 2 MAXDATAFILES 32 MAXINSTANCES 1 MAXLOGHISTORY 1012 LOGFILE GROUP 1 '/oracle/dbs/t1_log1.f' SIZE 200K, GROUP 2 '/oracle/dbs/t1_log2.f' SIZE 200K DATAFILE '/oracle/dbs/tbs_01.f', '/oracle/dbs/tbs_02.f', '/oracle/dbs/tbs_11.f', '/oracle/dbs/tbs_12.f', '/oracle/dbs/tbs_21.f', '/oracle/dbs/tbs_22.f', CHARACTER SET WE8DEC ; # Configure snapshot controlfile filename EXECUTE SYS.DBMS_BACKUP_RESTORE.CFILESETSNAPSHOTNAME('/oracle/dbs/snapcf_rman.f'); # Recovery is required if any of the datafiles are restored backups, # or if the last shutdown was not normal or immediate. RECOVER DATABASE # All logs need archiving and a log switch is needed. ALTER SYSTEM ARCHIVE LOG ALL; # Database can now be opened normally. ALTER DATABASE OPEN; # No tempfile entries found to add.
See Also: For more information on managing the control file, see the Oracle8i Administrator's Guide. For a sample scenario involving editing a trace file, see "Backing Up the Control File to a Trace File".
As with online redo log files, Oracle allows you to multiplex control files, i.e., configure Oracle to open and write to multiple, identical copies. Oracle writes the same data to each copy of the control file. You can also mirror them, i.e., allow the O/S to write a copy of a control file to two or more physical disks.
Mirroring at the O/S level is often better than multiplexing at the Oracle level, since O/S mirroring usually tolerates failure of one of the mirrors, whereas Oracle does not. With Oracle multiplexing, if any one of the mirror sides fail, then the instance shuts down. The user then has to either:
init.ora file accordingly.
With O/S or hardware mirroring, you achieve the same redundancy that you do with multiplexing, but in many cases you do not have to pay with a loss in availability when a failure occurs.
The permanent loss of all copies of a database's control file is a serious problem. If any copy of a control file fails during database operation, then the instance aborts and media recovery is required. If you do not multiplex or mirror the control file, then recovery will be more complex. Therefore, you should use multiplexed or mirrored control files with each database.
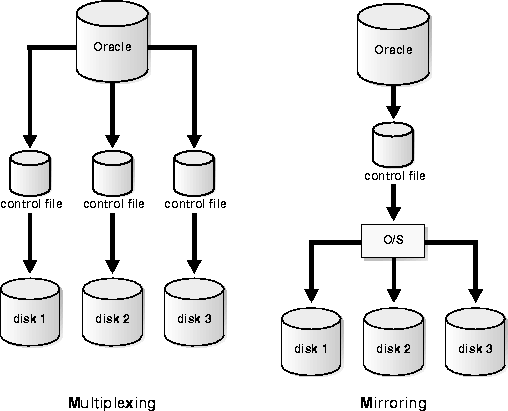
By storing multiple control files for a single database on different disks, you safeguard against a single point of failure. If a single disk containing a control file crashes, the instance fails when Oracle attempts to access the damaged control file.
If the control file is multiplexed, other copies of the current control file are available on different disks. After repairing the bad disk, you can then copy a good control file to the old location and restart the instance easily without having to perform media recovery. If you cannot repair the disk, then you can edit the CONTROL_FILES initialization parameter to specify a new location and copy the good control file copy to this location.
The only disadvantage of multiplexing control files is that operations that update the control files (such as adding a datafile or checkpointing the database) can take slightly longer. This increase in performance overhead is usually insignificant, however, especially for operating systems that can perform multiple, concurrent writes. A slight performance loss does not justify using only a single control file.
Note the following characteristics of multiplexed control files:
init.ora file.
If your operating system supports disk mirroring, then the O/S allows for mirrored disk storage. Mirrored disk storage makes several physical disks look like a single disk to Oracle. Oracle writes the data once, then the O/S writes it to each of the underlying physical disks. Each file is a mirror, i.e., an exact duplicate, of the others.
The advantage of disk mirroring is that if one of the disks becomes unavailable, then the other disk or disks can continue to function without interruption. Therefore, your control file is protected against a single point of failure. Note that if you store your control file on a mirrored disk system, then you only need Oracle to write one active copy of the control file.
Following are scenarios where you may need to recover or re-create the control file:
This procedure assumes that one of the control files specified in the CONTROL_FILES parameter is corrupted, the control file directory is still accessible, and you have a current multiplexed or mirrored copy.
% cp '/disk2/copy/cf.f' '/disk1/oracle/dbs/cf.f';
SQL> STARTUP MOUNT;
This procedure assumes that one of the control files specified in the CONTROL_FILES parameter is inaccessible due to a permanent media failure, and you have a current multiplexed or mirrored copy.
% cp '/disk2/copy/cf.f' '/disk3/copy/cf.f';
init.ora file to replace the bad location with the new location:
CONTROL_FILES = '/oracle/dbs/cf1.f','/disk3/copy/cf.f'
SQL> STARTUP MOUNT;
Perhaps the most crucial structure for recovery operations is the online redo log, which consists of two or more pre-allocated files that store all changes made to the database as they occur. Every instance of an Oracle database has an associated online redo log to protect the database in case of an instance failure.
Each database instance has its own online redo log groups. These online redo log groups, multiplexed or not, are called an instance's thread of online redo. In typical configurations, only one database instance accesses an Oracle database, so only one thread is present. When running the Oracle Parallel Server, however, two or more instances concurrently access a single database; each instance has its own thread.
|
Note: This manual describes how to configure and manage the online redo log when the Oracle Parallel Server is not used. Thus, the thread number can be assumed to be 1 in all discussions and examples of commands. For complete information about configuring the online redo log with the Oracle Parallel Server, see Oracle8i Parallel Server Concepts and Administration. |
See Also: For a conceptual overview of the online redo log, see Oracle8i Concepts. For detailed information about managing the online redo logs, see the Oracle8i Administrator's Guide.
The following data dictionary views contain useful information about the archived redo logs:
For example, the following query displays which online redo log group requires archiving:
SELECT group#, sequence#, status, archived FROM v$log; GROUP# SEQUENCE# STATUS ARC ---------- ---------- ---------------- --- 1 43 CURRENT NO 2 42 INACTIVE YES 2 rows selected.
To display the members for each log group, query the V$LOGFILE view:
SELECT group#, member FROM v$logfile; GROUP# MEMBER -------- -------------------------------------------------------------------------------- 1 /oracle/dbs/t1_log1.f 2 /oracle/dbs/t1_log2.f 2 rows selected.
See Also: For more information on the data dictionary views, see the Oracle8i Reference.
Oracle provides the capability to multiplex an instance's online redo log files to safeguard against damage. When multiplexing online redo log files, LGWR concurrently writes the same information to multiple identical online redo log files, thereby eliminating a single point failure. You can also mirror your redo logs at the O/S level, but in so doing you run the risk of O/S or hardware induced corruption. In most cases, multiplexing of online logs is best.
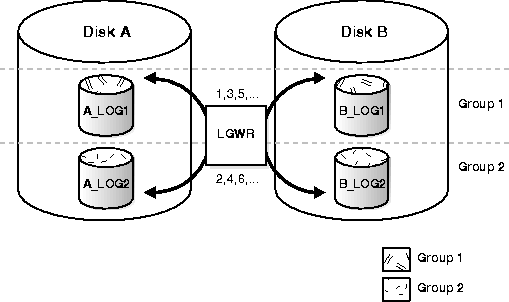
The corresponding online redo log files are called groups. Each online redo log file in a group is called a member. In Figure 2-2, files A_LOG1 and B_LOG1 are both members of Group 1; A_LOG2 and B_LOG2 are both members of Group 2, and so forth. Each member in a group must be the exact same size.
Notice that each member of a group is concurrently active, i.e., concurrently written to by LGWR, as indicated by the identical log sequence numbers assigned by LGWR. In Figure 2-2, first LGWR writes to file A_LOG1 in conjunction with B_LOG1, then A_LOG2 in conjunction with B_LOG2, etc. LGWR never writes concurrently to members of different groups, e.g., to A_LOG1 and B_LOG2.
Whenever LGWR cannot write to a member of a group, Oracle marks that member as stale and writes an error message to the LGWR trace file and to the database's alert log to indicate the problem with the inaccessible files. LGWR reacts differently when certain online redo log members are unavailable, depending on the reason for the unavailability.
See Also: For more information about configuring multiplexed online redo logs, see the Oracle8i Administrator's Guide.
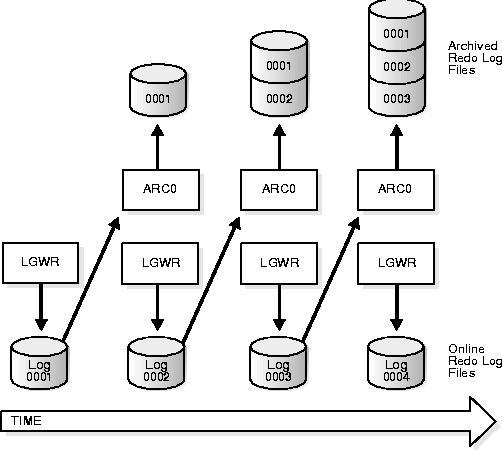
If you run your database in ARCHIVELOG mode, Oracle allows you to save filled groups of online redo log files, known as archived redo logs, to one or more offline destinations. Archiving is the operation of turning online redo logs into archived redo logs.
Use archived logs to:
An archived redo log file is a copy of one of the identical filled members of an online redo log group: it includes the redo entries present in the identical members of a group and also preserves the group's unique log sequence number. For example, if you are multiplexing your online redo logs, and if Group 1 contains member files A_LOG1 and B_LOG1, then the ARCn process will archive one of these identical members. Should A_LOG1 become corrupted, then ARCn can still archive the identical B_LOG1.
If you enable archiving, LGWR is not allowed to re-use and hence overwrite an online redo log group until it has been archived. Therefore, the archived redo log contains a copy of every online redo group created since you enabled archiving. The best way to back up the contents of the current online log is always to archive it, then back up the archived log.
By archiving your online redo logs, you save a copy of every change made to the database since you enabled archiving. If you suffer a media failure, you can recover the lost data by using the archived redo logs.
See Also: For complete procedures for managing archived redo logs as well as for using the LogMiner, see the Oracle8i Administrator's Guide. To learn how to manage a standby database see Chapter 16, "Managing a Standby Database".
This section describes the issues you must consider when choosing to run your database in NOARCHIVELOG or ARCHIVELOG mode, and includes the following topics:
When you run your database in NOARCHIVELOG mode, you disable the archiving of the online redo log. The database's control file indicates that filled groups are not required to be archived. Therefore, after a filled group becomes inactive after a log switch, the group is available for reuse by LGWR.
The choice of whether to enable the archiving of filled groups of online redo log files depends on the availability and reliability requirements of the application running on the database. If you cannot afford to lose any data in your database in the event of a disk failure or operator error, use ARCHIVELOG mode. Note that the archiving of filled online redo log files can require you to perform extra administrative operations.
When you do not archive your logs, you lose all redo contained in a log when Oracle switches into it and begins writing. Running your database in NOARCHIVELOG mode has the following consequences:
Therefore, if you decide to operate a database in NOARCHIVELOG mode, take full database backups at regular, frequent intervals. Otherwise, you may end up in the situation of having to restore an old backup and lose days, weeks, or even months worth of changes.
When you run a database in ARCHIVELOG mode, Oracle requires the online redo log to be archived. You can either perform the archiving manually or enable automatic archiving.
In ARCHIVELOG mode, the database control file indicates that a group of filled online redo log files cannot be used by LGWR until the group is archived. A filled group is immediately available to ARCn after a log switch occurs. After the group has been successfully archived, Oracle can reuse the group.
The archiving of filled groups has these advantages:
See Also: To learn how to enable ARCHIVELOG mode and enable automatic archiving, see the Oracle8i Administrator's Guide. For information about the managed recovery option for standby databases, see "Maintaining the Standby Database in Recovery Mode".
The following data dictionary views contain useful information about the archived redo logs:
For example, the following query displays which online redo log group requires archiving:
SELECT group#, archived FROM sys.v$log; GROUP# ARC ---------- --- 1 YES 2 NO
To see the current archiving mode, query the V$DATABASE view:
SELECT log_mode FROM sys.v$database; LOG_MODE ------------ NOARCHIVELOG
The SQL*Plus statement ARCHIVE LOG LIST also shows archiving information for the connected instance:
ARCHIVE LOG LIST; Database log mode ARCHIVELOG Automatic archival ENABLED Archive destination /oracle/log Oldest online log sequence 30 Next log sequence to archive 31 Current log sequence number 33
This display tells you all the necessary information regarding the archived redo log settings for the current instance:
You must archive all redo log groups with a sequence number equal to or greater than the Next log sequence to archive, yet less than the Current log sequence number. For example, the display above indicates that the online redo log groups with sequence numbers 31 and 32 need to be archived.
See Also: For more information on the data dictionary views, see the Oracle8i Reference.
You can specify a single destination or multiple destinations for the archived redo logs. Oracle recommends archiving your logs to different disks to guard against file corruption and media failure.
Specify the number of locations for your archived logs by setting either of two mutually exclusive sets of initialization parameters:
The first method is to use the LOG_ARCHIVE_DEST_n parameter to specify from one to five different destinations for archival. Each numerically-suffixed parameter uniquely identifies an individual destination, e.g., LOG_ARCHIVE_DEST_1, LOG_ARCHIVE_DEST_2, etc. Use the LOCATION keyword to specify a pathname or the SERVICE keyword to specify a net service name (for use in conjunction with a standby database).
The second method, which allows you to specify a maximum of two locations, is to use the LOG_ARCHIVE_DEST parameter to specify a primary archive destination and the LOG_ARCHIVE_DUPLEX_DEST to determine an optional secondary location. Whenever Oracle archives a redo log, it archives it to every destination specified by either set of parameters.
LOG_ARCHIVE_DEST_1 = 'LOCATION=/disk1/arc/' LOG_ARCHIVE_DEST_2 = 'LOCATION=/disk2/arc/' LOG_ARCHIVE_DEST_3 = 'LOCATION=/disk3/arc/'
%s to include the log sequence number as part of the filename and %t to include the thread number. Use capital letters (%S and %T) to pad the filename to the left with zeros. For example, enter:
LOG_ARCHIVE_FORMAT = arch%t_%s.arc
For example, this setting will result in the following files for log sequence numbers 100-102 on thread 1:
/disk1/arc/arch1_100.arc, /disk1/arc/arch1_101.arc, /disk1/arc/arch1_102.arc, /disk2/arc/arch1_100.arc, /disk2/arc/arch1_101.arc, /disk2/arc/arch1_102.arc, /disk3/arc/arch1_100.arc, /disk3/arc/arch1_101.arc, /disk3/arc/arch1_102.arc
SHUTDOWN IMMEDIATE;
STARTUP;
init.ora file, specifying destinations for the LOG_ARCHIVE_DEST and LOG_ARCHIVE_DUPLEX_DEST parameter. If the database is open, you can also edit the parameter dynamically using the ALTER SYSTEM command.
For example, change the parameter to read:
LOG_ARCHIVE_DEST = '/disk1/arc' LOG_ARCHIVE_DUPLEX_DEST_2 = '/disk2/arc'
%s to include the log sequence number as part of the filename and %t to include the thread number. Use capital letters (%S and %T) to pad the filename to the left with zeroes. If the database is open, you can alter the parameter using the ALTER SYSTEM command.
For example, enter:
LOG_ARCHIVE_FORMAT = arch_%t_%s.arc
For example, this setting will result in the following files for log sequence numbers 300-302 on thread 1:
/disk1/arc/arch_1_300.arc, /disk1/arc/arch_1_301.arc, /disk1/arc/arch_1_302.arc, /disk2/arc/arch_1_300.arc, /disk2/arc/arch_1_301.arc, /disk2/arc/arch_1_302.arc
SHUTDOWN IMMEDIATE;
init.ora file. For example, enter:
STARTUP;
Oracle provides you with a number of useful archiving options. See the Oracle8i Administrator's Guide for a complete account of how to: