Release 8.0
A54652-01
Library |
Product |
Contents |
Index |
| Oracle8(TM)
Server Utilities Release 8.0 A54652-01 |
|
This chapter explains the basic concepts of loading data into an Oracle database with SQL*Loader. This chapter covers the following topics:
Note: If you are using Trusted Oracle, see the Trusted Oracle documentation for information about using the SQL*Loader in that environment.
SQL*Loader loads data from external files into tables in an Oracle database. SQL*Loader has many features of the DB2 Load Utility from IBM, as well as several other features that give it additional power and flexibility. SQL*Loader accepts input data in a variety of formats, can perform filtering (selectively loading records based upon their data values), and can load data into multiple Oracle database tables during the same load session.
Figure 3-1: SQL*Loader Overview shows the basic components of a SQL*Loader session in operation.
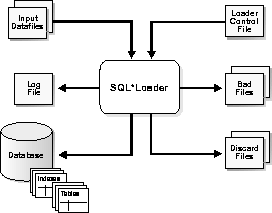
SQL*Loader takes a control file as its input, which describes the load to SQL*Loader. The control file also specifies the input datafile(s).
As it executes, SQL*Loader produces a log file where it writes information about the load. If records are rejected (typically because of incorrect data), it produces a bad file containing the rejected records. It also may produce a discard file containing records that did not meet the specified selection criteria.
SQL*Loader can:
The control file, written in SQL*Loader data definition language (DDL), specifies how to interpret the data, what tables and columns to insert the data into, and may also include input datafile management information.
The data for SQL*Loader to load into an Oracle database must be in files accessible to SQL*Loader (typically a file in a file system, on tape, or a named pipe, depending on the platform). SQL*Loader requires information about the data to be loaded which provides instructions for mapping the input data to columns of a table. These instructions are written in SQL*Loader DDL, typically by the DBA using the system text editor. Following are some of the items that are specified in the SQL*Loader control file:
SQL*Loader DDL is upwardly compatible with the DB2 Load Utility from IBM. Normally you can use a control file for the DB2 Load Utility as a control file for SQL*Loader. See Appendix B, "DB2/DXT User Notes" for differences in syntax.
Some DDL statements are mandatory. They must define where to find the input data. They must also define the correspondence between the input data and the Oracle database tables or indexes.
DDL options are available to describe and manipulate the file data. For example, the instructions can include how to format or filter the data, or how to generate unique ID numbers for a field.
A control file can contain the data itself after the DDL statements, as shown in Case 1 on page 4-5, or in separate files, as shown in Case 2 on page 4-7. Detailed information on creating control files using SQL*Loader DDL is given in "Data Definition Language (DDL) Syntax" on page 5-4.
How the control file is stored depends on how the operating system organizes data. For example, a UNIX environment stores a control file in a file; in MVS environments, the control file can be stored as a member in a partitioned dataset.
The control file must be stored where SQL*Loader can read it.
SQL*Loader data definition language (DDL) is used to specify how SQL*Loader should map the input data it is loading to the columns of a table in an Oracle database. Chapter 5, "SQL*Loader Control File Reference" details the syntax and semantics of SQL*Loader DDL.
DDL statements serve several purposes. Some statements specify input data location or format. Other DDL statements specify which Oracle table to load, mapping of the columns of a table to fields within an input record (field specifications), and specification of the loader input datatype of a field.
A single DDL statement comprises one or more keywords and the arguments and options that modify that keyword's functionality. The following example from a control file contains several statements specifying how SQL*Loader is to load the data from an input datafile into a table in an Oracle database:
LOAD DATA
INFILE 'example.dat'
INTO TABLE emp
(empno POSITION(01:04) INTEGER EXTERNAL,
ename POSITION(06:15) CHAR,
job POSITION(17:25) CHAR,
mgr POSITION(27:30) INTEGER EXTERNAL,
sal POSITION(32:39) DECIMAL EXTERNAL,
comm POSITION(41:48) DECIMAL EXTERNAL,
...
This example shows the keywords LOAD DATA, INFILE, INTO TABLE, and POSITION.
The data for SQL*Loader to load into an Oracle database must be accessible to SQL*Loader, typically in files on disk or tape, or via a named pipe.
SQL*Loader can load data (see "Binary versus Character Data") that has been stored in data fields (see "Data Fields") and records of various formats. The record format may be specified in the control file as a file processing option. SQL*Loader recognizes the following three record formats:
Stream format records are only as long as needed to contain the data. Each physical record ends with a terminating character (or characters on some platforms). The record terminator is typically a newline character (`\n'), or a carriage return followed by a newline ("\r\n"). The record terminator used is platform dependent. Case 3 on page 4-9 shows delimited fields.
In fixed format, the data records all have the same fixed-length format. That is, every record is the same fixed length, and the data fields in each record have the same fixed length, type, and position, as shown in Figure 3-2.
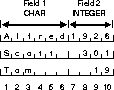
In this figure, each record's bytes 1 through 6 are specified to contain CHAR data while bytes 7 through 10 are specified to contain INTEGER data. The fields are the same size in each record, regardless of the length of the data; the fields are fixed length rather than variable length. The record size also is fixed, at 10 bytes for each record. Case 2 on page 4-7 shows fixed-length records.
Fixed format records make each record exactly the same number of bytes long and each specified field within each record of the specified data type and specified length. The processing option specification in the control file should contain the string "fix n", where n is the size of the record.
The following example control file and data will load the included records, which have a fixed length of 11 characters (10 characters of data plus one newline character for ease of editing the data with the system text editor). It is important to note that SQL*Loader does not require a record terminator for fixed length records, but if a record terminator is present, it must be included in the record length.
load data infile `example.dat' "fix 11" badfile `example.bad' discardfile `example.dsc' discardmax 999 truncate into table example (rown position(1-5), cmnt position(6-10)) example.dat: 00001abcde 00002fghij 00003klmno 00004pqrst 00005uvwxy
Figure 3-3 shows variable length records containing one varying-length character field and one varying-length integer field. In this format, the type of data in each field and record is specified, although the length of each field and record can vary. For example, in each record the first field may be specified to hold a character string, separated by a space from the next field, which may be specified to hold an integer. If the operating system record-terminator character (such as newline) is used to mark where varying-length records end for ease of editing with a text editor, the record size must include the record-terminator. Case 1 on page 4-5 shows delimited fields. For more details on delimited data, see "Specifying Delimiters" on page 5-64.
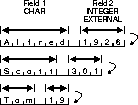
This example uses variable record formats where each record has a variable length n, and n is specified in the first 5 characters of the record. The file processing option should contain the string "var". The following control and data file will load records with variable length records:
load data infile `example.dat' "var" badfile `example.bad' discardfile `example.dsc' discardmax 999 truncate into table example fields terminated by "," optionally enclosed by `"' (rown, cmnt, len) example.dat: 0001500001,a,00015, 0005000002,abcdefghijklmnopqrstuvwxyzABCDEFGHIJ,00050, 0005900003,abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRS,00059, 0005200004,abcdefghijklmnopqrstuvwxyzABCDEFGHIJKL,00052, 0004800005,abcdefghijklmnopqrstuvwxyzABCDEFGH,00048,
Note: For fixed and variable length record formats no assumptions are made about newlines (or other terminator(s)) at the end of each physical record.
Another distinction is the difference between logical and physical records. A record or line in a file (either of fixed length or terminated) is considered a physical record. An operating system-dependent file/record management system, such as DEC's Record Management System (RMS) or IBM's Sequential Access Method (SAM) returns physical records.
A logical record, however, comprises one or more physical records. Sometimes the logical and physical records are equivalent. Such is the case when only a few short columns are being loaded. However, sometimes several physical records must be combined to make one logical record. For example, a single logical record containing twenty-four 10-character columns could comprise three 80-character files; thus three physical records would constitute the single logical record.
SQL*Loader allows you to compose logical records from multiple physical records by using continuation fields. Physical records are combined into a single logical record when some condition of the continuation field is true. You can specify that a logical record be composed of multiple, physical records in the following ways:
Case 4 on page 4-12 uses continuation fields to form one logical record from multiple physical records.
Binary is a "native" datatype. Native datatypes may be implemented differently on different operating systems or on different hardware architectures. For more information on native datatypes, see "Native Datatypes" on page 5-55.
Character data may be included in any record format. For more information on character datatypes, see "Character Datatypes" on page 5-61.
SQL*Loader can load numeric data in binary or character format. Character format is sometimes referred to as numeric external format.
Binary data should not be loaded using stream record format (newline terminated records) as a binary input field may contain a newline character that would incorrectly be considered to be the record delimiter.
Data (binary or character) in records is broken up into fields. Each field can be specified in terms of a specific position and length, or fields' positions and lengths can vary, limited by delimiters, in the following example, commas:
1,1,2,3,5,8,13
Enclosed fields are both preceded and followed by enclosure delimiters, such as the quotation marks in the following example:
"BUNKY"
Figure 3-4 shows the stages in which fields in the datafile are converted into columns in the database during a conventional path load (direct path loads are conceptually similar, but the implementation is different.) The top of the diagram shows a data record containing one or more fields. The bottom shows the destination database column. It is important to understand the intervening steps when using SQL*Loader.
Figure 3-4 depicts the "division of labor" between SQL*Loader and the Oracle8 Server. The field specifications tell SQL*Loader how to interpret the format of the datafile. The Oracle8 Server then converts that data and inserts it into the database columns, using the column datatypes as a guide.
Keep in mind the distinction between a field in a datafile and a column in the database. Remember also that the field datatypes defined in a SQL*Loader control file are not the same as the column datatypes.
SQL*Loader uses the field specifications in the control file to parse the input data and populate the bind arrays which correspond to a SQL insert statement using that data. The insert statement is then executed by the Oracle8 Server to be stored in the table. The Oracle8 Server uses the datatype of the column to convert the data into its final, stored form.
In actuality, there are two conversion steps:
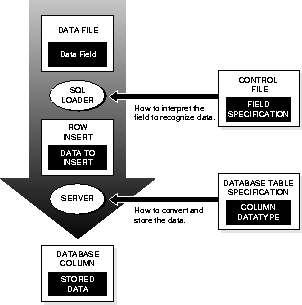
In Figure 3-5, two CHAR fields are defined for a data record. The field specifications are contained in the control file. Note that the control file CHAR specification is not the same as the database CHAR specification. A data field defined as CHAR in the control file merely tells SQL*Loader how to create the row insert. The data could then be inserted into a CHAR, VARCHAR2, NCHAR, NVARCHAR, or even a NUMBER column in the database, with the Oracle8 Server handling any necessary conversions.
By default, SQL*Loader removes trailing spaces from CHAR data before passing it to the database. So, in Figure 3-5, both field A and field B are passed to the database as three-column fields. When the data is inserted into the table, however, there is a difference.
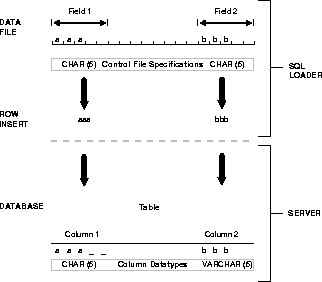
Column A is defined in the database as a fixed-length CHAR column of length 5. So the data (aaa) is left justified in that column, which remains five characters wide. The extra space on the right is padded with blanks. Column B, however, is defined as a varying length field with a maximum length of five characters. The data for that column (bbb) is left-justified as well, but the length remains three characters.
The name of the field tells SQL*Loader what column to insert the data into. Because the first data field has been specified with the name "A" in the control file, SQL*Loader knows to insert the data into column A of the target database table.
It is useful to keep the following points in mind:
Records read from the input file might not be inserted into the database. Figure 3-6 shows the stages at which records may be rejected or discarded.
The bad file contains records rejected, either by SQL*Loader or by Oracle. Some of the possible reasons for rejection are discussed in the next sections.
Records are rejected by SQL*Loader when the input format is invalid. For example, if the second enclosure delimiter is missing, or if a delimited field exceeds its maximum length, SQL*Loader rejects the record. Rejected records are placed in the bad file. For details on how to specify the bad file, see "Specifying the Bad File" on page 5-21
After a record is accepted for processing by SQL*Loader, a row is sent to the Oracle DBMS for insertion. If Oracle determines that the row is valid, then the row is inserted into the database. If not, the record is rejected, and SQL*Loader puts it in the bad file. The row may be rejected, for example, because a key is not unique, because a required field is null, or because the field contains invalid data for the Oracle datatype.
The bad file is written in the same format as the datafile. So rejected data can be loaded with the existing control file after necessary corrections are made.
Case 4 on page 4-12 is an example of the use of a bad file.
As SQL*Loader executes, it may create a file called the discard file. This file is created only when it is needed, and only if you have specified that a discard file should be enabled (see "Specifying the Discard File" on page 5-23). The discard file contains records that were filtered out of the load because they did not match any record-selection criteria specified in the control file.
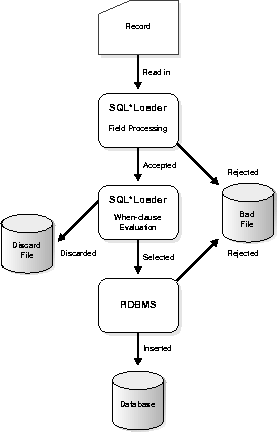
The discard file therefore contains records that were not inserted into any table in the database. You can specify the maximum number of such records that the discard file can accept. Data written to any database table is not written to the discard file.
The discard file is written in the same format as the datafile. The discard data can be loaded with the existing control file, after any necessary editing or correcting.
Case 4 on page 4-12 shows how the discard file is used. For more details, see "Specifying the Discard File" on page 5-23.
When SQL*Loader begins execution, it creates a log file. If it cannot create a log file, execution terminates. The log file contains a detailed summary of the load, including a description of any errors that occurred during the load. For details on the information contained in the log file, see Chapter 7, "SQL*Loader: Log File Reference". All of the case studies in Chapter 4 also contain sample log files.
SQL*Loader provides two methods to load data: Conventional Path, which uses a a SQL INSERT statement with a bind array, and Direct Path, which loads data directly into a database. These modes are discussed below and, more thoroughly, in Chapter 8, "SQL*Loader: Conventional and Direct Path Loads". The tables to be loaded must already exist in the database, SQL*Loader never creates tables, it loads existing tables. Tables may already contain data, or they may be empty.
The following privileges are required for a load:
In addition to the above privileges, you must have write access to all labels you are loading data into a Trusted Oracle database. See the Trusted Oracle Server Administrator's Guide.
During conventional path loads, the input records are parsed according to the field specifications, and each data field is copied to its corresponding bind array. When the bind array is full (or there is no more data left to read), an array insert is executed. For more information on conventional path loads, see "Data Loading Methods" on page 8-2. For information on the bind array, see "Determining the Size of the Bind Array" on page 5-69.
There are no special requirements for tables being loaded via the conventional path.
A direct path load parses the input records according to the field specifications, converts the input field data to the column datatype and builds a column array. The column array is passed to a block formatter which creates data blocks in Oracle database block format. The newly formatted database blocks are written directly to the database bypassing most RDBMS processing. Direct path load is much faster than conventional path load, but entails several restrictions. For more information on the direct path, see "Data Loading Methods" on page 8-2.
A parallel direct path load allows multiple direct path load sessions to concurrently load the same data segments (allows intra-segment parallelism). Use of Parallel Direct Path load entails further restrictions than Direct Path. For more information on the parallel direct path, see "Data Loading Methods" on page 8-2.
The Oracle8 SQL*Loader supports loading partitioned objects in the database. A partitioned object in Oracle8 is a table or index consisting of partitions (pieces) that have been grouped, typically by common logical attributes. For example, sales data for the year 1997 might be partitioned by month. The data for each month is stored in a separate partition of the sales table. Each partition is stored in a separate segment of the database and can have different physical attributes.
Oracle8 SQL*Loader Partitioned Object Support enables the SQL*Loader to load the following:
Oracle8 SQL*Loader supports partitioned objects in all three paths (modes):
|
Copyright © 1997 Oracle Corporation. All Rights Reserved. |
|